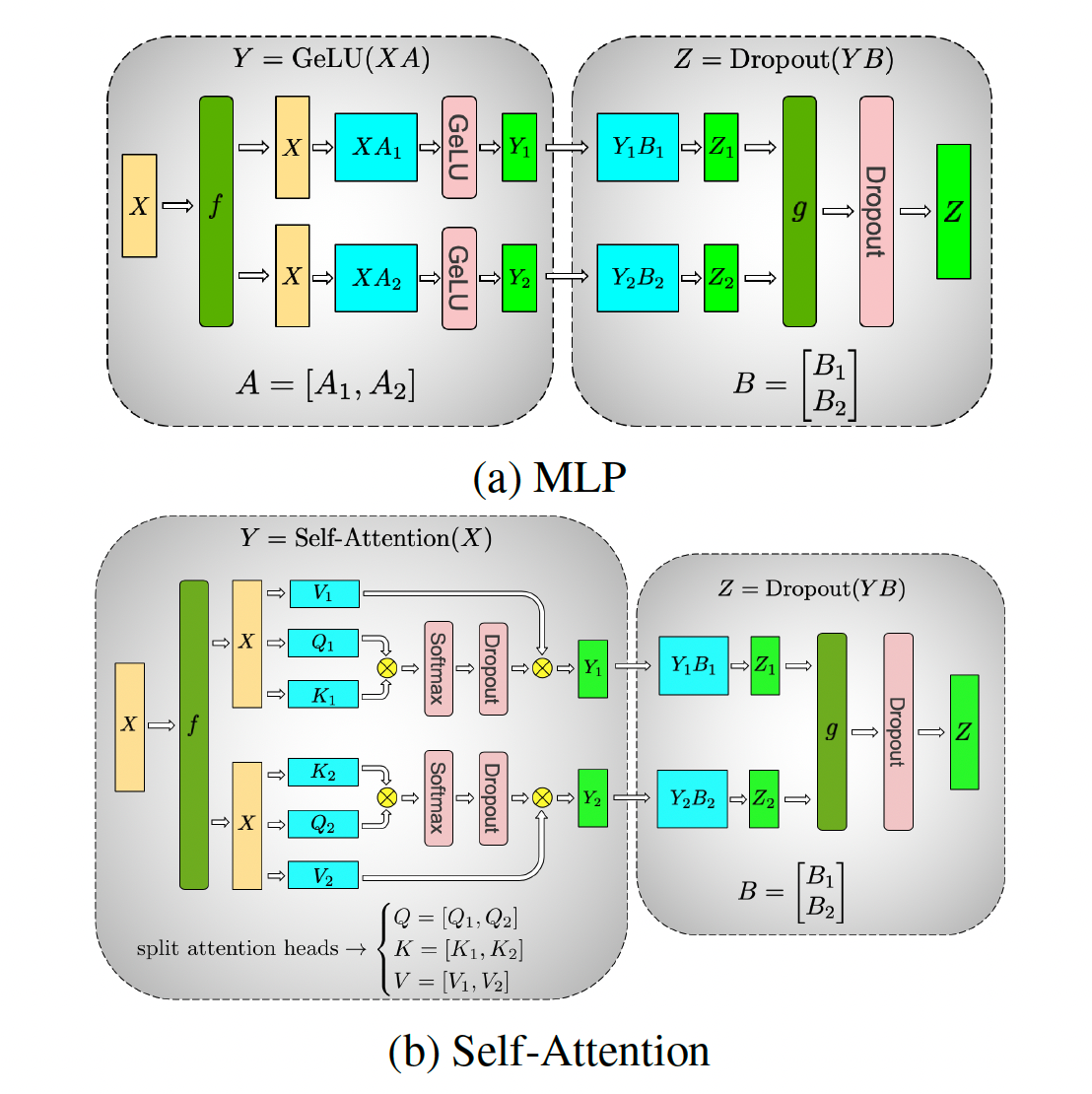
Megatron & Swift监督微调Qwen3-8B
因为纯Megatron的example中没有对于Qwen的支持,且在社区中没有找到对应封装好的实现。这里Swift已经封装好了对于微调/预训练/强化学习/多种模型/dataloader的各种支持,同时也包含训练结果的图像绘制,可以自主选择Megatron的后端路径(如果要进行修改,就对开源的core_r0.13.0分支的代码进行修改就行,运行时指定该路径)。
平台是选用的无问芯穹的开发机进行实验
注:也可以用llama-factory去做,后续可以试一试
参考
Megatron-SWIFT训练:https://swift.readthedocs.io/zh-cn/latest/Instruction/Megatron-SWIFT%E8%AE%AD%E7%BB%83.html
千问3最佳实践:https://swift.readthedocs.io/zh-cn/latest/BestPractices/Qwen3最佳实践.html#megatron-swift
注意参数:https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%8F%82%E6%95%B0.html
hf上甚至有swift完整教程:https://huggingface.co/Qwen/Qwen3-235B-A22B/discussions/6
且自带评测,但是没找到纯megatron的例子
模型支持
支持Qwen3-8B

常见问题
https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E6%95%B4%E7%90%86.html
自定义数据集
数据集支持自定义:
监督微调的数据格式如下(单轮/多轮对话的形式):
1
2
| {"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "告诉我明天的天气"}, {"role": "assistant", "content": "明天天气晴朗"}]}
{"messages": [{"role": "system", "content": "你是个有用无害的数学计算器"}, {"role": "user", "content": "1+1等于几"}, {"role": "assistant", "content": "等于2"}, {"role": "user", "content": "再加1呢"}, {"role": "assistant", "content": "等于3"}]}
|
导入:
直接使用命令行传参的方式接入,即--dataset <dataset_path1> <dataset_path2>。这将使用AutoPreprocessor将数据集转换为标准格式。
数据集准备:Megatron & Swift监督微调:数据集准备
推荐环境 & 环境准备
镜像:cr.infini-ai.com/infini-ai/llm-demo:pytorch-24.03-py3-v25.04
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| ln -s /usr/bin/python3 /usr/bin/python
# 推荐
pip install 'ms-swift' -i https://pypi.tuna.tsinghua.edu.cn/simple
# 推荐torch版本:2.5 / 2.6
pip install pybind11 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install deepspeed -i https://pypi.tuna.tsinghua.edu.cn/simple
# 如果没有cudnn
sudo apt install libcudnn8 libcudnn8-dev
