langfuse交互data和task交互原理
langfuse交互data和task交互原理 langfuse实战:https://zhuanlan.zhihu.com/p/708647880 1. run_experiment 方法核心流程 根据 Langfuse.run_experiment() 方法的实现,data 和 task 的交互过程如下: 12345678910111213def run_experiment( self, *, name: str, run_name: Optional[str] = None, description: Optional[str] = None, data: ExperimentData, # 实验数据 task: TaskFunction, # 任务函数 evaluators: List[EvaluatorFunction] = [], run_evaluators: List[RunEvaluatorFunction] = [], max_concurrency: in...

Manus最佳实践
Manus最佳实践 https://manus.im/zh-cn/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
为什么 RAG 的语义检索在信息压缩下仍然可行?
为什么 RAG 的语义检索在信息压缩下仍然可行? 在 RAG(Retrieval-Augmented Generation)系统中,检索阶段的核心逻辑是这样的: 把用户输入(query)和知识库中的文本块(chunk)都转化为固定维度的 embedding 向量,然后通过相似度计算来找到最相关的文档片段。 然而,这里会出现一个令人疑惑的现象—— 为什么短短几十个字的 query 向量,可以与上千字的文档片段向量放在同一个空间中比较? 毕竟,它们的原始信息量差距巨大,却被压缩到同样维度的 embedding 向量里。 本文将深入分析这个“语义压缩悖论”,解释为什么 RAG 的 embedding 检索机制依然是可行的。 一、RAG 检索的核心机制 RAG 的检索阶段要解决的问题是: “给定一个问题,找到语义上最相关的文本片段。” 实现方式通常如下: 对文档进行切块(chunking) 每个文档被分成 200~1000 字左右的小段。 对文本进行向量化(embedding) 使用预训练模型(如 text-embedding-3-large)将文本转化为 d 维向量。 存入...
🌌 自然语言语义与高维空间中的低维流形:为什么嵌入模型可行?
🌌 自然语言语义与高维空间中的低维流形:为什么嵌入模型可行? 在现代自然语言处理(NLP)中,几乎所有的语义计算都建立在「向量空间假设」之上: 我们把句子、段落或文档映射为高维向量(embedding),并通过计算这些向量之间的相似度来度量语义接近程度。 然而,一个问题常被忽略—— 既然 embedding 通常是 768、1024 或 1536 维的,那么自然语言的语义真的需要这么高维的空间吗? 为什么短短二十个字的句子可以与上千字的文档 chunk 在同一个向量空间中计算相似度? 答案的关键在于:自然语言的语义实际上分布在高维空间中的一个低维流形(low-dimensional manifold)上。 🧠 一、什么是低维流形? 简单来说,**流形(manifold)**是一个局部上看像低维平面的弯曲空间。 想象一下: 一张纸是二维的; 把它卷起来放进三维空间,它依然是“二维流形”; 尽管嵌入在高维空间中,它本质上只有两个自由维度。 同样地,在 1536 维的 embedding 空间中,语言语义并没有自由地充满整个空间,而是集中在某个低维的、弯曲的区域上。 从数...
Rust-just安装
Rust-just安装 在遇到 pip install 无法找到所需包时,尤其是像 rust-just 这样的包,您可以尝试以下几种方法来直接使用二进制文件运行: 方法 1: 查找预构建的二进制文件 GitHub Releases 页面: 访问 rust-just 的 GitHub 页面,通常项目会在其 releases 页面发布预构建的二进制文件。检查是否有适合您系统的版本。 如果有,您可以直接下载二进制文件并运行。 其他二进制发布平台: 例如,某些Rust项目可能会在 Releases on GitHub 或 Rust官方发布页面上提供二进制文件,您可以直接下载相应的版本。 方法 2: 从源代码编译二进制文件 如果没有找到预构建的二进制文件,您可以尝试从源代码编译并运行它。 安装Rust(如果还没有安装的话): 如果您的系统上没有安装Rust,可以通过以下命令安装: 1curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh 然后启动新的shell以加载Ru...

