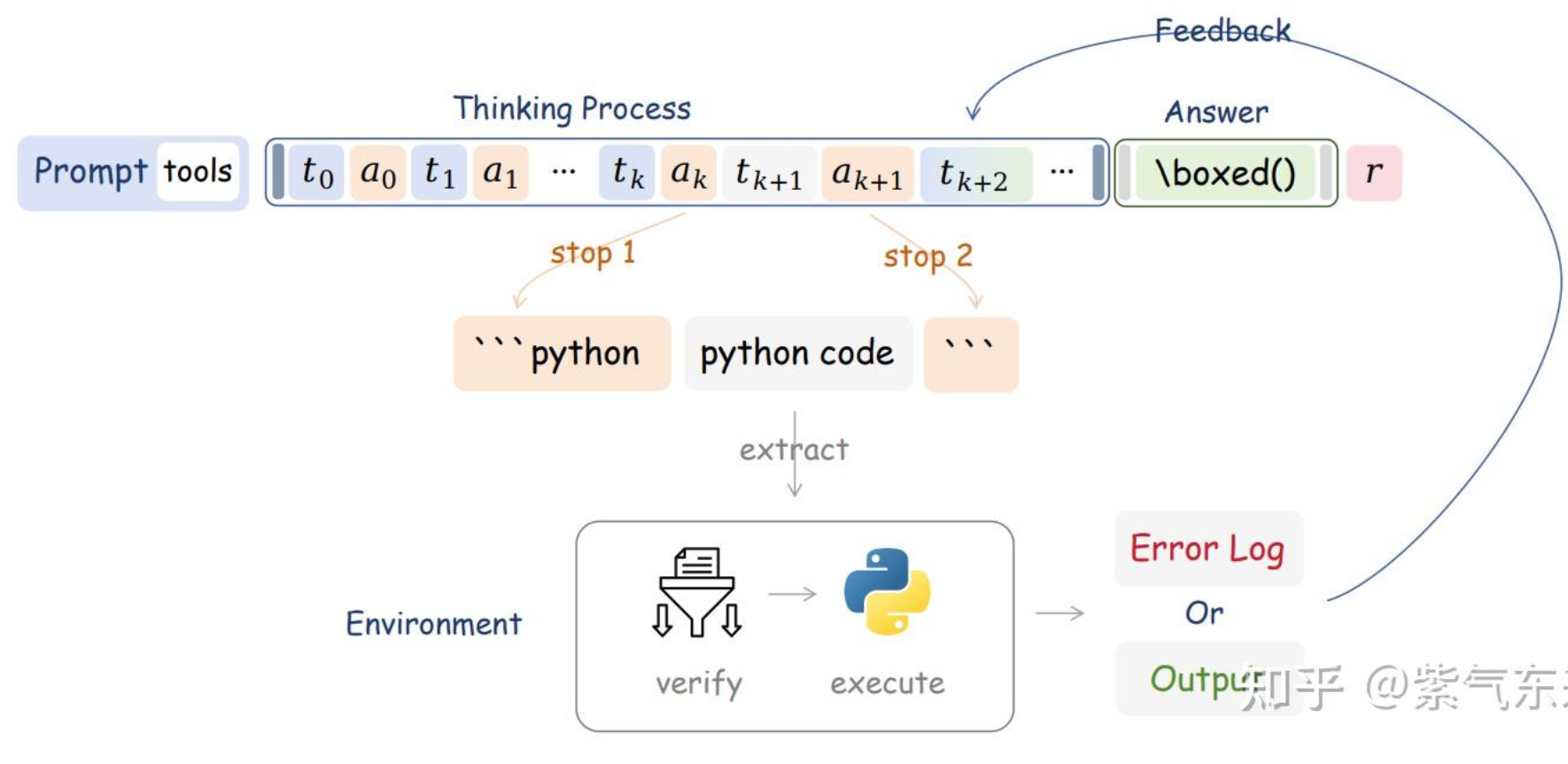
GSPO & Routing Replay
GSPO & Routing Replay
强化学习(RL)中用于大模型(尤其是MoE架构)的策略优化算法演进:GRPO → Routing Replay → GSPO。我们来系统梳理一下:
🧩 背景:GRPO 在 MoE 下的问题
什么是 GRPO?
GRPO(Generalized Reward Policy Optimization) 是一种广义的策略优化方法,旨在通过广义优势估计和策略梯度提升训练稳定性与样本效率,常用于语言模型的 RLHF(Reinforcement Learning from Human Feedback)阶段。
什么是 MoE?
