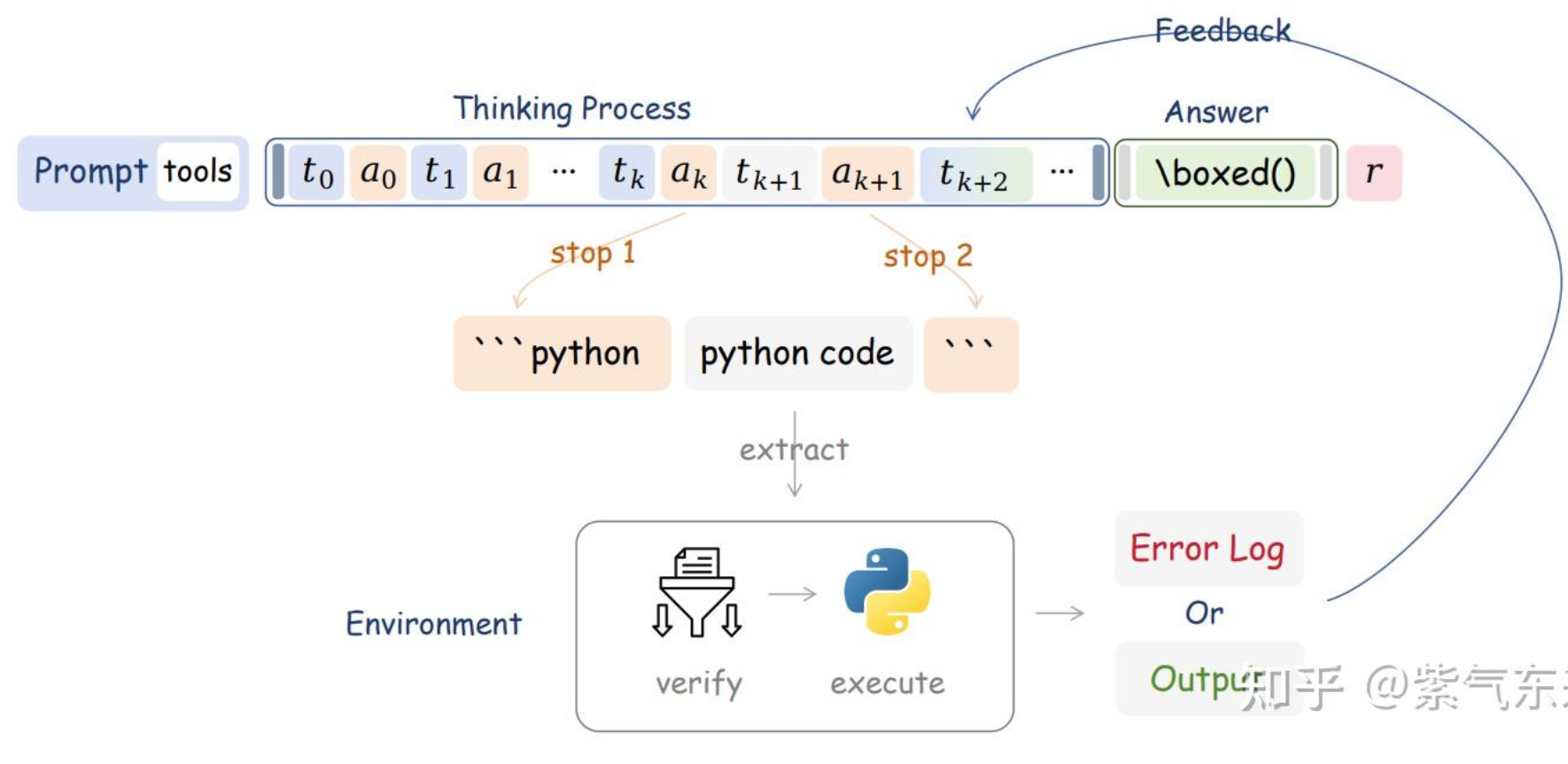
PPO:https://zhuanlan.zhihu.com/p/468828804

Policy Gradient公式推导与举例
1. 优化目标
我们要最大化强化学习的期望回报(Expected Return):
Rθ=Eτ∼pθ(τ)[R(τ)]=τ∑R(τ)pθ(τ)
-
τ
表示一条轨迹(trajectory),即从初始状态到结束的一系列
(s1,a1,s2,a2,…)
。
-
pθ(τ)
表示策略
πθ
产生轨迹
τ
的概率。
-
R(τ)
是轨迹的总回报。
2. 对参数 θ\theta 求梯度
∇θRˉθ=τ∑R(τ)∇θpθ(τ)
直接对概率 pθ(τ)p_\theta(\tau) 求导不方便。
3. 使用 log trick (对数技巧)
∇θpθ(τ)=pθ(τ)∇θlogpθ(τ)
这是右边小蓝框里的公式:
∇f(x)=f(x)∇logf(x)
4. 替换进目标函数
∇θRˉθ=τ∑R(τ)pθ(τ)∇θlogpθ(τ)
这一步就是图中红框标出来的地方。
5. 期望形式
上式其实是 在轨迹分布 pθ(τ)p_\theta(\tau) 下的期望:
∇θRˉθ=Eτ∼pθ(τ)[R(τ)∇θlogpθ(τ)]
6. 蒙特卡洛近似
我们用采样得到的轨迹来估计期望:
∇θRˉθ≈N1n=1∑NR(τn)∇θlogpθ(τn)
其中 NN 是采样的轨迹数。
7. 分解轨迹概率
轨迹概率
θ(τ)
可以写成一连串动作选择概率的乘积:
θ(τ)=t=1∏Tπθ(at∣st)⋅P(st+1∣st,at)
因为环境转移
P(st+1∣st,at)
不依赖 θ(对数求导后,环境转移与θ无关,所以这部分值被舍弃了),所以:
