Agent 可观测性+eval
Agent 可观测性+eval AI Agent 应用的在线可观测性(Observability)和评估(Evaluation)系统的设计方案。 它的核心目标是替代现有的、部署和维护成本较高的 Langfuse 平台,构建一个更轻量、易维护、且能满足特定需求(如与现有 Agent 代码集成、进行自动化评估)的内部平台。 具体是做什么? 在线可观测性 (Observability/Trace): 目的: 记录和追踪 Agent 应用的运行过程,特别是它与大型语言模型(LLM)的交互以及内部工具调用(Tool Calling)的详细情况。 内容: 收集 Agent 一次完整交互(称为 Trace)以及其中的各个步骤(称为 Span/Observation)的详细信息,包括: Trace: 整个交互的开始/结束时间、用户输入 (input)、Agent 输出 (output)、使用的模型、Token 消耗量、会话 ID (session.id)、Agent 身份 (resource_attributes.service.name) 等。 Span: Agent 内部的特定操作,...
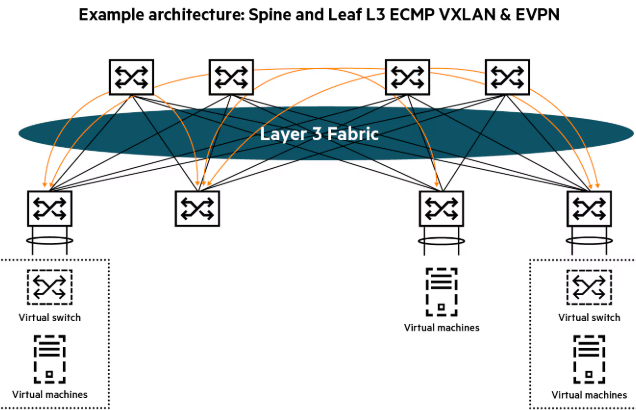
Vxlan && 四表五链
Vxlan && 四表五链 我来为您详细介绍VXLAN和四表五链这两个重要的网络技术概念。 VXLAN (Virtual eXtensible Local Area Network) 基本概念 VXLAN是一种网络虚拟化技术,用于解决传统VLAN的4094个网络标识限制,并实现跨三层网络的二层网络扩展。 核心特点 扩展性强:支持1600万个虚拟网络(24位VNI) 跨三层传输:可以在IP网络上传输二层帧 隧道技术:使用UDP封装实现Overlay网络 报文封装结构 1原始以太网帧 + VXLAN头部 + UDP头部 + IP头部 + 外层以太网帧 主要组件 VTEP (VXLAN Tunnel End Point):隧道端点 VNI (VXLAN Network Identifier):网络标识符 Underlay网络:底层IP网络 Overlay网络:虚拟网络 应用场景 数据中心网络虚拟化 云计算环境租户隔离 跨数据中心的二层网络互联 四表五链 四表 raw表:用于数据包的早期处理,连接跟踪前的处理 mangle表:用于修改数据包的特定部分(TTL...

Volcano调度器
参考:https://zhuanlan.zhihu.com/p/700565336 在 Volcano 系统中,“Job” 和 “Task” 这两个词在 调度器(Scheduler)内部 和 用户/控制器(Controller)层面 代表的是完全不同的东西。 https://volcano.sh/zh/docs/ 丰富的调度策略 Gang Scheduling:确保作业的所有任务同时启动,适用于分布式训练、大数据等场景 Binpack Scheduling:通过任务紧凑分配优化资源利用率 Heterogeneous device scheduling:高效共享GPU异构资源,支持CUDA和MIG两种模式的GPU调度,支持NPU调度 Proportion/Capacity Scheduling:基于队列配额进行资源的共享/抢占/回收 NodeGroup Scheduling:支持节点分组亲和性调度,实现队列与节点组的绑定关系 DRF Scheduling:支持多维度资源的公平调度 SLA Scheduling:基于服务质量的调度保障 Task-topology Schedulin...
NUMA-Aware Scheduling介绍
NUMA-Aware Scheduling https://zhuanlan.zhihu.com/p/713060080 一、 什么是 NUMA? NUMA (Non-Uniform Memory Access,非统一内存访问) 是现代多处理器服务器(尤其是AI服务器)的标准架构。 核心思想:将CPU和内存划分为多个“节点”(Node)。每个节点内的CPU访问本节点的内存速度极快(本地内存访问),而访问其他节点的内存则速度较慢(远程内存访问),存在显著的延迟和带宽差异。 类比:想象一个办公室有多个小组,每个小组有自己的文件柜(本地内存)。找自己组的文件柜拿资料很快,但去别的组借资料就要走过去,花时间。 在一台配备8块GPU和2个CPU插槽的AI服务器上,通常会形成2个或4个NUMA节点。GPU通常通过PCIe总线直连到某个特定的CPU(NUMA节点)上。 二、 为什么需要 NUMA-Aware Scheduling? 在传统的、非NUMA感知的调度下,操作系统或调度器(如K8s原生调度器)可能会做出灾难性的决策: 场景:一个需要大量内存的大模型推理Pod被调度到NUMA ...
