使用 Flowise 构建基于私有知识库的智能客服 Agent(图文教程)
使用 Flowise 构建基于私有知识库的智能客服 Agent(图文教程)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Roger-Lv's space!
相关推荐

2025-08-21
一行代码,解锁SFT泛化能力:深度解读DFT如何完胜传统微调
一行代码,解锁SFT泛化能力:深度解读DFT如何完胜传统微调 转自:https://mp.weixin.qq.com/s/XXGxRk-p5LahtqdYNnbKaA 在大型语言模型 (LLM) 的世界里,如何让模型更好地理解并遵循人类的指令,即所谓的“对齐”,始终是核心议题。目前,主流的技术路线分为两条:监督微调(Supervised Fine-Tuning, SFT)和基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF)。 SFT 简单直接,就像教一个学生做题,直接给他看大量的“问题-标准答案”对,让他去模仿。 这种方法易于实现,能让模型快速学会特定任务的“套路”。然而,它的弊病也十分明显——模型容易“死记硬背”,学到的知识很“脆”,泛化能力差,遇到没见过的题型就可能“翻车”。 相比之下,RLHF 更像是请一位教练来指导学生。它不直接给出答案,而是对模型的不同回答给出评分(奖励),让模型在不断的尝试和反馈中,自己探索出更好的策略。但它的问题在于,训练过程极其复杂,需要耗费大量的计算资源,对超参数敏感,且依...

2025-08-21
SFT专攻Pass@k,RL强化Pass@1?
深挖RLVR探索机制:SFT专攻Pass@k,RL强化Pass@1 转自:https://mp.weixin.qq.com/s/QSi580SJ2RFewyFirAe65A 先前的工作已经证明了 RLVR 在实践中的成功,但其背后的根本机制,特别是模型在训练过程中的探索行为,仍有待深入研究。来自中国人民大学高瓴人工智能学院的研究者们发表了一篇题为《From Trial-and-Error to Improvement: A Systematic Analysis of LLM Exploration Mechanisms in RLVR》的技术报告,系统性地研究了RLVR 中的探索机制。 论文题目:From Trial-and-Error to Improvement: A Systematic Analysis of LLM Exploration Mechanisms in RLVR 论文链接:https://arxiv.org/pdf/2508.07534 这篇报告结合了详尽的文献回顾和创新的实证分析,围绕探索空间塑造、熵与性能的相互作用以及强化学习性能优化这三个维度...
2025-08-21
Agentic RL
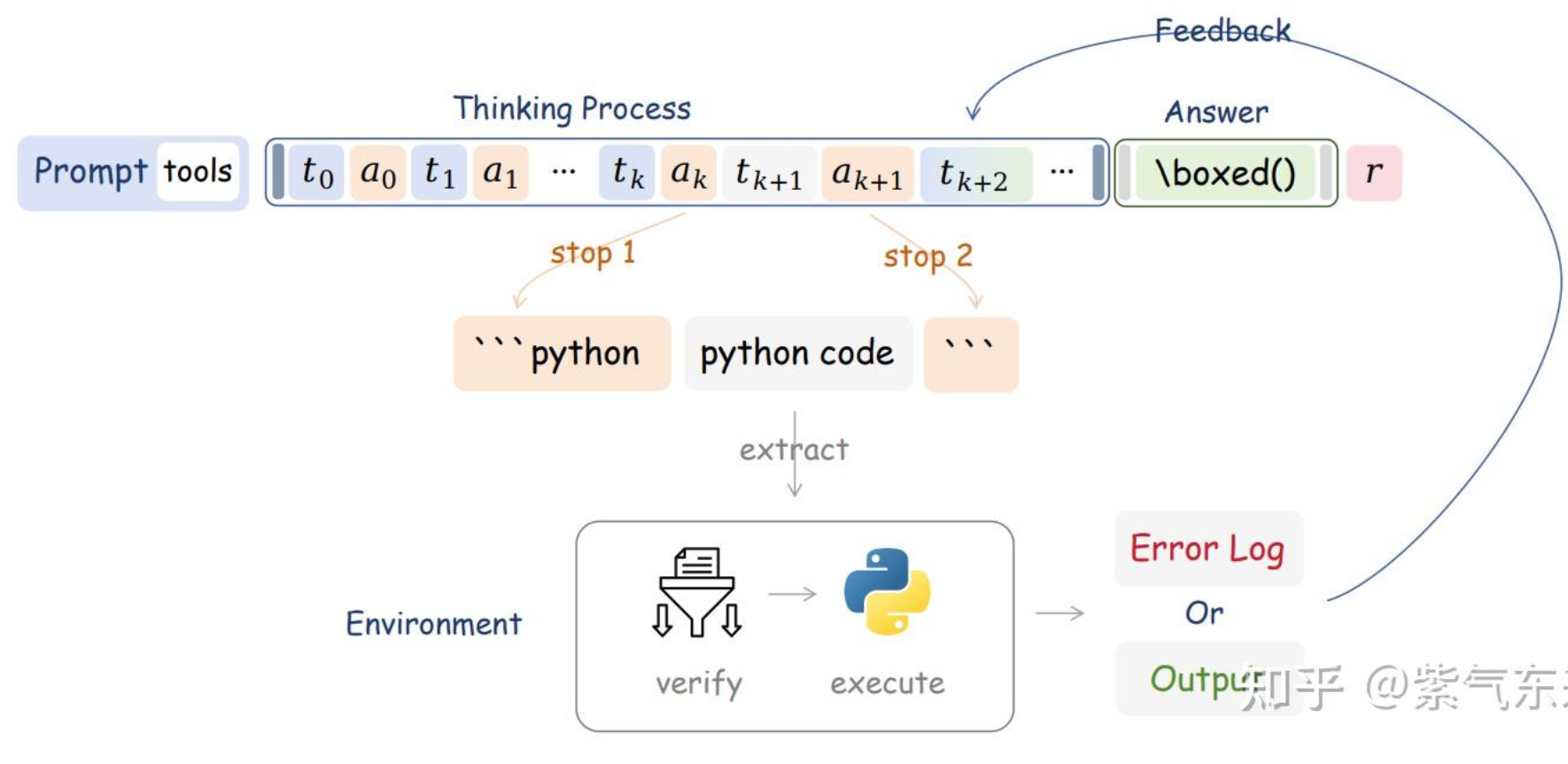
转自:https://zhuanlan.zhihu.com/p/1913905349284591240 通过蒙特卡洛树搜索、过程监督与结果监督、强化学习来提高 LLM 的推理能力,从本质上来说,都是尽可能榨取 LLM 本身的能力,区别可能在于多次尝试、反馈信号、训练方法而已,这类方法可称之为“求诸内”。而由 scaling law 可知,模型的能力是有限的,那么该如何进一步提高LLM在具体问题上的表现呢?近期的答案是,类似 RAG,Multi-Agent 系统,让 LLM 学会使用工具,毕竟人与动物的关键区别也只是“能制造并使用工具”,这种方式则是“求诸外”。那么本篇就以此为中心,重点讨论以下问题: Agentic LLM 的算法逻辑、具体方法与实际表现? RL 如何训练 Agentic LLM,其与 tool using 的 SFT 的差异在哪? Agentic RL 的工程化问题 一、Agentic RL 的算法设计 Agent 和 RL 都并非新鲜事物,而使用 RL 训练基于 LLM 的 agent 则是近期的研究的热点,那么,从算法角度来说,如何理解二者结合的动机、场...
2025-08-27
Megatron & Swift监督微调Qwen3-8B
Megatron & Swift监督微调Qwen3-8B 因为纯Megatron的example中没有对于Qwen的支持,且在社区中没有找到对应封装好的实现。这里Swift已经封装好了对于微调/预训练/强化学习/多种模型/dataloader的各种支持,同时也包含训练结果的图像绘制,可以自主选择Megatron的后端路径(如果要进行修改,就对开源的core_r0.13.0分支的代码进行修改就行,运行时指定该路径)。 平台是选用的无问芯穹的开发机进行实验 注:也可以用llama-factory去做,后续可以试一试 参考 Megatron-SWIFT训练:https://swift.readthedocs.io/zh-cn/latest/Instruction/Megatron-SWIFT%E8%AE%AD%E7%BB%83.html 千问3最佳实践:https://swift.readthedocs.io/zh-cn/latest/BestPractices/Qwen3最佳实践.html#megatron-swift 注意参数:https://swift.readthedo...