# transformer_engine
# 若出现安装错误,可以参考该issue解决: https://github.com/modelscope/ms-swift/issues/3793
NVTE_FRAMEWORK=pytorch pip install --no-build-isolation transformer_engine[pytorch] -i https://pypi.tuna.tsinghua.edu.cn/simple
#如果有问题 ⭐️(建议直接用这个)
pip install transformer-engine[pytorch]==1.13.0 --no-build-isolation -i https://pypi.tuna.tsinghua.edu.cn/simple
# 或使用以下方式安装
# pip install --no-build-isolation git+https://github.com/NVIDIA/TransformerEngine.git@release_v2.5#egg=transformer_engine[pytorch]
# apex
git clone https://github.com/NVIDIA/apex
cd apex
# https://github.com/modelscope/ms-swift/issues/4176
git checkout e13873debc4699d39c6861074b9a3b2a02327f92
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
# megatron-core。不过如果后端用的是自己的/pip下不下来,可以git clone的方式 然后chekcout过去
pip install git+https://github.com/NVIDIA/Megatron-LM.git@core_r0.13.0
# 若使用多机训练,请额外设置`MODELSCOPE_CACHE`环境变量为共享存储路径
# 这将确保数据集缓存共享,而加速预处理速度
export MODELSCOPE_CACHE='/xxx/shared'
# Megatron-LM
# 依赖库Megatron-LM中的训练模块将由swift进行git clone并安装。你也可以通过环境变量`MEGATRON_LM_PATH`指向已经下载好的repo路径(断网环境,[core_r0.13.0分支](https://github.com/NVIDIA/Megatron-LM/tree/core_r0.13.0))。
export MEGATRON_LM_PATH='/root/Megatron-LM'
# 注意如果这里用自己的路径,记得进入到Megatron目录下面
cd Megatron-LM
git checkout core_r0.13.0
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
# 因为是Qwen3,这里装一个flash-attention
pip install flash-attn==2.6.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 注意这里经过反复测试,是2.6.2的版本是好的
# 如果这里卡了,直接https://github.com/Dao-AILab/flash-attention/releases/tag/v2.6.2,下载下来,然后
pip install flash-attnxxxxxx-linux-_x86_64.whl --no-build-isolation
# 数据集放到/root/dataset下面,jsonl格式
|
检验环境
1
2
3
4
5
6
7
8
9
10
| python -c "
import torch
print('PyTorch:', torch.__version__)
import transformer_engine
print('TransformerEngine:', transformer_engine.__version__)
from transformer_engine.pytorch import LayerNorm, Linear
print('Success: transformer_engine loaded correctly.')
