Agentic RL
转自:https://zhuanlan.zhihu.com/p/1913905349284591240
通过蒙特卡洛树搜索、过程监督与结果监督、强化学习来提高 LLM 的推理能力,从本质上来说,都是尽可能榨取 LLM 本身的能力,区别可能在于多次尝试、反馈信号、训练方法而已,这类方法可称之为“求诸内”。而由 scaling law 可知,模型的能力是有限的,那么该如何进一步提高LLM在具体问题上的表现呢?近期的答案是,类似 RAG,Multi-Agent 系统,让 LLM 学会使用工具,毕竟人与动物的关键区别也只是“能制造并使用工具”,这种方式则是“求诸外”。那么本篇就以此为中心,重点讨论以下问题:
- Agentic LLM 的算法逻辑、具体方法与实际表现?
- RL 如何训练 Agentic LLM,其与 tool using 的 SFT 的差异在哪?
- Agentic RL 的工程化问题
一、Agentic RL 的算法设计
Agent 和 RL 都并非新鲜事物,而使用 RL 训练基于 LLM 的 agent 则是近期的研究的热点,那么,从算法角度来说,如何理解二者结合的动机、场景、效果、局限性,如何使用这种方式解决具体问题,将是本节讨论的重心。
1.1 Agentic LLM:前 RL 时代
本质上,任何对 LLM 的 RL 训练都可以通过构建数据集通过 SFT 来得到等价效果,换言之,当我们试图理解 Agentic RL 时,先理解 Agentic LLM 将是非常有必要的。
1.1.1 Agentic LLM 案例讨论
考虑一个简单的数学问题:524652242 x 868643532 , 如果使用纯文本没有竖式的条件下,计算该结果无疑是困难的,而对人类来说通常不会觉得该问题很困难,因为使用计算器就可以直接得到结果。 对于 LLM 来说也是如此,在此之前就已经有许多工作采用 Tool-integrated Reasoning (TIR) 来解决数学问题,下面通过 Qwen-Agent 来看在 Qwen2.5-Math 模型上是如何工作的
1 | from qwen_agent.agents import TIRMathAgent |
输出结果如下所示:
1 | To solve the integral of \( x^2 + x^{-1} \) from 1 to 2, we can follow these steps: |
以上过程实际上包含3个主要环节 (执行细节可参考 test_qwen_agent_tir.ipynb):
- LLM 生成,分析问题并生成解决该问题的代码段;
- 代码执行,解析出代码段并通过代码解释器或沙箱执行代码并返回结果;
- LLM总结,将代码段结果拼接到第一步的结果后再次输入到 LLM 中总结输出最终结果
