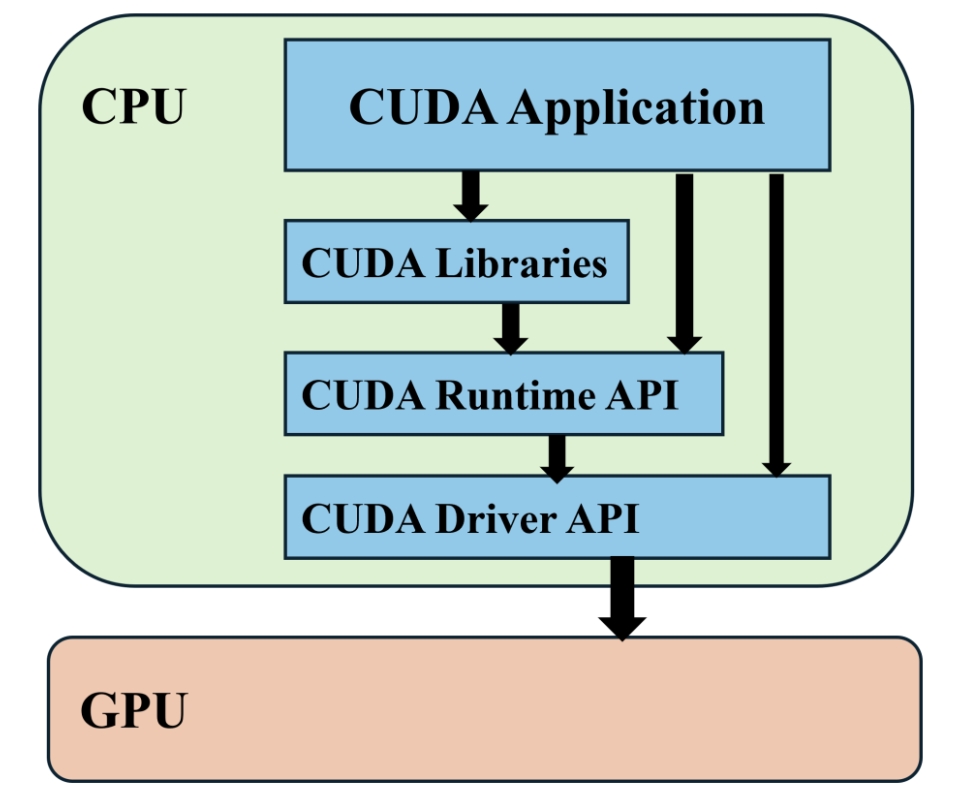
NVIDIA device plugin for Kubernetes原理分析
NVIDIA device plugin for Kubernetes原理分析 什么是 Device Plugin K8s 原生并没有支持第三方设备厂商的物理设备资源,因此 Device Plugins 给第三方设备厂商提供了相关接口,可以让他们的物理设备资源以 Extended Resources 提供给底层的容器。 当 device plugin 功能启动后,可以令 kubelet 开放 Register 的 gRPC 服务,device plugin 就可以通过这个服务向 kubelet 进行注册,注册成功后 device plugin 就进入了 Serving 模式,提供前面提到的 gRPC 接口调用服务,kubelet 也就可以通过调用 Listandwatch、Allocate 等方法对设备进行操作,可以用下图来描述单一节点上这一过程: 下面以 NVIDIA k8s-device-plugin 为例简单讲讲这一过程。 注册服务 先看 gRPC 注册部分,下面的函数用于启动一个 gRPC 服务器并在 kubelet 中注册 1234567891011121314151...

一种基于经验的动态资源调度:StraightLine:An End-to-End Resource-Aware Scheduler for Machine Learning Application Requests
StraightLine: An End-to-End Resource-Aware Scheduler for Machine Learning Application Requests 摘要: 提出了一个端到端的资源感知调度器,用于在混合基础设施中调度机器学习应用请求的最优资源。 关键词: 机器学习部署、异构资源、资源放置、容器化、无服务器计算。 主要内容: ML应用的生命周期包括模型开发和模型部署两个阶段。 传统ML系统通常只关注生命周期中的一个特定阶段或阶段。 StraightLine通过一个基于经验的动态放置算法,根据请求的独特特征(如请求频率、输入数据大小和数据分布)智能地放置请求。 包括三个层次:模型开发抽象、多种实现部署、实时资源调度。 模型容器化: 使用NVIDIA-Docker实现模型开发的容器化。 为模型训练构建了强大的NVIDIA-Docker,为模型验证构建了轻量级的NVIDIA-Docker。 深度学习docker环境配置之nvidia-docker安装使用_nvidia docker-CSDN博客 容器定制: 根据不同的压缩ML模...