"
|
预期输出:
1
2
3
| PyTorch: 2.6.0+cu124
TransformerEngine: 1.13.0
Success: transformer_engine loaded correctly.
|
检验环境
1
2
3
4
5
6
7
8
9
| python -c "
import transformer_engine
print('transformer_engine version:', transformer_engine.__version__)
print('Submodules:', dir(transformer_engine))
print('Has pytorch module:', hasattr(transformer_engine, 'pytorch'))
from transformer_engine.pytorch import Linear
print('Success: TELinear can be imported.')
"
|
预期输出:
1
2
3
4
| transformer_engine version: 1.13.0
Submodules: ['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__', 'common', 'metadata', 'pytorch', 'transformer_engine']
Has pytorch module: True
Success: TELinear can be imported.
|
模型下载
1
2
3
4
5
6
7
8
9
10
11
12
| cd ~
pip install huggingface_hub[cli] -i https://pypi.tuna.tsinghua.edu.cn/simple
export HF_ENDPOINT=https://hf-mirror.com
HF_ENDPOINT=https://hf-mirror.com huggingcface-cli download Qwen/Qwen3-8B --local-dir Qwen3-8B
# 根据环境不同,当然也可以是 HF_ENDPOINT=https://hf-mirror.com hf download Qwen/Qwen3-8B --local-dir Qwen3-8B
# 当然也可以多线程下载
wget https://hf-mirror.com/hfd/hfd.sh
chmod +x hfd.sh
export HF_ENDPOINT=https://hf-mirror.com
apt-get update && apt-get install -y aria2
HF_ENDPOINT=https://hf-mirror.com ./hfd.sh Qwen/Qwen3-8B --local-dir Qwen3-8B -x 10 -j 5
|
模型格式转换
这里要将HF的格式–>Megatron的格式
1
2
3
4
5
6
| MEGATRON_LM_PATH='/root/Megatron-LM' CUDA_VISIBLE_DEVICES=0 \
swift export \
--model Qwen3-8B \
--to_mcore true \
--torch_dtype bfloat16 \
--output_dir Qwen3-8B-mcore --test_convert_precision true
|
训练完后再转回来
1
2
| CUDA_VISIBLE_DEVICES=0 \
swift export \ --mcore_model megatron_output/Qwen3-8B/vx-xxx \ --to_hf true \ --torch_dtype bfloat16 \ --output_dir megatron_output/Qwen3-8B/vx-xxx-hf \ --test_convert_precision true
|
微调指令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| cd ~
# 下载好模型后,转换格式
MEGATRON_LM_PATH='/root/Megatron-LM' CUDA_VISIBLE_DEVICES=0 \
swift export \
--model Qwen3-8B \
--to_mcore true \
--torch_dtype bfloat16 \
--output_dir Qwen3-8B-mcore --test_convert_precision true
# 开训(两卡)
NVTE_DEBUG=1 NVTE_DEBUG_LEVEL=2 \
MEGATRON_LM_PATH='/root/Megatron-LM' PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
NPROC_PER_NODE=2 \
CUDA_VISIBLE_DEVICES=0,1 \
megatron sft \
--load Qwen3-8B-mcore \
--dataset '/root/dataset/multi_round_output.jsonl' '/root/dataset/output_messages.jsonl' \
--tensor_model_parallel_size 2 \
--sequence_parallel \
--micro_batch_size 2 \
--global_batch_size 16 \
--recompute_granularity full \
--recompute_method uniform \
--recompute_num_layers 3 \
--finetune \
--cross_entropy_loss_fusion \
--lr 1e-5 \
--lr_warmup_fraction 0.05 \