MoE(Mixture of Experts) 是一种模型架构,通过“路由机制”动态选择部分专家(子网络)处理每个 token,从而在不显著增加计算量的前提下扩展模型容量。
GRPO 在 MoE 下的问题:
-
新旧策略的差异
新旧策略可能会激活不同的专家,产生结构性偏差,带来噪声。
当从 πθold 更新到 πθ 时,很有可能出现 Router 发生变化,导致新旧策略激活了不同的专家。
例如:
- 在 πθold 下,Router 激活了【专家 A】和【专家 B】
- 在 πθ 下,Router 激活了【专家 C】和【专家 D】
虽然模型参数只更新了一步,但实际参与计算的专家组合完全不同。所以这两个概率根本不是在同一个“结构”下产生的。
理想中的重要性比率应该反映同一个模型结构下,参数变化导致的输出概率变化。但现在它还包含了完全不同的专家组合导致输出的变化。
这不是策略变化的真实反映,这种波动具有高方差、不可预测、与优化方向无关的噪声。
-
Clip 也无法完全控制这种结构性偏差
πθ 和 πθold 实际上像是两个不同的模型,重要性比率的方差急剧上升,甚至趋于无穷。
不同的路由可能会导致 πθ 骤变,导致 clip 没有任何更新。梯度估计严重失真,训练不稳定甚至崩溃。
✅ Routing Replay:缓解专家冷启动 & 梯度稀疏
核心思想:
“重放”历史中激活较少的专家的路由决策,强制其参与训练,即使当前 batch 中未被选中。
实现方式:
- 在训练过程中,维护一个“路由历史缓冲区”,记录每个 token 被分配到哪些专家。
- 对于低频专家,从历史 buffer 中采样其曾被激活的样本,在当前 batch 中“重放”这些样本,强制计算其梯度并更新。
- 可配合重要性采样(Importance Sampling)修正策略偏移。
解决的问题:
- 缓解专家冷启动 → 所有专家都能持续更新。
- 降低梯度稀疏性 → 提高策略梯度估计的稳定性。
- 改善负载均衡 → 避免某些专家“饿死”。
局限性:
- 历史样本可能与当前策略不匹配 → 需要重要性加权,否则引入偏差。
- 增加内存和计算开销(需维护和采样历史 buffer)。
- 未从根本上解决“优势分配不公”的问题。
✅ GSPO(Generalized Sparse Policy Optimization):系统性解决 MoE-RL 问题
GSPO 是在 GRPO 基础上,专门为稀疏架构(如 MoE)设计的策略优化框架,从策略梯度公式、优势分配、路由正则化三个层面重构优化目标。
核心创新点:
1. 稀疏感知的优势分配(Sparse-Aware Advantage Redistribution)
- 不再将优势值(A_t)直接作用于所有专家,而是仅分配给当前激活的专家。
- 对未激活专家,使用“虚拟优势”或“路由置信度加权优势”,避免错误更新。
例如:
A_expert = A_t * routing_prob(expert | token)
即使 expert 未被选中,若其路由概率 > 0,仍获得部分优势信号。
2. 路由正则化(Routing Regularization)
- 引入路由熵最大化或负载均衡损失,鼓励路由策略探索不同专家。
- 防止路由“坍缩”到少数专家,提高专家利用率。
3. 专家级策略梯度裁剪与归一化
- 对每个专家单独进行梯度裁剪和优势归一化,避免因激活频率不同导致的梯度尺度差异。
- 例如:每个专家维护自己的 advantage running mean/std。
4. 结合 Routing Replay(可选增强)
- GSPO 可内嵌 Routing Replay 作为子模块,进一步缓解冷启动。
解决的问题:
✅ 梯度稀疏 → 通过稀疏感知优势分配 + 专家独立归一化
✅ 负载不均衡 → 路由正则化 + 路由熵鼓励探索
✅ 优势分配不公 → 仅更新激活专家 + 概率加权
✅ 策略偏移 → 专家级归一化 + 重要性采样(如使用)
📊 对比总结:
| 方法 | 核心机制 | 解决 GRPO 在 MoE 的哪些问题 | 局限性 |
|---|---|---|---|
| GRPO | 通用策略梯度 + 优势估计 | 无,原生不兼容 MoE | 梯度稀疏、负载不均、优势误分配 |
| Routing Replay | 重放冷门专家历史样本 | 缓解梯度稀疏、冷启动 | 历史偏差、额外开销 |
| GSPO | 稀疏感知优势 + 路由正则 + 专家归一化 | 系统性解决稀疏、负载、优势分配问题 | 实现复杂,需专家级统计 |
🚀 实际应用建议:
- 如果你正在 MoE + RLHF 场景下训练大模型(如 Mixtral + DPO/RLHF),优先考虑 GSPO。
- 若实现复杂,可先用 Routing Replay 作为轻量级补丁 缓解冷启动。
- 结合 路由负载均衡损失(如 Switch Transformer 中的 auxiliary loss)进一步稳定训练。
📚 参考文献/来源(部分为前沿工作,尚未完全公开):
- DeepSeek-V2 / Mixtral RLHF 技术报告(提及 GSPO)
- Google “Sparse RL” 内部技术分享(2024)
- OpenAI “MoE for RL” 非正式讨论(社区流传)
- 相关论文:“Efficient RL for Sparse Models” (ICLR Workshop 2024)
✅ 总结一句话:
Routing Replay 通过“重放”缓解专家冷启动,GSPO 通过“稀疏感知策略优化 + 路由正则”系统性重构 RL 目标,二者协同解决 GRPO 在 MoE 架构下的梯度稀疏、负载不均与优势误分配问题。
如果你有具体实现细节或想看伪代码,我也可以进一步展开 👍