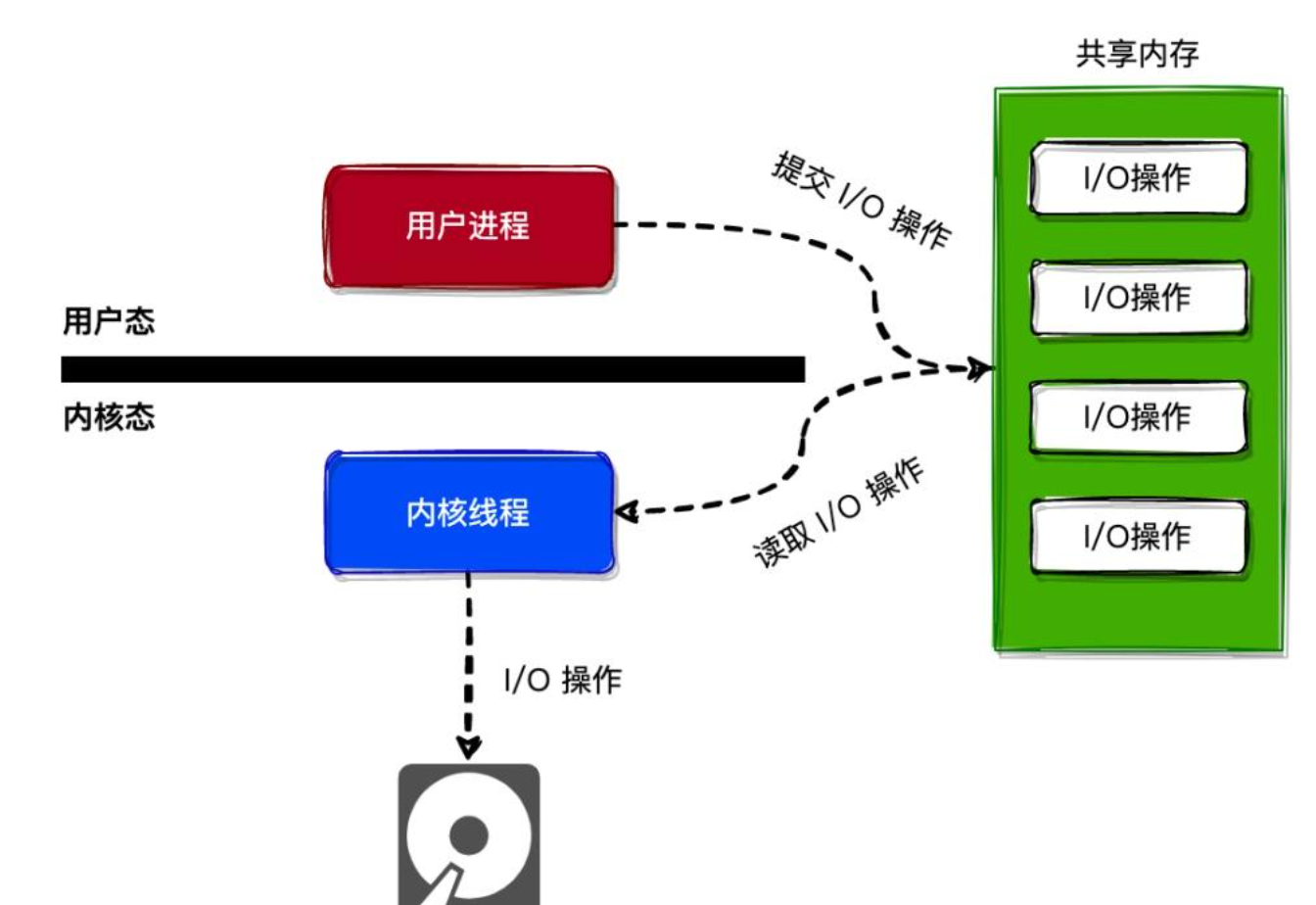
io uring学习
看这个就行 https://arthurchiao.art/blog/intro-to-io-uring-zh/ 阻塞式I/O与非阻塞式I/O 1. 阻塞式 I/O 的问题 在最原始的模型中,应用程序调用 read() 或 write() 时,如果数据没有准备好(例如,网络包未到达,或磁盘数据未从硬盘读入内存),进程就会被挂起(阻塞),直到操作完成。这在高并发场景下是灾难性的,因为一个线程只能处理一个请求。 2. 非阻塞 I/O + I/O 多路复用 (select/poll/epoll) 的“伪异步” 为了解决阻塞问题,引入了非阻塞 I/O 和 I/O 多路复用机制。 工作方式:应用程序将文件描述符(fd)设置为非阻塞模式,然后使用 epoll 等系统调用来“监听”一组 fd。当 epoll_wait() 返回时,它会告诉你哪些 fd 已经“就绪”(ready),即可以进行无阻塞的读写操作。 优点:一个线程可以同时管理成千上万个网络连接,极大地提升了并发能力。这也是 Node.js、Nginx、Redis 等高性能服务的基石。 3. 致命缺点:仅限于“就绪通知”,且不支持 ...