--min_lr 1e-6 \
--max_epochs 1 \
--save /dev/shm/Qwen3-8B-sft \
--save_interval 50 \
--max_length 2048 \
--add_version false \
--system 'You are a helpful assistant.' \
--num_workers 2 \
--dataset_num_proc 4 \
--model_author swift \
--model_name swift-robot
# 四卡
MEGATRON_LM_PATH='/root/Megatron-LM' PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
megatron sft \
--load Qwen3-8B-mcore \
--dataset '/root/dataset/multi_round_output.jsonl' '/root/dataset/output_messages.jsonl' \
--tensor_model_parallel_size 2 \
--sequence_parallel \
--micro_batch_size 1 \
--global_batch_size 16 \
--recompute_granularity full \
--recompute_method uniform \
--recompute_num_layers 3 \
--finetune \
--cross_entropy_loss_fusion \
--lr 1e-5 \
--lr_warmup_fraction 0.05 \
--min_lr 1e-6 \
--max_epochs 3 \
--save /dev/shm/Qwen3-8B-sft \
--save_interval 900 \
--max_length 2048 \
--add_version false \
--system 'You are a helpful assistant.' \
--num_workers 4 \
--dataset_num_proc 4 \
--model_author swift \
--model_name swift-robot
|
类型选择是这一部分:
这里训练的时候,flash-attn会有问题,社区解决方案不奏效
1
| attributeerror: module 'transformer_engine' has no attribute 'pytorch'
|
社区:
https://github.com/NVIDIA/TransformerEngine/issues/1014
https://github.com/NVIDIA/Megatron-LM/issues/696
https://github.com/Dao-AILab/flash-attention/issues/1816
跑起来了。重点是按照前面的镜像的环境,按照下面的方式去设置(这部分内容移到之前的环境配置中了,不会再出现此问题):
1
2
3
4
| #镜像
cr.infini-ai.com/infini-ai/inference-distributed:vllm0.8.4-torch2.8-cuda12.4.0-python3.12-ubuntu22.04
pip install flash-attn==2.6.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install transformer-engine[pytorch]==1.13.0 --no-build-isolation -i https://pypi.tuna.tsinghua.edu.cn/simple
|
训练完成
这里还有训练的结果:
多机多卡
Megatron swift 多机的例子:https://github.com/modelscope/ms-swift/blob/main/examples/train/megatron/multi-node
node1.sh(master node)
两卡A100
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| MEGATRON_LM_PATH='/root/Megatron-LM' PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
CUDA_VISIBLE_DEVICES=0,1 \
NNODES=2 \
NODE_RANK=0 \
MASTER_ADDR=127.0.0.1 \
MASTER_PORT=29500 \
NPROC_PER_NODE=2 \
nohup megatron sft \
--load Qwen3-8B-mcore \
--dataset '/mnt/lvzhongrenjie/dataset/multi_round_output.jsonl' '/mnt/lvzhongrenjie/dataset/output_messages.jsonl' \
--split_dataset_ratio 0.01 \
--tensor_model_parallel_size 2 \
--sequence_parallel \
--micro_batch_size 2 \
--global_batch_size 16 \
--recompute_granularity full \
--recompute_method uniform \
--recompute_num_layers 3 \
--finetune \
--cross_entropy_loss_fusion \
--lr 1e-5 \
--lr_warmup_fraction 0.05 \
--min_lr 1e-6 \
--max_epochs 3 \
--save /mnt/lvzhongrenjie/megatron_output/Qwen3-8B-sft \
