Agent八股
Agent八股 模板1 八股:Encoder与decoder的中Attention区别? 答案:https://zhuanlan.zhihu.com/p/26252050300 https://www.zhihu.com/question/588325646/answer/1981416261771604279 八股:Attention如何计算?为什么除以根号下Dk?mask attention是如何实现的? 你的问题涉及 Transformer 模型中 Attention 机制的三个关键点: Attention 的计算方式 为什么除以 (\sqrt{d_k}) Masked Attention 的实现方式 下面逐一解释: Attention 如何计算?(以 Scaled Dot-Product Attention 为例) 标准的 Scaled Dot-Product Attention 公式如下: \[ \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) V ...
DeepResearch智能体方案
DeepResearch智能体方案 通义dr的解读: https://zhuanlan.zhihu.com/p/1953262318352863784 关键在于训练一个专门的模型,为DR而生。 为什么通义DeepResearch不需要 chunk?RAG正在被Agent改写 https://zhuanlan.zhihu.com/p/1968442243783294997 CPT->SFT->RL DeepResearch 之所以不需要传统 RAG 的Chunking,是因为它从根本上改变了范式。 传统 RAG 是一个静态系统,模型是被动缝合你喂给它的碎纸片 (Chunks)。 DeepResearch 是一个动态系统。模型是研究员,它主动去获取完整的信息(网页/文档),然后利用IterResearch范式(压缩笔记)来管理自己的认知焦点,再利用RL来优化自己的研究策略。 所以,RAG 不会被取代,而是正在被 DeepResearch 这样的 Agent 框架吸收和升维——检索不再是一个外部模块,而是 Agent 工具箱里一个最基础的动作而已。 JINA 看jina...
LangGraph 八股
LangGraph 八股 官方文档:https://docs.langchain.com/oss/python/releases/langchain-v1 https://zhuanlan.zhihu.com/p/1914230995034564014 langchain&laanggraph 1.0: https://zhuanlan.zhihu.com/p/1966891862062265076 https://zhuanlan.zhihu.com/p/1968427472388335014 langchain新特性: 全新create_agent接口:默认运行在 LangGraph 引擎之上。 中间件定义了一组钩子,允许您自定义代理循环中的行为,从而实现代理采取的每个步骤的细粒度控制;支持自定义中间件 ,这些中间件可以连接到代理循环中的多个点。 钩子函数 触发时机 应用场景 before_agent 在调用代理之前 加载记忆数据、验证输入 before_model 在每次大模型调用之前 更新提示词、精简消息历史 wrap_mod...
多智能体系统工作前沿汇总
多智能体系统工作前沿汇总 https://zhuanlan.zhihu.com/p/1950212759796049358 AgentDropout:Dynamic Agent Elimination for Token-Efficient, High-Performance Collaboration(ACL 2025) 这篇论文提出在多轮对话与推理过程中动态“淘汰”冗余 agent 与通信边,从而压缩推理成本。该机制在不同任务中节省了约 20% 以上的 token 使用,同时保持甚至提升性能,并展现良好的迁移性。 链接:https://arxiv.org/abs/2503.18891 。 上面这篇还挺有意思 Chain of Agents: Large Language Models Collaborating on Long-Context Tasks(2025) 这篇论文提出了 Chain-of-Agents (CoA) 框架,把长文本任务拆分给一系列顺序衔接的智能体处理,每个智能体只需关注自己的一小块内容,并通过通信单元传递关键信息,最后由管理智能体整合输出。这样既能避...

多模态RAG检索
多模态RAG检索 ColPali和DSE解读:https://zhuanlan.zhihu.com/p/826088920 colbert模型(ColPali):在视觉encoder,也是利用多模态的视觉大模型来生成图片端的向量,但不仅仅只生成单个向量。而是利用VIT的patch embedding,来生成多个向量。直觉上确实是会有收益,因为一整页的pdf,你就压缩在一个固定维度的向量中,那肯定有信息损失,而且以patch为单位生成embedding,真的很make sensen,比文本的colbert都make sense。 实践:https://zhuanlan.zhihu.com/p/1975243477060167021 加载所有文档,使用 http://unstructured.io 等文档加载器(document loader)提取文本块、图像和表格。 如需转换,*将 HTML 表格转为 Markdown 格式* —— 这种格式对大型语言模型(LLM)通常非常有效。 将每个文本块、图像和表格传入 GPT-4o 等多模态大型语言模型(multimodal LLM)...