以上是非常顺利的情况,正常情况可能会出现代码执行错误等问题,需要多轮执行以上过程。
通过构造数据,可以比较简单通过 SFT 得到以上结果,但从算法角度来看,还存在以下问题:
- 路径依赖,使用 CoT 还是 TIR 是由 system_prompt 来决定的,LLM 无法自主决定选用哪种方式;
- 数据分布,如果使用过多此类 SFT 数据,可能会过拟合,数据量太少又会过于稀疏;
这也是将 Agent 与 RL 结合起来的主要动机,在1.2节中将讨论结合的典型做法与案例。“工欲善其事,必先利其器”,在此之前,我们不妨先来看一下工具的使用方法,主要是代码执行工具的用法。
1.1.2 代码执行工具探索
LLM 本身是无法执行代码的,想要得到模型输出代码的结果,则需要专门的代码执行单元(解释器或编译器),本节将介绍几种典型的实现方式。
(1)自实现代码解释器
上文演示的 Qwen-Agent 即采用这种方式,简单示例如下:
1 | from qwen_agent.tools.python_executor import PythonExecutor |
该方式优缺点都非常明显,优点在于性能好、可解释性强,缺点在于需要为每一种编程语言单独开发,通用性不高。
(2)服务化沙箱
该方式比较直接,即将代码执行器封装成一个服务,通过调用的形式来执行代码。其优点在于代码无耦合可以单独优化、异步服务可同时支持多个交互,其缺点就是增加网络的延时成本。沙箱的实现也有多种方式,以下介绍几种常见的:
- 使用 e2b_code_interpreter
实现过程可参考 e2b_router.py ,服务过程可参考 routed_sandbox.py ,测试案例如下:
1 | sbx = RoutedSandbox(router_url="0.0.0.0:8001") |
输出结果如下:
1 | [Execution(Results: [], Logs: {'stdout': ['hello world\n'], 'stderr': []}, Error: None), Execution(Results: [], Logs: {'stdout': ['4.0\n'], 'stderr': []}, Error: None)] |
- 使用 morphcloud
实现过程可参考 morph_router.py,服务过程可参考 routed_morph.py,感兴趣可自行测试。
- 使用 Sandbox Fusion
Bytedance 提供的一站式代码执行服务,详情及用法可参考 SandboxFusion 。
至此,Agent + RL 的各项要素都已齐备,可以开始正式的探索了。
1.2 Agent + RL: 1+1>2
1.2.1 核心思想与相关案例
