
UloRL:An Ultra-Long Output Reinforcement Learning Approach for Advancing Large Language Models’ Reasoning Abilities
UloRL:An Ultra-Long Output Reinforcement Learning Approach for Advancing Large Language Models’ Reasoning Abilities 论文链接:https://arxiv.org/pdf/2507.19766 转自:https://zhuanlan.zhihu.com/p/1932380821412638989 得益于Test-time Scaling的成功,大模型的推理能力取得了突破性的进展。为了探索Test-time Scaling的上限,我们尝试通过强化学习来扩展模型输出长度,以提升模型的推理能力。然而,强化学习在处理超长输出时面临两个问题:1) 由于输出长度的长尾分布问题,整体的训练效率低下;2) 超长序列的训练过程中会面临熵崩塌问题。为应对这些挑战,我们对GRPO做了一系列优化,提出了一个名为UloRL的强化学习算法。在Qwen3-30B-A3B的实验表明,通过我们的方法进行强化训练,模型在AIME-2025上由70.9提升到85.1,在BeyondAIME上由50.7提升...

Camel框架
NeurIPS 2023|AI Agents先行者CAMEL:第一个基于大模型的多智能体框架 转自:https://zhuanlan.zhihu.com/p/671093582 AI Agents是当下大模型领域备受关注的话题,用户可以引入多个扮演不同角色的LLM Agents参与到实际的任务中,Agents之间会进行竞争和协作等多种形式的动态交互,进而产生惊人的群体智能效果。本文介绍了来自KAUST研究团队的大模型心智交互CAMEL框架(“骆驼”),CAMEL框架是最早基于ChatGPT的autonomous agents知名项目,目前已被顶级人工智能会议NeurIPS 2023录用。 1777dbe9073c4bcd8ab59365481bcafc.png 论文题目: CAMEL: Communicative Agents for “Mind” Exploration of Large Scale Language Model Society 论文链接: https://ghli.org/camel.pdf 代码链接: https://github.com/camel-a...
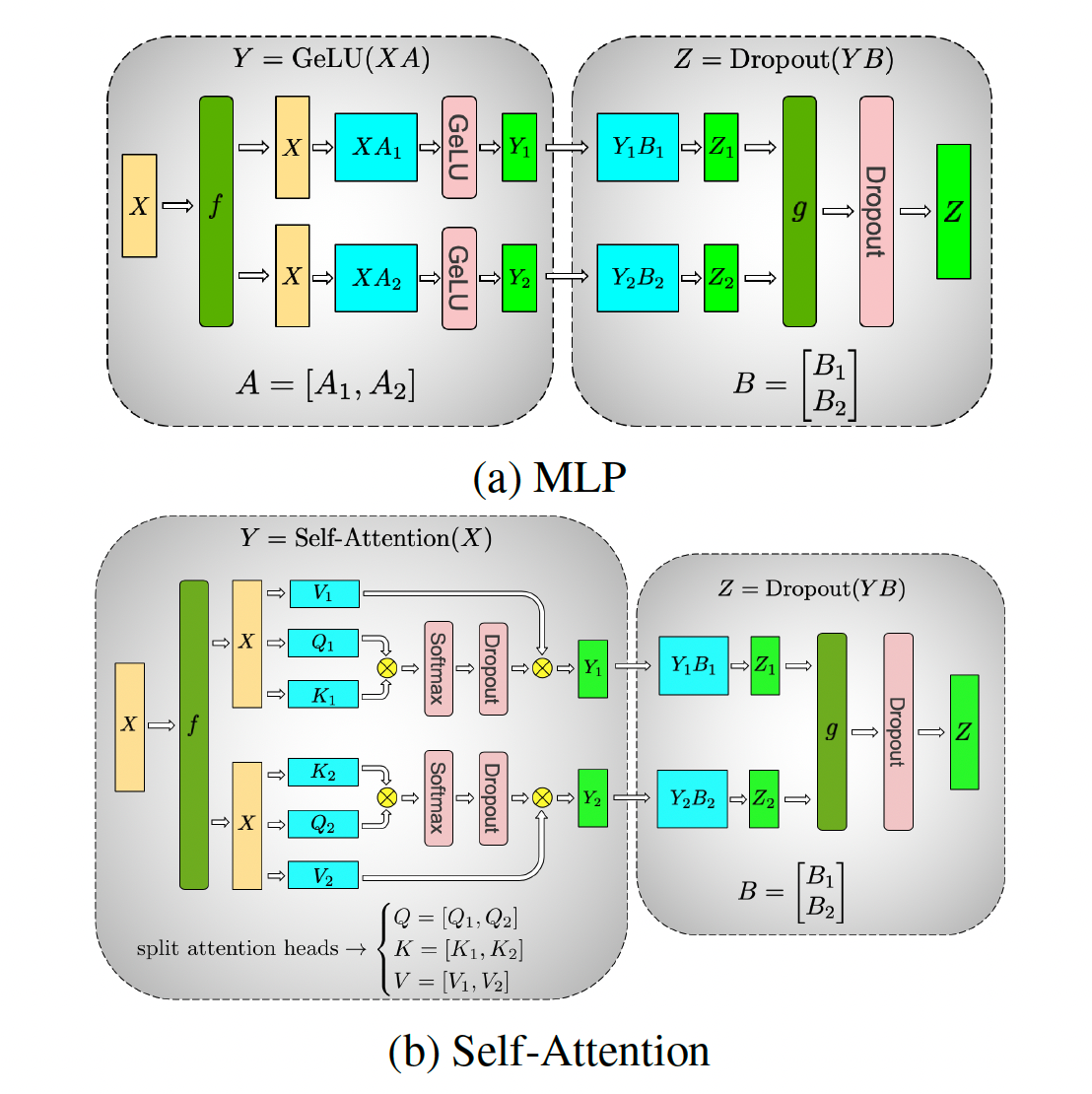
极简 Megatron-LM 模型并行切分介绍