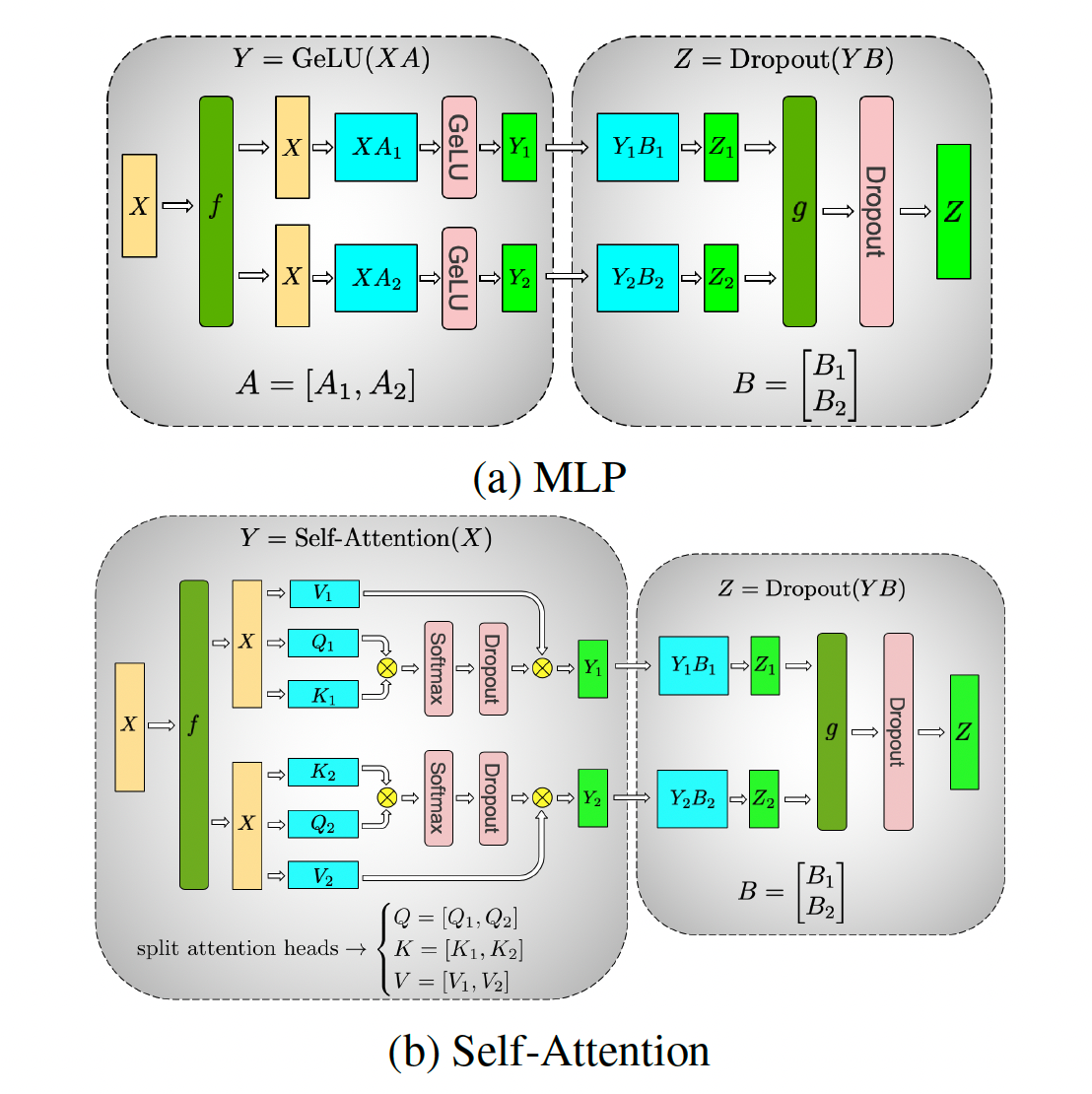
深入理解Megatron-LM
深入理解Megatron-LM 基础知识:https://zhuanlan.zhihu.com/p/650234985 原理介绍:https://zhuanlan.zhihu.com/p/650383289 megatron中的pipeline并行https://zhuanlan.zhihu.com/p/432969288 代码结构:https://zhuanlan.zhihu.com/p/650237820 并行设置:https://zhuanlan.zhihu.com/p/650500590 张量并行:https://zhuanlan.zhihu.com/p/650237833 流水线刷新机制:https://zhuanlan.zhihu.com/p/651341660 1F1B流水线并行负载不均衡:https://zhuanlan.zhihu.com/p/693425934 进程模型: 当你使用 torch.distributed.launch 或 torchrun 启动训练时,会启动 N 个独立的 Python 进程(N = GPU 数量),每个进程绑定到一个 GPU,...
