
Shall We Pretrain Autoregressive Language Models with Retrieval
Shall We Pretrain Autoregressive Language Models with Retrieval? A Comprehensive Study 解析论文《Shall We Pretrain Autoregressive Language Models with Retrieval? A Comprehensive Study》的主要内容 本文由 Boxin Wang 等人(主要来自 NVIDIA)撰写,旨在解决一个核心问题:在预训练自回归语言模型(如 GPT)时,是否应融入检索机制? 通过全面研究检索增强模型 RETRO 及其变体 RETRO++,论文比较了 RETRO 与标准 GPT、微调阶段融入检索的 GPT(如 RAG)和推理阶段融入检索的 GPT(如 KNN-LM)的性能差异。研究基于大规模预训练(参数规模从 148M 到 9.5B,检索数据库包含 330B tokens),并覆盖文本生成质量(text generation quality)、下游任务准确性和毒性等多个维度。以下是详细解析,结构分为六个部分,确保内容逻辑清晰、层次丰富。 1...
漫谈 LLM 解码策略-采样策略 贪心解码、随机采样、Top-K 采样、Top-P 采样、核采样 和搜索策略Beam Search
漫谈 LLM 解码策略:采样策略(贪心解码、随机采样、Top-K 采样、Top-P 采样、核采样)和搜索策略( Beam Search) 转载:https://zhuanlan.zhihu.com/p/29031912458 一. 前言 解码策略是大语言模型(Large Language Model, LLM)生成最终文本的关键环节,它直接影响文本的流畅性、连贯性和多样性。为了生成尽可能高质量的文本,研究者们发挥自己的聪明才智设计了各种各样的解码策略,以在准确性和创造行之间取得平衡。本文将系统梳理并总结常见的解码策略,涵盖**贪心解码(Greedy Decoding)、随机采样(Random Sampling)、Top-K 采样、Top-P 采样(核采样)以及束搜索(Beam Search)**等策略,帮助读者理解各策略的工作原理,并探讨它们各自的优缺点。 注:笔者水平有限,若有描述不当之处,敬请大家批评指正,与大家共同进步! 二. 什么是解码(Decoding)? 在大语言模型(如 Deepseek、GPT-4o)中,解码指的是模型在生成文本时,按照一定规则逐步选取下一个tok...
基于 Ray 的分离式架构:veRL、OpenRLHF 工程设计
基于 Ray 的分离式架构:veRL、OpenRLHF 工程设计 转载:https://zhuanlan.zhihu.com/p/26833089345 在 RL、蒸馏等任务中需要多个模型协同完成计算、数据通信、流程控制等工作。例如 PPO 及各类衍生算法中,就需要管理 Actor、Rollout、Ref、Critic、Reward 等最多 5 类模块,每类模块还承担着 train、eval、generate 其中的一种或多种职责,而蒸馏任务中也存在着多组 Teacher 和多组 Student 共同蒸馏的场景。 如果我们仍然采用 Pretrain、SFT 训练这种基于单脚本多进程的运行模式(通过 deepspeed、torchrun 等命令启动任务),是难以实现灵活的任务调度和资源分配策略的。而 Ray 提供的 remote 异步调用和 Actor 抽象,可以让每个模块有独立的运行单元和任务处理逻辑,这种分离式架构使之天然适配多模型之间的频繁交互和协同工作的场景。 这篇文章以当今最为流行的两个 RL 框架 veRL 和 OpenRLHF 为例,从工程角度分析这两个框架的特点和优...
MCP-Zero:LLM智能体主动工具发现的新范式
MCP-Zero:LLM智能体主动工具发现的新范式 转自:https://zhuanlan.zhihu.com/p/1928760473630798292 引言 大语言模型(LLMs)在处理复杂任务时,通常需要借助外部工具来扩展其能力范围。然而,当前 LLM 智能体与工具集成的主流范式存在显著局限性:它们往往将预定义的工具模式注入到系统提示中,导致模型扮演被动选择者的角色,而非主动发现所需能力。这种方法不仅造成了巨大的上下文开销,也限制了模型的决策自主性。 为了解决这些问题,本文引入了 MCP-Zero,一个旨在恢复 LLM 智能体工具发现自主性的主动框架。MCP-Zero 的核心思想是,智能体能够主动识别自身能力差距,并按需请求特定工具,从而将自身从大规模检索器转变为真正的自主智能体。该框架通过三大核心机制运行:主动工具请求、分层语义路由和迭代能力扩展。这些机制共同作用,使得 MCP-Zero 能够在最小化上下文开销和保持高准确性的前提下,动态构建多步工具链。 图:LLM 智能体的工具选择范例比较。(a) 基于系统提示的方法将所有 MCP 工具模式注入上下文,导致提示过长,...
Alita:Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution
Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution 参考:https://zhuanlan.zhihu.com/p/1915741399036438446 Alita 提出了一种通过最小预定义实现最大自演化的通用智能体范式,摒弃传统 LLM agent 对手工设计工具和复杂流程的依赖,仅以一个内置 Web Agent 为核心,借助开放网络自主生成、测试并封装可重用的任务工具(MCPs),展现出无需人工干预即可构建复杂推理能力的潜力;在多个高难度基准任务中即便搭配弱模型也能优于现有方法,同时具备高度的工具迁移性与知识蒸馏价值,为智能体系统的可扩展性与共享生态奠定基础。 Introduc...