Langfuse 和 ClickHouse 结合使用
Langfuse 和 ClickHouse 结合使用 https://clickhouse.com/blog/langfuse-and-clickhouse-a-new-data-stack-for-modern-llm-applications 这篇博客文章介绍了 Langfuse 和 ClickHouse 结合使用,如何为现代大型语言模型(LLM)应用程序创建一个新的数据栈。文章的主要目标是展示如何通过将 Langfuse 和 ClickHouse 组合,解决 LLM 应用中的数据存储、追踪、监控和分析挑战。 下面是对这篇博客内容的详细总结: 背景介绍 现代的大型语言模型(LLM)在企业中的应用越来越广泛,尤其是自然语言处理(NLP)任务,如智能客服、内容生成、问答系统等。然而,LLM 的应用面临着一系列挑战,尤其是在数据管理方面。 为了高效地支持 LLM 以及它们产生的庞大数据,开发人员需要一个强大的数据栈。Langfuse 和 ClickHouse 的结合旨在为这种需求提供解决方案。 Langfuse 简介 Langfuse 是一个开源的 LLM 监控平台,帮助开发人员...
Intern 快速 Landing+环境搭建
Intern 快速 Landing+环境搭建 item2下载 Mac 终端工具 https://iterm2.com/downloads.html homebrew下载 Mac 软件包管理工具 https://brew.sh/ brew换国内源: 12345export HOMEBREW_INSTALL_FROM_API=1export HOMEBREW_API_DOMAIN="https://mirrors.tuna.tsinghua.edu.cn/homebrew-bottles/api"export HOMEBREW_BOTTLE_DOMAIN="https://mirrors.tuna.tsinghua.edu.cn/homebrew-bottles"export HOMEBREW_BREW_GIT_REMOTE="https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/brew.git"export HOMEBREW_CORE_GIT_REMOTE="htt...
Autogen多智能体交接
Autogen多智能体交接 https://microsoft.github.io/autogen/stable//user-guide/core-user-guide/design-patterns/handoffs.html AutoGen 在多智能体系统里是 如何实现“任务从一个代理(agent)转移/交接(handoff)给另一个代理” 的? 文档中“交接(handoff)”场景的总体结构 一个用户发起对话,会话是由多个 agent + 人类 agent 组成的团队处理。例子里有 “分类代理”(Triage Agent)、“退款代理” / “问题和修复代理”(Issues & Repairs Agent)、“销售代理”、“人类代理”。 起始 agent(classification / triage)负责判断用户意图,然后决定任务应交给哪一个子 agent,比如是销售还是退款问题等。 Agent 可以自己处理任务(调用某些功能/工具)也可以认定自己能力不够,就通过一个“委托工具”(delegate tool)将任务交给另一个 agent。 “交接”的关键机...

GPU资源共享/抢占
GPU共享的整体架构 这个项目是一个Kubernetes GPU共享调度系统,通过两种类型的pod实现GPU资源共享: 1. Shadow Pod(影子Pod) 作用:占用物理GPU资源,作为GPU的实际持有者 特征:运行一个简单的sleep容器,不执行实际计算任务 创建时机:当quota资源不足时自动创建 生命周期:由shadow controller管理,根据使用情况自动创建和删除 2. Share Pod(共享Pod) 作用:实际执行计算任务的pod,通过device plugin共享shadow pod的GPU资源 特征:使用虚拟GPU设备,通过时间片或空间分割方式共享物理GPU 资源请求:请求共享GPU资源(如mizar.share.gpu.2表示2路共享) 核心逻辑链路 1. 配额管理(Quota Controller) 监控quota资源状态,计算shadow resource需求 维护shadow pod与物理GPU的映射关系 处理shadow pod的创建和删除逻辑 2. Shadow Pod管理(Shadow Controller) 创建逻辑:当...
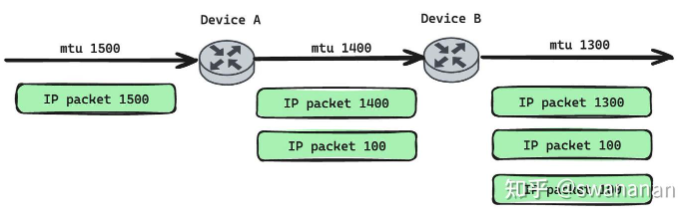
MTU探测
MTU探测 https://zhuanlan.zhihu.com/p/1939977507236450569 PMTUD 是一种用于确定从源主机到目标主机的整个网络路径上 MTU(Maximum Transmission Unit,最大传输单元)大小的机制。它的主要目的是避免 IP 分片,因为分片会消耗额外的计算资源并可能增加丢包的风险。 核心思想: PMTUD 利用 ICMP(Internet Control Message Protocol)的“Fragmentation Needed and DF set”(需要分片但 DF 位已设置)消息来工作。源主机发送一个设置了“Don’t Fragment”(DF)标志位的数据包,如果路径上的某个路由器发现这个数据包太大而无法转发,并且 DF 位被设置,它就不能进行分片,而是丢弃该数据包并向源主机发送一个 ICMP 错误消息,告知源主机路径 MTU 的信息。 详细过程: 初始化: 源主机(Host A)想要向目标主机(Host B)发送一个较大的 IP 数据包。 Host A 会维护一个“路径 MTU 缓存”,记录它所知道的到...