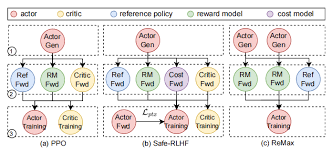
verl框架学习
verl框架学习 https://zhuanlan.zhihu.com/p/24682036412 https://zhuanlan.zhihu.com/p/27676081245 verl资源管理:https://zhuanlan.zhihu.com/p/1943781624954192493 核心概念: Ray: Ray 是一个分布式计算框架,现在流行的RL框架如VeRL和OpenRLHF都依托Ray管理RL中复杂的Roles(比如PPO需要四个模型)和分配资源。以下是一些核心的概念: Ray Actor:有状态的远程计算任务,一般是被ray.remote装饰器装饰的Python类,运行时是一个进程(和PPO等Actor-Critic算法的Actor不要混淆了); Ray Task:无状态的远程计算任务,一般是被ray.remote装饰器装饰的Python函数,创建的局部变量仅在当前可见,对于任务的提交者不可见,因此可以视作无状态; 资源管理:Ray可以自动管理CPU、GPU、Mem等资源的分配(通过ray.remote装饰器或者启动的options参数可以指定指定的ray...
Agent框架集成多模态能力底层实现
Agent框架集成多模态能力底层实现 该项目处理多模态RAG返回图片的完整流程: 架构概述 该项目采用分层架构处理多模态RAG: 前端接口层:通过schema.py中的ImageContent和ImageUrl模型支持base64和HTTPS两种图片URL格式 RAG核心层:rag.py中的RagClient提供统一的向量检索接口 多模态嵌入层:multi_model.py中的AliyunEmbeddings使用阿里云DashScope的多模态嵌入API 数据存储层:使用Qdrant向量数据库存储图片和文本的嵌入向量 图片处理流程 1. 图片存储阶段 在feishu-crawler子项目中,图片处理流程如下: 图片下载:DownloadImageTransform从飞书下载图片到本地文件系统 图片摘要生成:GenerateImageSummaryTransform使用VLLM模型为图片生成文字描述 多模态嵌入:EmbedImageTransform调用MultiModelEmbedder生成图片+文字的联合嵌入向量 向量存储:将base64编码的图片数据、文字描述和嵌入向量...
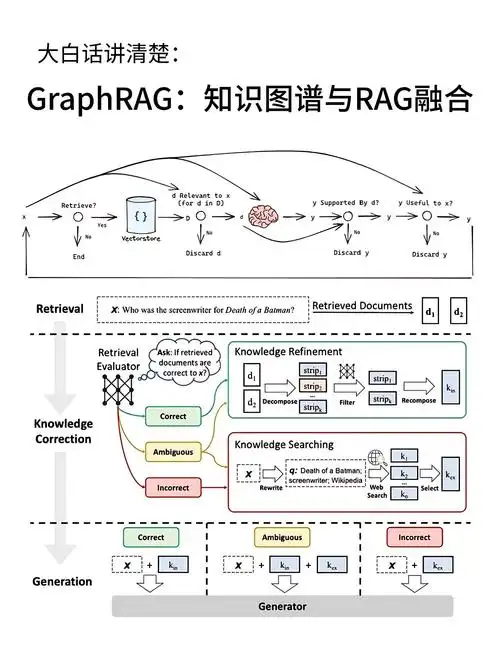
多路召回+Graph RAG调研和实践
多路召回+Graph RAG调研和实践 简介 多路召回简单来说就是指的通过多种途径——包括从已有的Qdrant、Memgraph甚至是web上等去拿到与query相关的上下文信息的过程。 Graph RAG这里有一些文档可以看看: memgraph+spacy构建知识图谱:https://memgraph.com/blog/extract-entities-build-knowledge-graph-memgraph-spacy 从知识图谱到 GraphRAG:探索属性图的构建和复杂的数据检索实践:https://cloud.tencent.com/developer/article/2441475 利用 LlamaIndex 和 Memgraph 构建知识图谱并查询:https://www.llamaindex.ai/blog/constructing-a-knowledge-graph-with-llamaindex-and-memgraph 一篇RAG+知识图谱的博客:https://qiankunli.github.io/2024/07/12/llm_graph.htm...
LangGraph 中 checkpoint_id 的更新时机:每个对话轮次还是每个节点流转?
LangGraph 中 checkpoint_id 的更新时机:每个对话轮次还是每个节点流转? 在使用 LangGraph 构建多轮对话或工作流时,我们经常会遇到 checkpoint(检查点)的概念。每个检查点都有一个唯一的 checkpoint_id,用于标识该次状态快照。一个常见的问题是:checkpoint_id 是在每个对话轮次更新一次,还是在节点(node)之间流转时就会更新一次? 本文将通过分析 LangGraph 源码(基于 langgraph==0.2.0 左右版本)来回答这个问题,并解释其背后的设计逻辑。 1. checkpoint_id 是如何生成的? 首先,我们来看 checkpoint_id 的生成方式。在 langgraph/checkpoint/base/__init__.py 中,有一个 create_checkpoint 函数: 12345678910111213141516171819def create_checkpoint( checkpoint: Checkpoint, channels: Mapping[str, BaseC...