--save_interval 50 \
--max_length 2048 \
--add_version false \
--system 'You are a helpful assistant.' \
--num_workers 4 \
--dataset_num_proc 4 \
--model_author swift \
--model_name swift-robot >run.log 2>&1 &
|
node2.sh
两卡A100
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| MEGATRON_LM_PATH='/root/Megatron-LM' PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
CUDA_VISIBLE_DEVICES=0,1 \
NNODES=2 \
NODE_RANK=1 \
MASTER_ADDR=10.208.24.97 \
MASTER_PORT=29500 \
NPROC_PER_NODE=2 \
nohup megatron sft \
--load Qwen3-8B-mcore \
--dataset '/mnt/lvzhongrenjie/dataset/multi_round_output.jsonl' '/mnt/lvzhongrenjie/dataset/output_messages.jsonl' \
--split_dataset_ratio 0.01 \
--tensor_model_parallel_size 2 \
--sequence_parallel \
--micro_batch_size 2 \
--global_batch_size 16 \
--recompute_granularity full \
--recompute_method uniform \
--recompute_num_layers 3 \
--finetune \
--cross_entropy_loss_fusion \
--lr 1e-5 \
--lr_warmup_fraction 0.05 \
--min_lr 1e-6 \
--max_epochs 3 \
--save /mnt/lvzhongrenjie/megatron_output/Qwen3-8B-sft \
--save_interval 50 \
--max_length 2048 \
--add_version false \
--system 'You are a helpful assistant.' \
--num_workers 4 \
--dataset_num_proc 4 \
--model_author swift \
--model_name swift-robot >run.log 2>&1 &
|
Ok:
推理+微调前后的简单对比
先把训好的转回来
1
2
3
4
5
6
7
| MEGATRON_LM_PATH='/root/Megatron-LM' CUDA_VISIBLE_DEVICES=0 \
swift export \
--mcore_model /mnt/lvzhongrenjie/megatron_output/Qwen3-8B-sft \
--to_hf true \
--torch_dtype bfloat16 \
--output_dir /mnt/lvzhongrenjie/megatron_output/Qwen3-8B-sft/00001024-hf \
--test_convert_precision true
|
推理的命令:
1
2
3
4
5
6
| CUDA_VISIBLE_DEVICES=0 \
swift infer \
--model /mnt/lvzhongrenjie/megatron_output/Qwen3-8B-sft/00001024-hf \
--stream true \
--temperature 0 \
--max_new_tokens 2048
|
至此完成整个流程
不过可以发现,对于微调前后的模型,对于不在数据集内的其他问题的回答,微调后的数据集的回答内容倾向于变短。这是因为微调数据集中,单轮短对话的占比较多(95%,另外多对对话每轮的也很短),导致微调后模型在decode阶段倾向于输出较短的回答。
对于数据集之外的QA测试,看看通用能力的变化:
微调前,数据集之外的回答:
微调后,数据集之外的回答(通用能力)::
这里输出就变得非常短,信息量是不够的。
可以看出这里的数据集的质量对于其影响是非常大的,甚至影响了其在通用能力上的问题的回答。
另外微调场景下,发现通过多轮对话的数据集+回答质量+现有产品文档之间似乎存在一个不可能三角:
- 我们希望用户在进行一个问题的输入时,微调后的模型能够准确的回答出所有的答案,输出的长度是有保证的,而不是用户反复的去询问;但现有的文档对应一个网页,也对应一个/一系列固定的问题,如果将这个文档拆成多轮对话的形式,其单个子问题的回答一定是简短的,也就意味着微调完后的模型的一次回答注定也只会吐出少量的token(如果问的问题是很具体的,那么这种挤牙膏式的回答能够回答的很简短和具体,是符合要求的;如果问的问题是很宽泛的,涉及到多个步骤,那么这种挤牙膏的回答就是很不好的,信息量就很低),回答质量堪忧
- 我们希望通过微调的形式->产生对应产品文档的准确的回答,但微调后本身产生的回答相比较原文档就是有出入的(如果RAG的形式通过检索找回重排后这种情况就会好很多)
- 模型的通用能力会受影响,对于官方文档之外的内容——比如回答的风格发生变化,Qwen原有的风格的输出是很详细的且带有思维链的过程,这里做的数据集并没有think这一步,且数据集本身的回答导致“挤牙膏”进而会影响到数据集之外的回答,比如截图中的对于TCP重复的理解的回答就很不好,这也是微调(无论是Lora还是全量)的风险之一(依赖于高质量的数据集)
混合数据集?长短结合?