Faiss入门及应用经验记录
Faiss入门及应用经验记录 转载:https://zhuanlan.zhihu.com/p/357414033 1. 什么是Faiss? Faiss的全称是Facebook AI Similarity Search,是FaceBook的AI团队针对大规模相似度检索问题开发的一个工具,使用C++编写,有python接口,对10亿量级的索引可以做到毫秒级检索的性能。 简单来说,Faiss的工作,就是把我们自己的候选向量集封装成一个index数据库,它可以加速我们检索相似向量TopK的过程,其中有些索引还支持GPU构建,可谓是强上加强。 2. Faiss简单上手 首先,Faiss检索相似向量TopK的工程基本都能分为三步: 得到向量库; 用faiss 构建index,并将向量添加到index中; 用faiss index 检索。 好吧…这貌似和废话没啥区别,参考把大象装冰箱需要几个步骤。本段代码摘自Faiss官方文档,很清晰,基本所有的index构建流程都遵循这个步骤。 第一步,得到向量: 123456789import numpy as npd = 64 ...
TD lamda和GAE
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读 参考:https://zhuanlan.zhihu.com/p/677607581
异步RL框架AReaL
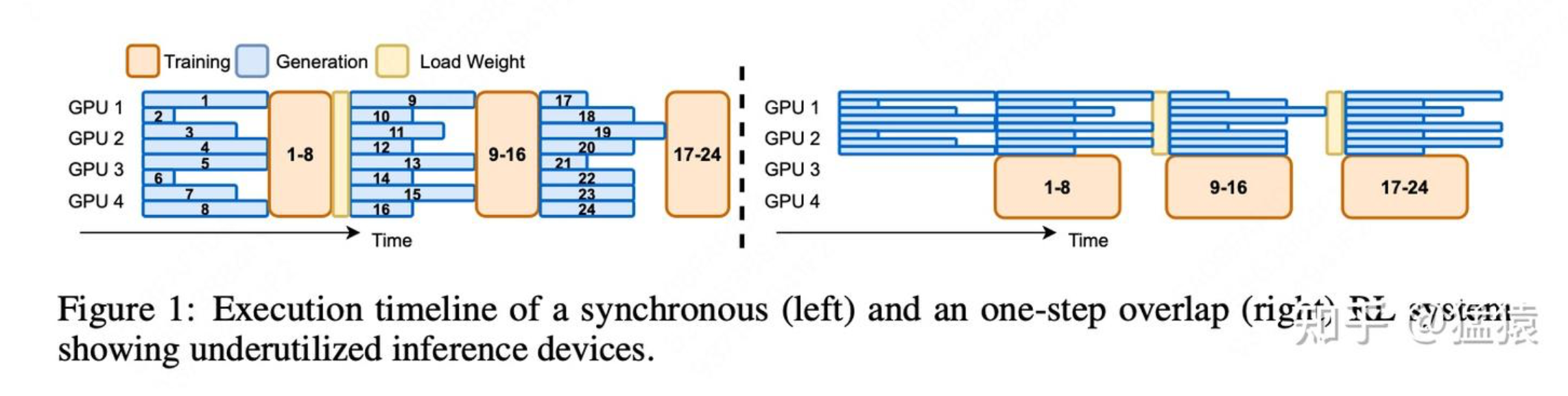
异步RL框架AReaL https://www.zhihu.com/question/1890112252100703430/answer/1890177974956970468 转自:https://zhuanlan.zhihu.com/p/1916441720817714438 一、异步的含义 在本文接下来的表达中,我们用**trainer(后端是deepspeed/fdsp/megatron等)**和 **rollout(后端是sglang/vllm等)**等来分别指代RL训练中做【训练】和【生成】的两个后端。 figure1的左图刻画了【同步RL训练】的流程,具体来说: 假设初始时刻actor的权重为 θ0 rollout使用θ0 ,吃一批prompt,生成对应的response。这批数据中的“每一条”都生成完毕后,rollout停止工作 trainer使用θ0 ,接收这批(prompt, response)数据,进一步生成exp值,进行训练,更新权重为 θ1 trainer将θ1 发送给rollout,rollout使用 ,重复上面的过程 显而易见,【同步RL训练...

TCP连接中ACK,SEQ变化
TCP连接中ACK,SEQ变化 以下是 TCP 连接中 ACK 和 SEQ 交互变化的详细示例(包含完整的三次握手、数据传输和四次挥手过程): 📡 连接建立阶段(三次握手) 客户端 → 服务器 SYN=1, SEQ=X(随机初始序列号) 客户端声明自己的初始序列号 X 服务器 → 客户端 SYN=1, ACK=1, SEQ=Y, ACK=X+1 服务器确认收到 X(ACK=X+1)并声明自己的初始序列号 Y 客户端 → 服务器 ACK=1, SEQ=X+1, ACK=Y+1 客户端确认收到 Y(ACK=Y+1),准备开始数据传输 📦 数据传输阶段 sequenceDiagram participant Client participant Server Client->>Server: SEQ=100, Data="ABC"(3字节) Server->>Client: ACK=103(SEQ=500,ACK号=100+3) Client->>Server: SEQ=103, Data="DEF"(3字节) Se...

github博客换机无缝迁移教程
github博客换机无缝迁移教程 迁移参考(这个迁移教程是不全的): https://blog.csdn.net/qq_43698421/article/details/120407042?fromshare=blogdetail&sharetype=blogdetail&sharerId=120407042&sharerefer=PC&sharesource=a1150568956&sharefrom=from_link 搭建参考: https://yangcheneee.github.io/categories/博客/ 旧电脑如下操作: 123456789101112131415161718## 旧电脑如下操作:bashgit clone $原仓库cd到目录下git checkout -b hexogit push origin hexo:hexo## 在hexo分支删掉除了.git文件之外的其他文件 将原来main分支的下面六个东西复制到下来:_config.ymlpackage.jsonscaffolds/source/themes...