极简 Megatron-LM 模型并行切分介绍 转自:https://zhuanlan.zhihu.com/p/498422407 在大模型流行的年代,我经常需要给同事解释 Megatron-LM 是怎么做的模型并行,自己也经常记不清从头推。而现有大多数的文章都是算法向或者历史向的,信息浓度比较低。为了节省大家的时间,在这里记录一下 Megatron-LM 的切分方式。由于只考虑切分,所以本文忽略 transformer 模型中的各种 elementwise 运算和 layernorm。 下文中,我们规定 b 为 batch size,s 为 sequence length,h 为 hidden size,n 为 num head,p 为切分数,用中括号表示 tensor 形状,例如 [b, s, h] 为常规的 transformer encoder 输入。这种表示方法参考了尤洋老师的 An Efficient 2D Method for Training Super-Large Deep Learning Models。 transformer encoder 结构 tran...
多Agent
多Agent https://www.zhihu.com/question/642650878/answer/1896282773486011813 https://zhuanlan.zhihu.com/p/1908922657027621854 多Agent系统,任务:https://zhuanlan.zhihu.com/p/1909200989090722209 AutoAgents是一个创新的框架,根据不同任务自适应地生成和协调多个专用代理来构建AI团队。AutoAgents通过动态生成多个所需代理并基于生成的专家代理为当前任务规划解决方案,将任务与角色之间的关系相结合。多个专门的代理相互协作以高效地完成任务。该框架还融入了观察者角色,反映指定计划和代理响应,并对其进行改进。该论文在各种基准测试上的实验证明,AutoAgents生成的解决方案比现有的多代理方法更连贯准确,为处理复杂任务提供了新的视角。 地址:https://http://arxiv.org/pdf/2309.17288 代码:https://http://github.com/LinkSoul-AI/Aut...
ray accelerate trainer lightning pytorch
ray、accelerate、trainer、lightning、pytorch 转自:https://www.zhihu.com/question/1926849595331318550/answer/1928049512619968205 作者:CodeCrafter 链接:https://www.zhihu.com/question/1926849595331318550/answer/1939450608894608104 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 2025 年,纯 PyTorch 是基本功,你必须得会,而且要熟。 它是你的内力,是你理解一切上层框架的基础。 Hugging Face Trainer 是特定领域(尤其是 NLP)的“版本答案”。 如果你就是做微调、做推理,用它,省心省力,快速出活儿。 Lightning 和 Accelerate 是“效率增强器”。 帮你把 PyTorch 代码写得更规范、更工程化,让你从繁琐的样板代码里解放出来,专注于模型本身。 Ray… 这家伙是个“大杀器”,跟前面几个不是一个维度...