这里直接用原有官方文档的清洗后的数据集去微调(摒弃掉多轮对话的形式,即一个QA对应一个网页的内容去试一把)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| # finetune
MEGATRON_LM_PATH='/root/Megatron-LM' PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
megatron sft \
--load Qwen3-8B-mcore \
--dataset '/root/dataset/dataset_original.jsonl' \
--tensor_model_parallel_size 2 \
--sequence_parallel \
--micro_batch_size 1 \
--global_batch_size 16 \
--recompute_granularity full \
--recompute_method uniform \
--recompute_num_layers 3 \
--finetune \
--cross_entropy_loss_fusion \
--lr 1e-5 \
--lr_warmup_fraction 0.05 \
--min_lr 1e-6 \
--max_epochs 3 \
--save /mnt/lvzhongrenjie/megatron_output/Qwen3-8B-sft-original \
--save_interval 50 \
--max_length 2048 \
--add_version false \
--system 'You are a helpful assistant.' \
--num_workers 4 \
--dataset_num_proc 4 \
--model_author swift \
--model_name swift-robot
# transfer
MEGATRON_LM_PATH='/root/Megatron-LM' CUDA_VISIBLE_DEVICES=0 \
swift export \
--mcore_model /mnt/lvzhongrenjie/megatron_output/Qwen3-8B-sft-original \
--to_hf true \
--torch_dtype bfloat16 \
--output_dir /mnt/lvzhongrenjie/megatron_output/Qwen3-8B-sft-original/original-hf \
--test_convert_precision true
# infer
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--model /mnt/lvzhongrenjie/megatron_output/Qwen3-8B-sft-original/original-hf \
--stream true \
--temperature 0 \
--max_new_tokens 2048
|
结果如下:
感觉回答的也还行
有时会抽风(不知道为什么):
因此这种方式似乎也不行。
公司内容的问答机器人感觉就是用RAG实现的。
相对应的,微调后的回答就依旧挤牙膏:
RAG?
PS:微调的数据集的质量太重要了(Qwen倾向于think)。保险起见还是RAG更有效些。
为什么RAG是更好的选择(来自Qwen的回答)
1️⃣ 知识准确性与可验证性(最关键因素)
- RAG:回答严格基于检索到的产品文档片段,可提供引用来源
- 客户可以验证答案来源:“根据[产品手册第5章]…”
- 避免模型编造不存在的功能或错误信息
- 微调:模型内化知识后难以验证准确性
- 产品更新后,模型可能提供过时信息而不自知
- 无法向客户证明答案来源,降低可信度
2️⃣ 知识更新效率
- RAG:产品文档更新后,只需更新向量数据库
- 即时生效,无需重新训练
- 适合产品迭代频繁的场景(多数SaaS产品每周/每月更新)
- 微调:每次产品更新都需要
- 重新收集/生成训练数据
- 重新训练模型(成本高、耗时长)
- 风险:新训练可能破坏已有知识
3️⃣ 避免能力退化风险
正如您敏锐指出的:
“微调非常依赖制作出来数据集的质量,质量不好很容易导致模型的相关能力下降;但是RAG就不存在这个问题,会保留原模型的能力”
- RAG:完全保留Qwen3-8B的原始能力
- 通用语言理解、多轮对话、基础推理能力不受影响
- 对于文档未覆盖的问题,能诚实回答"我不知道"
- 微调:存在严重风险
- 低质量数据集会污染模型的基础能力
- 可能导致灾难性遗忘(catastrophic forgetting)
- 评估困难:很难全面测试模型是否"变笨了"
4️⃣ 实施成本与维护
- RAG:
- 初期需搭建检索系统(但有成熟开源方案如LangChain、LlamaIndex)
- 文档处理自动化后,维护成本低
- 可轻松扩展多语言、多产品线支持
- 微调:
- 需要专业团队构建高质量SFT数据集
- 持续的训练基础设施投入
- 每次更新都需要完整评估流程
评测打分:TODO
两机四卡,按照上述数据集进行微调后的相关指标。
运行结果
标准数据集:TODO
对微调前后的数据集在benchmark上进行评测,查看是否有通用能力上的性能损失(似乎不用看了,损失太明显了)
Qwen3-8B微调前在相关评测数据集上的指标:
Qwen3-8B微调后在相关评测数据集上的指标:
Swift对应到Megatron后端
命令行解析代码位置:
- 主入口点:
[swift/cli/main.py](swift/cli/main.py:56) - [cli_main()](swift/cli/main.py:56) 函数处理所有命令路由
1.