自然辩证法课程知识点
😀自然辩证法课程知识点总结 同步连接:网页版 世界科技体制的形成和中国科技体制的变革 定义: 科技体制: 组织结构和运行机制: 科技体制是指科学技术的组织设置及其相互之间的组织性制约关系; 其机制是指科学技术在内外动力作用下产生动态过程的各相关因素互相制约的一般模式 原则: 科技体制化是科学技术产物发展的必然产物 科技体制的形成与建设过程充分显示了社会对科技发展的或促进或制约的过程 中国科技体制 是移植国外的,而非内生的 其有深刻的历史合理性与必然性 1. 世界科学技术 从小科学到大科学 哥白尼天体运行论 牛顿-自然哲学中的数学原理 爱因斯坦-相对论 近代科学体系的建立: 两个特点:逻辑演绎+实验验证 小科学特点: 个体行为(个人独立完成,无经费) 追求知识(无实际效益) 自由探索(兴趣使然,无具体目标) 大科学:大目标,大投入,大设备,大协作,大效益 曼哈顿就工程(物理),阿波罗计划,国际空间站等 中国神六,嫦娥卫星:万人一杆枪 中国:从陈景润到王选、袁隆平 2. 世界科技体制的形成 古希腊: 毕达哥拉斯,“伦理-政治...
AI Infra基础
AI Infra基础 AI Infra 基础知识 - 一文介绍并行计算、费林分类法和 CUDA 基本概念 - 大模型知识库|大模型训练|开箱即用的企业大模型应用平台|智能体开发|53AI
AI资源调度
AI资源调度 100道k8s面试题:https://zhuanlan.zhihu.com/p/721588398 [云原生 AI 的资源调度和 AI 工作流引擎设计分享_paddleflow-CSDN博客](https://blog.csdn.net/lihui49/article/details/129260286?ops_request_misc={"request_id"%3A"81C8FAB8-41BA-4FDC-A5E5-B7EF5F69A9D0"%2C"scm"%3A"20140713.130102334.."}&request_id=81C8FAB8-41BA-4FDC-A5E5-B7EF5F69A9D0&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-3-129260286-null-null.142^v100^pc_search_re...

Golang基础学习
Golang基础学习 Go 语言教程 | 菜鸟教程 (it028.com) goland开发环境搭建及运行第一个go程序HelloWorld_goland helloworld-CSDN博客 基础语法 Go 语言教程 | 菜鸟教程 (it028.com) 语句后不需要; {不能单独一列 switch 注意switch支持多值匹配: 12345678910111213141516171819package mainimport ( "fmt")func main() { day := "Thursday" switch day { case "Monday", "Tuesday", "Wednesday", "Thursday", "Friday": fmt.Println(day, "is a weekday.") case "Saturd...

Pytorch框架学习
Pytorch框架学习 [conda常用命令汇总_conda info-CSDN博客](https://blog.csdn.net/raelum/article/details/125109819?ops_request_misc={"request_id"%3A"FDEA5F49-A7E0-4BF5-99F9-B75BE8373F14"%2C"scm"%3A"20140713.130102334.."}&request_id=FDEA5F49-A7E0-4BF5-99F9-B75BE8373F14&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-2-125109819-null-null.142^v100^pc_search_result_base8&utm_term=conda 命令&spm=1018.2226.3001.4187) ...
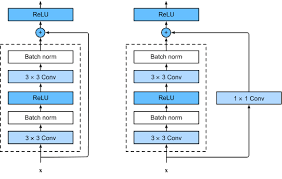
ResNet
ResNet 视频:ResNet论文逐段精读【论文精读】_哔哩哔哩_bilibili 【深度学习】ResNet网络讲解-CSDN博客 深度学习基础学习-残差-CSDN博客 为什么要使用3×3卷积?& 11卷积的作用是什么?& 对ResNet结构的一些理解_33卷积-CSDN博客 残差、方差、偏差、MSE均方误差、Bagging、Boosting、过拟合欠拟合和交叉验证-CSDN博客 深度学习——残差网络(ResNet)原理讲解+代码(pytroch)_残差神经网络-CSDN博客 :star: 快速理解卷积神经网络的输入输出尺寸问题_卷积神经网络输入和输出-CSDN博客 CNN基础知识——卷积(Convolution)、填充(Padding)、步长(Stride) - 知乎 (zhihu.com) 正态及标准正态分布-CSDN博客 [ 图像分类 ] 经典网络模型4——ResNet 详解与复现-CSDN博客 现象:更深的网络结构反而训练误差和测试误差都提升了!(梯度消失/梯度爆炸) 这里和overfiiting的区别是:过拟合是训练集上表现好,但测试集表现差,这里的...
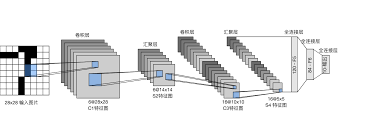
CNN笔记
CNN笔记 CNN笔记:通俗理解卷积神经网络_cnn卷积神经网络-CSDN博客 Zero Padding(零填充)——在卷积神经网络中的作用?-CSDN博客 一句话CNN:如何理解padding的作用和算法 - 知乎 (zhihu.com) 为什么需要随机裁剪:随机裁剪相当于建立每个因子特征与相应类别的权重关系,减弱背景(或噪音)因子的权重,且使模型面对缺失值不敏感,也就可以产生更好的学习效果,增加模型稳定性。
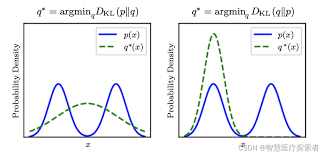
KL散度详解
KL散度 进阶详解KL散度 - 知乎 (zhihu.com)