xpu_timer
xpu_timer 转自:https://cloud.tencent.com/developer/article/2418684 背景 随着大型模型的参数量从十亿量级跃升至万亿级别,其训练规模的急剧扩张不仅引发了集群成本的显著上涨,还对系统稳定性构成了挑战,尤其是机器故障的频发成为不可忽视的问题。对于大规模分布式训练任务而言,可观测性能力成为了排查故障、优化性能的关键所在。所以从事大型模型训练领域的技术人,都会不可避免地面临以下挑战: 训练过程中,性能可能会因网络、计算瓶颈等多种因素而不稳定,出现波动甚至衰退; 分布式训练是多个节点协同工作的,任一节点发生故障(无论是软件、硬件、网卡或 GPU 问题),整个训练流程均需暂停,严重影响训练效率,而且浪费宝贵的 GPU 资源。 但在实际的大模型训练过程中,这些问题是很难排查的,主要原因如下: 训练过程为同步操作,很难通过整体性能指标来排除此时哪些机器出现问题,一个机器慢可以拖慢整体训练速度; 训练性能变慢往往不是训练逻辑/框架的问题,通常为环境导致,如果没有训练相关的监控数据,打印 timeline 实际上也没有任何作用,并且同...

Qwen3技术报告解读
Qwen3技术报告解读 转自:https://zhuanlan.zhihu.com/p/1905926139756680880 模型架构 Qwen3系列,包括6个Dense模型,分别是Qwen3-0.6B、Qwen3-1.7B、Qwen3-4B、Qwen3-8B、Qwen3-14B和Qwen3-32B;2个MoE模型,分别是Qwen3-30B-A3B和Qwen3-235B-A22B。 Qwen3 Dense模型的架构与Qwen2.5相似,包括GQA、SwiGLU、RoPE以及RMSNorm with pre-normalization。此外,移除了Qwen2中使用的QKV偏置,并在注意力机制中引入了QK-Norm,以确保Qwen3的稳定训练。 Qwen3 MoE模型采用了细粒度专家分割,共有128个专家,激活8个专家。但与Qwen2.5-MoE不同,Qwen3-MoE去除了共享专家。同时,采用了全局批次负载平衡损失。 预训练 预训练数据共36T Tokens,包含119种语言和方言,涉及代码、STEM、推理任务、书籍、合成数据等。 其中,有部分数据是Qwen2.5-VL模型对...
大模型蒸馏技术
导读 在人工智能快速发展的今天,模型的规模越来越大,计算成本也越来越高,这对中小型开发者来说无疑是一个巨大的挑战:如何通过将大模型的知识和能力浓缩到更小、更轻量化的模型中,降低硬件要求,以更低的成本享受到先进的人工智能技术? DeepSeek-R1及其API的开源标志着这一领域的重要突破。 对于中小型开发者而言,这意味着他们不再需要依赖庞大的计算资源就能实现高效、强大的人工智能应用。DeepSeek提供的开源蒸馏检查点(如基于Qwen2.5和Llama3系列的1.5B、7B、8B等参数规模)为开发者提供了丰富的选择空间,无论是初创公司还是个人项目,都可以根据自身需求灵活调用这些模型。 github 地址:https://github.com/deepseek-ai/DeepSeek-R1 这一技术不仅降低了人工智能的准入门槛,也为中小型开发者在资源有限的情况下实现创新提供了更多可能性。通过蒸馏模型,他们可以更专注于业务逻辑和应用场景的优化,而无需过多关注底层计算资源的限制。这无疑将推动人工智能技术在更广泛的领域中落地生根。 接下来,详细跟大家聊聊模型蒸馏。 一、为什么...
Qwen2.5大模型微调入门实战
Qwen2.5大模型微调入门实战 知识点:什么是全参数微调? 大模型全参数微调是指对预训练大模型的所有参数进行更新和优化,区别于部分参数微调和LoRA微调。 这种方法通过将整个模型权重(包括底层词嵌入、中间特征提取层和顶层任务适配层)在下游任务数据上进行梯度反向传播,使模型整体适应新任务的需求。相比仅微调部分参数,全参数微调能更充分地利用预训练模型的泛化能力,并针对特定任务进行深度适配,通常在数据差异较大或任务复杂度较高的场景下表现更优。 不过,全参数微调往往需要更高的计算资源和存储开销,且存在**过拟合风险**(尤其在小数据集上)。实际应用中常结合学习率调整、参数分组优化或正则化技术来缓解这些问题。 全参数微调多用于对模型表现性能要求较高的场景,例如专业领域知识问答或高精度文本生成。 1. 环境安装 本案例基于Python>=3.8,请在您的计算机上安装好Python; 另外,您的计算机上至少要有一张英伟达/昇腾显卡(显存要求大概32GB左右可以跑)。 我们需要安装以下这几个Python库,在这之前,请确保你的环境内已安装了pytorch以及CUDA: 1234567s...