从算法逻辑上来说,Agent + RL 的目的就是解决 1.1.1 小节中提出的路径依赖和数据分布的问题:
- 通过让 LLM 在训练过程自主选择合适的工具,从而避免对 prompt 的依赖,而自适应解决问题
- 通过多轮 RL 可以提高 LLM 的探索程度,以弥补 SFT 数据的稀疏不足或者过多重复的问题
近期也出现较多这方面的工作,一下仅列举部分有代表性的案例:
| 工作 | 时间 | 场景 | Owner | 相关链接 |
|---|---|---|---|---|
| ToRL | 2025.3 | Math | SJTU GAIR | https://arxiv.org/pdf/2503.23383 |
| OTC | 2025.4 | Math | NTU, Skywork | https://arxiv.org/abs/2504.14870v1 |
| retool | 2025.4 | Math | ByteDance | https://arxiv.org/pdf/2504.11536 |
| ZeroTIR | 2025.5 | Math | FDU, XHS | https://arxiv.org/abs/2505.07773 |
| Nemotron-Tool-N1 | 2025.5 | General | NVIDIA | https://arxiv.org/pdf/2505.00024 |
| ARTIST | 2025.5 | General | Microsoft | https://arxiv.org/pdf/2505.01441 |
| SkyRL-SQL | 2025.6 | Text2SQL | Skywork | https://novasky-ai.notion.site/skyrl-sql |
| Kimi-Researcher | 2025.6 | General | Moonshot | https://moonshotai.github.io/Kimi-Researcher/ |
| verl-agent | 2025.6 | General | NTU | https://github.com/langfengQ/verl-agent |
| simpleTIR | 2015.7 | General | NTU | https://simpletir.notion.site/report |
与前文分析得一致,该方式在具体问题上也表现出了明显的效果提升,如下 ToRL 在 Math 上的结果
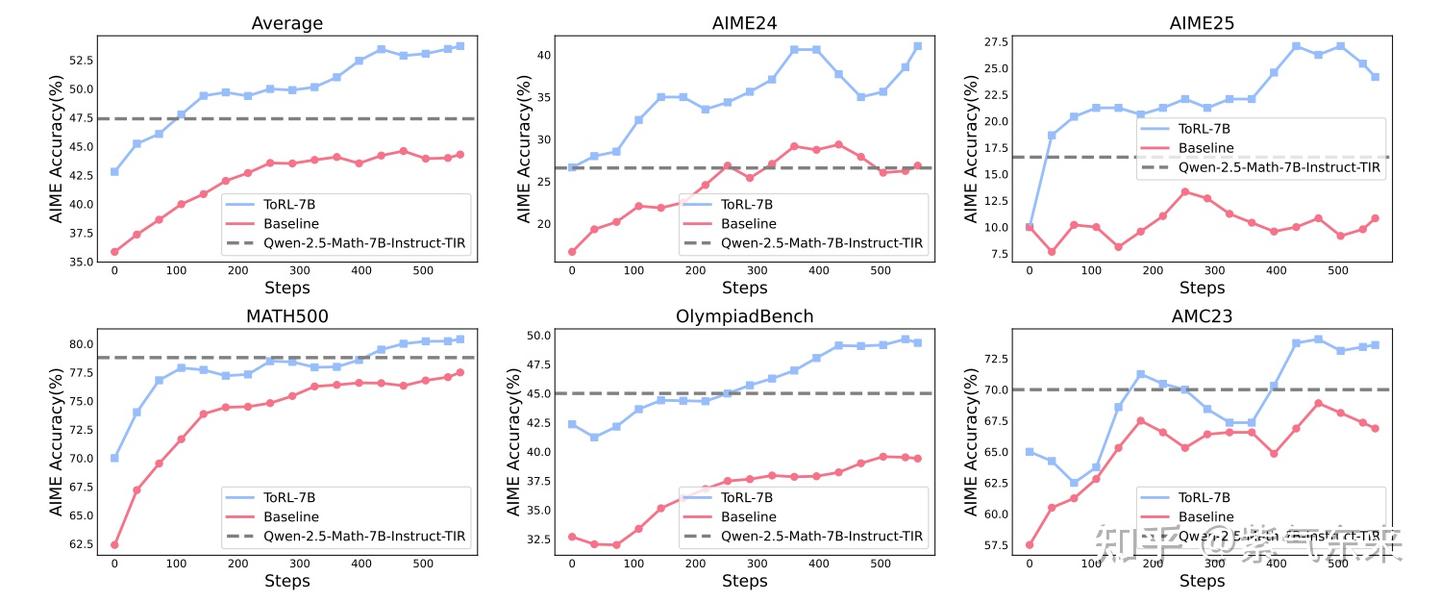
当然,采用这种方式要达到预期效果,还有一些事项需要注意,包括:
- 在 RL 训练初始阶段,LLM 各种工具使用的初始能力,并有相当概率选中其中每一条路径;