∇θlogpθ(τ)=t=1∑T∇θlogπθ(at∣st)
8. 最终公式
所以得到:
∇θRˉθ≈N1n=1∑Nt=1∑TnR(τn)∇θlogπθ(atn∣stn)
这就是 REINFORCE 算法 的核心更新规则。
✅ 直观理解:
用一个非常简单的两步决策问题来举例
🎯 环境设定
-
每条轨迹
τ=(a1,a2)
,一共两步。
-
动作空间:{L, R}。
-
策略:
πθ(a∣s)
(假设每一步状态相同,为了简单)。
-
回报:
也就是说,智能体必须 连续两步选 L 才有奖励。
1. 轨迹概率
假设策略是一个伯努利分布,
那么轨迹概率:
-
pθ(L,L)=p⋅p=p2
-
pθ(L,R)=p(1−p)
-
pθ(R,L)=(1−p)p
-
pθ(R,R)=(1−p)2
2. 期望回报
Rˉθ=τ∑R(τ)pθ(τ)=1⋅p2+0⋅(其他)=p2
很直观:只有 (L,L)(L,L) 有奖励。
3. 用 log-trick 求梯度
目标函数:
∇θRˉθ=Eτ∼pθ(τ)[R(τ)∇θlogpθ(τ)]
(求和转化成期望的形式)
4. 展开公式
采样一条轨迹,比如 (L,L),
-
回报
R(τ)=1
。
-
轨迹概率
pθ(τ)=p2
。
-
logpθ(τ)=log(p2)=2logp
。
-
∇θlogpθ(τ)=p2∇θp
。
所以:
∇θlogpθ(τ)=1⋅p2∇θp
如果轨迹是 (R,R),则回报 00,更新量为 00。
5. 蒙特卡洛估计
如果我们从策略中采样 N=3 条轨迹:
-
τ1=(L,L)
,R=1。
-
τ2=(L,R)
,R=0。
-
τ3=(R,L)
,R=0。
那么梯度估计:
∇θRˉθ≈31[1⋅∇θlogp2+0+0]=31⋅2⋅p1∇θp
✅ 直观解释