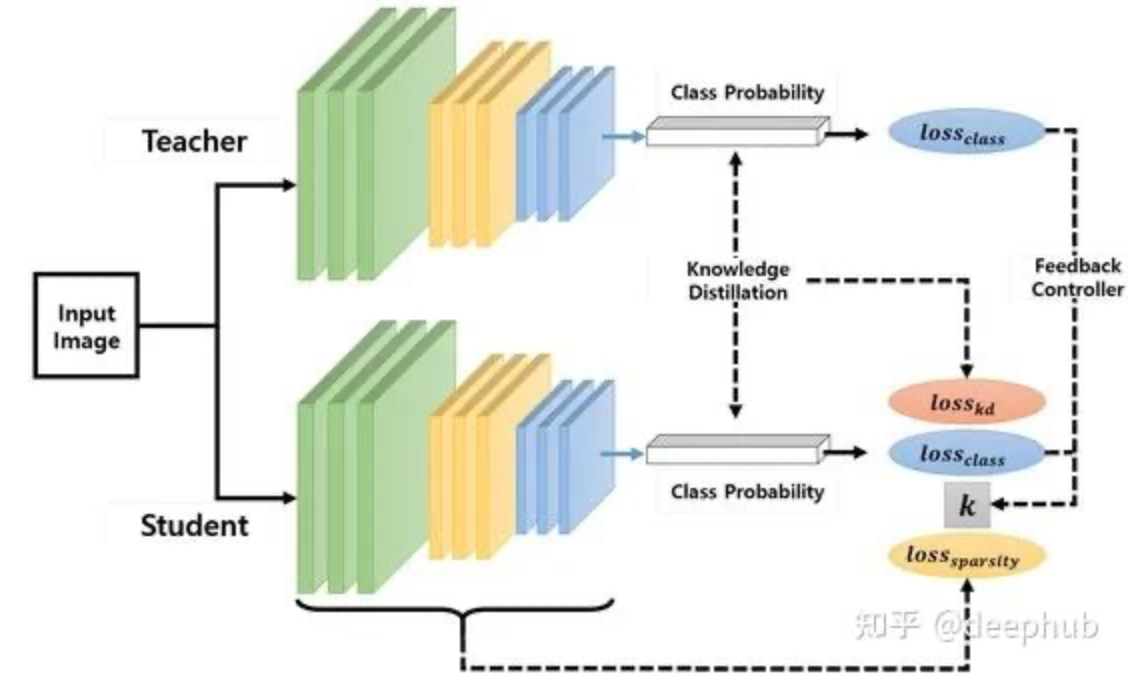
知识蒸馏技术原理详解:从软标签到模型压缩的实现机制
知识蒸馏技术原理详解:从软标签到模型压缩的实现机制 **知识蒸馏**是一种通过性能与模型规模的权衡来实现模型压缩的技术。其核心思想是将较大规模模型(称为教师模型)中的知识迁移到规模较小的模型(称为学生模型)中。本文将深入探讨知识迁移的具体实现机制。 知识蒸馏原理 知识蒸馏的核心目标是实现从教师模型到学生模型的知识迁移。在实际应用中,无论是大规模语言模型(LLMs)还是其他类型的神经网络模型,都会通过softmax函数输出概率分布。 Softmax输出示例分析 考虑一个输出三类别概率的神经网络模型。假设教师模型输出以下logits值: 教师模型logits: [1.1, 0.2, 0.2] 经过softmax函数转换后得到: Softmax概率分布: [0.552, 0.224, 0.224] 此时,类别0获得最高概率,成为模型的预测输出。模型同时为类别1和类别2分配了较低的概率值。这种概率分布表明,尽管输入数据最可能属于类别0,但其特征表现出了与类别1和类别2的部分相关性。 低概率信息的利用价值 在传统分类任务中,由于最高概率(0.552)显著高于其他概率值(均为0.224)...