- Megatron特定入口:
[swift/cli/_megatron/main.py](swift/cli/_megatron/main.py:16) - [cli_main()](swift/cli/_megatron/main.py:16) 函数处理megatron命令路由
1.
- SFT命令处理:
[swift/cli/_megatron/sft.py](swift/cli/_megatron/sft.py:5) - 调用 [megatron_sft_main()](swift/megatron/train/sft.py:71)
1.
- 参数解析核心:
[swift/utils/utils.py](swift/utils/utils.py:143) - [parse_args()](swift/utils/utils.py:143) 函数使用HuggingFace的HfArgumentParser进行参数解析
1.
- 参数类定义:
[swift/megatron/argument/megatron_args.py](swift/megatron/argument/megatron_args.py:98) - [MegatronArguments](swift/megatron/argument/megatron_args.py:98) 类包含所有megatron特定参数[swift/megatron/argument/train_args.py](swift/megatron/argument/train_args.py:16) - [MegatronTrainArguments](swift/megatron/argument/train_args.py:16) 类继承BaseArguments和MegatronArguments-
[swift/llm/argument/base_args/base_args.py](swift/llm/argument/base_args/base_args.py:54) - [BaseArguments](swift/llm/argument/base_args/base_args.py:54) 类包含基础参数
后端执行逻辑位置:
- 训练流程入口:
[swift/megatron/train/sft.py](swift/megatron/train/sft.py:71) - [megatron_sft_main()](swift/megatron/train/sft.py:71) 函数
1.
- 训练器实现:
[swift/megatron/trainers/base.py](swift/megatron/trainers/base.py:29) - [BaseMegatronTrainer](swift/megatron/trainers/base.py:29) 类包含完整的训练逻辑
1.
- 具体训练步骤:
[swift/megatron/trainers/trainer.py](swift/megatron/trainers/trainer.py:22) - [MegatronTrainer](swift/megatron/trainers/trainer.py:22) 类实现forward_step和loss_func
1.
- 训练执行:
[swift/megatron/trainers/base.py](swift/megatron/trainers/base.py:441) - [train()](swift/megatron/trainers/base.py:441) 方法启动训练流程
1.
整个流程是:命令行参数通过HfArgumentParser解析到对应的dataclass中,然后传递给训练器进行模型训练。Megatron相关的参数在MegatronArguments类中定义,训练逻辑在BaseMegatronTrainer中实现。
纯Megatron
https://huggingface.co/blog/zh/megatron-training
megatron里微调一个大模型基本上可以分为以下几个步骤:
1)从huggingface下载大模型的权重;
2)使用大模型转换脚本将该权重从Huggingface格式转换为megatron格式;
3)基于这个转换后的权重设置微调参数,然后开始微调;
4)最后保存微调好的权重。
这里转换:
1
2
3
4
5
6
7
8
9
10
| python tools/checkpoint/convert.py \
--model-type GPT \
--loader qwen \
--saver megatron \
--checkpoint-type hf \
--load-dir /path/to/qwen/hf/model \
--save-dir /path/to/megatron/checkpoint \
--target-tensor-parallel-size 2 \
--target-pipeline-parallel-size 2 \
--tokenizer_type /path/to/qwen/tokenizer
|
- 数据集的转换:格式是?
- 模型格式的转换:就用swift去转换
- 训练的指令
参考llama的例子:https://github.com/NVIDIA/Megatron-LM/tree/main/examples/llama(适用?
好像没看到有纯megatron去跑的例子
千问的例子:https://gitee.com/ascend/MindSpeed-LLM/blob/4c537a909d3334f5afc5fbf18f1192b42c124421/examples/qwen/README.md
只不过是昇腾的
这里工作量有点大,没必要
放弃,专用swifit or llama-factory
评测基建
对于微调过程,需要进行评测