2025-09-11
GSPO & Routing Replay
GSPO & Routing Replay 强化学习(RL)中用于大模型(尤其是MoE架构)的策略优化算法演进:GRPO → Routing Replay → GSPO。我们来系统梳理一下: 🧩 背景:GRPO 在 MoE 下的问题 什么是 GRPO? GRPO(Generalized Reward Policy Optimization) 是一种广义的策略优化方法,旨在通过广义优势估计和策略梯度提升训练稳定性与样本效率,常用于语言模型的 RLHF(Reinforcement Learning from Human Feedback)阶段。 什么是 MoE? MoE(Mixture of Experts) 是一种模型架构,通过“路由机制”动态选择部分专家(子网络)处理每个 token,从而在不显著增加计算量的前提下扩展模型容量。 GRPO 在 MoE 下的问题: 新旧策略的差异 新旧策略可能会激活不同的专家,产生结构性偏差,带来噪声。 当从 πθold 更新到 πθ 时,很有可能出现 Router 发生变化,导致新旧策略激活了不同的专家。 例如: 在 πθold...
2025-09-11
Routine:A Structural Planning Framework for LLM Agent System in Enterprise
Routine:A Structural Planning Framework for LLM Agent System in Enterprise 这篇论文的核心价值在于,它没有停留在“让大模型自己想”的层面,而是创造性地提供了一个“剧本”,从根本上解决了企业级Agent落地难的痛点。 我们将从问题根源、解决方案(Routine框架)、系统架构、训练方法、实验结果、核心洞见六个维度,层层递进地进行深度剖析。 PS:在附录提供了prompt、routin的格式、多步工具调用的例子 一、 问题根源:为什么企业级Agent总是“掉链子”? 论文开篇就犀利地指出了当前LLM Agent在企业环境中失败的三大根本原因: “无知” (Lack of Domain-Specific Process Knowledge): 通用大模型(如GPT-4)是“通才”,但不是“专才”。它不了解企业内部错综复杂的业务流程。 后果:模型在规划时会遗漏关键步骤。论文特别指出,最容易被忽略的是权限验证(permission verification)和模型生成(model generation)这类工...
评论