K8s drain和cordon的区别
K8s drain和cordon的区别 Kubernetes中Drain和Cordon的区别 Cordon(封锁节点) 作用 标记节点为不可调度 新的Pod不会被调度到该节点 现有Pod不受影响,继续正常运行 使用场景 12345# 封锁节点kubectl cordon node-name# 解除封锁kubectl uncordon node-name 实际效果 1234节点状态变化:- 调度状态:可调度 → 不可调度- 现有Pod:继续运行- 新Pod:不会调度到此节点 Drain(排空节点) 作用 首先执行Cordon操作(封锁节点) 优雅地驱逐节点上的所有Pod 等待Pod在其他节点上重新启动 节点变为空节点 使用场景 1234567891011# 排空节点(默认行为)kubectl drain node-name# 排空节点并忽略DaemonSetkubectl drain node-name --ignore-daemonsets# 强制删除(不等待优雅终止)kubectl drain node-name --force# 设置优雅终止时间kubectl dri...
k8s helm
K8s Helm 一、 Helm 是什么? Helm 是 Kubernetes 的包管理器。 你可以把它类比为: Linux 世界的 yum 或 apt-get:用来安装、升级、配置和管理软件包。 Node.js 世界的 npm:用来管理项目依赖。 Python 世界的 pip:用来安装和管理库。 只不过,Helm 管理的“包”是 Kubernetes 应用。这个“包”在 Helm 中被称为 Chart。 二、 为什么需要 Helm?—— 解决 K8s 原生部署的痛点 想象一下,你在实习时,需要部署一个包含以下组件的复杂 AI 推理服务: 1 个前端 Web 服务 Deployment 1 个后端 API 服务 Deployment 1 个 Redis 缓存 Deployment + Service 1 个 PostgreSQL 数据库 StatefulSet + Service 1 个 Ingress 资源用于对外暴露服务 10 个 ConfigMap 和 Secret 用于配置管理和密钥注入 1 个 HorizontalPodAutoscaler (HPA) 用于自动...
k8s 探针
k8s 探针 三类探针的作用域 1. 存活探针(Liveness Probe) 作用:判断Pod是否存活 影响:失败时重启Pod 范围:仅影响Pod生命周期 2. 就绪探针(Readiness Probe) 作用:判断Pod是否准备好接收流量 影响:控制Pod是否加入Service的Endpoint 范围:影响Service流量分发 3. 启动探针(Startup Probe) 作用:判断应用是否启动完成 影响:在启动期间禁用其他探针 范围:仅影响Pod启动过程 与Service的关系详解 就绪探针与Service的关联 12345678910apiVersion: v1kind: Servicemetadata: name: my-servicespec: selector: app: my-app # 选择标签匹配的Pod ports: - port: 80 targetPort: 8080 123456789101112131415apiVersion: v1kind: Podmetadata: labels: app: my-ap...
sandbox和container对比
sandbox和container对比 Sandbox 和 Container 的区别 基本概念 Sandbox(沙箱) 定义:一种隔离环境,用于安全地运行程序,限制其对系统资源的访问 目的:提供安全隔离,防止恶意代码影响主机系统 范围:通常针对单个应用程序或进程 Container(容器) 定义:一种轻量级虚拟化技术,将应用程序及其依赖打包在一起 目的:提供一致的运行环境,确保应用在不同环境中行为一致 范围:包含完整的应用程序运行时环境 主要区别对比 特性 Sandbox Container 主要目标 安全隔离 环境一致性 隔离级别 高(安全优先) 中等(资源隔离) 资源开销 极低 低到中等 启动速度 极快 快 包含内容 单个应用/进程 完整运行时环境 技术实现差异 Sandbox 实现方式 1234567// 浏览器沙箱示例(概念性)// 运行在受限环境中const sandboxedCode = ` // 无法访问DOM、网络、文件系统 // 只能执行安全的JavaScript代码 return 42;`; 典型技术: 浏...
容器运行时扩展方案技术解析
容器运行时扩展方案技术解析 基于对某容器运行时扩展项目的代码分析,现从架构层面提炼其核心技术实现,聚焦三大核心能力:运行时接入机制、容器根文件系统云端持久化、Docker-in-Docker 安全实现方案。 1. 如何接入 Containerd 运行时生态 项目通过 Containerd Proxy Plugin 机制 实现与容器运行时的无缝集成,架构清晰、扩展性强。 ▶ 配置层接入 在 containerd 配置中注册名为 custom-snapshotter 的代理插件,通过 Unix Domain Socket 与本地 Agent 通信; 同时注册自定义 Runtime,指向特定二进制执行程序,实现容器生命周期的定制化控制。 ▶ 运行时层实现 Agent 侧:实现标准 gRPC 服务,响应来自 Containerd 的 Snapshotter 接口调用(如 Prepare、Mount、Remove); 存储层封装:采用 Wrapper 模式封装原生 OverlayFS Snapshotter,在不破坏原有逻辑的前提下注入自定义行为(如镜像预处理、元数据记录等); 通...