- 训练 RL 的数据应有明显的区分度,应避免多种选择下反馈结果差异不明显的情况;
- 对于路径的选择更加接近传统 RL 中的 action 的概念,与当前的 token-level 的 reward 的计算方式可能会有所不同,需要适应性调整
1.2.2 Agent + RL 实现逻辑
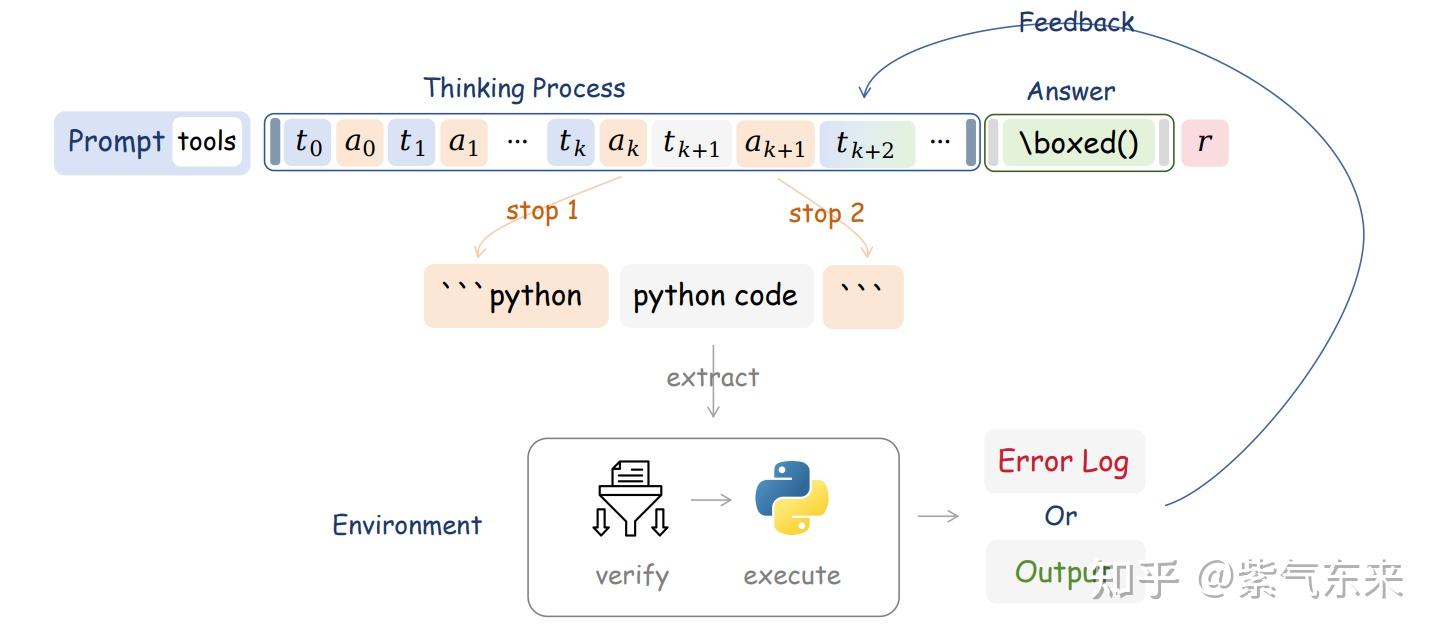
从算法角度来说,在现有 RL 基础上实现 Agent 训练并不复杂,只需要在 rollout 的生成环节增加工具调用与执行即可,即算法可描述为

这里单独解释一下这个算法流程:
该算法描述了一个结合强化学习(RL)与代码执行的智能体训练框架,核心思想是在传统的RL rollout(轨迹生成)过程中动态插入代码调用与执行,以增强智能体的解决问题能力。以下是分步解析:
算法核心逻辑
-
初始化
- 输入参数:策略模型
π(如语言模型)、初始提示P、代码执行环境E、最大代码调用次数N。 - 变量初始化:上下文
C初始化为提示P,轨迹T为空,代码调用计数器k=0。
- 输入参数:策略模型
-
循环生成与执行
算法进入无限循环,持续生成文本直至满足终止条件:-
Step 3-6:生成基础内容
- 调用
π.GENERATE生成一个 tokens及其类型σ,允许的终止符为{EOS, /boxed{}}或 Python 代码标记"python"。 - 将生成的
s追加到上下文C和轨迹T中。 - 若
σ是终止符(如完成生成或数学公式标记),直接返回当前轨迹T。
- 调用
-
Step 7-9:触发代码调用
- 若生成的
σ是"python",表示需要调用代码:- 计数器
k自增 1,若超过预设的调用次数N,强制返回轨迹T(防止无限循环)。
- 计数器
- 若生成的
-
Step 10-15:执行代码并反馈结果
- 继续生成代码内容
c(忽略终止符),追加到C和T。 - 执行代码
c并获取结果r(通过E.Exec(EXTRACT(c)))。 - 将结果
r格式化为文本FMT(r)并转换为 token 序列TOKENS(r),反馈到上下文C和轨迹T中。
- 继续生成代码内容
-
关键机制解析
-
动态代码调用
- 智能体在生成文本时,可自主决定何时插入 Python 代码(通过生成
"python"标记),实现“按需调用”。 - 代码执行结果被实时整合回生成过程,形成“生成-执行-反馈”的闭环。
- 智能体在生成文本时,可自主决定何时插入 Python 代码(通过生成
-
终止条件
- 自然终止:生成
EOS(结束符)或/boxed{}(数学公式闭合标记)。 - 强制终止:代码调用次数超过预算
N。
- 自然终止:生成
-
代码执行安全与控制
EXTRACT(c)用于从生成的文本中提取有效代码片段。FMT(r)和TOKENS(r)分别负责格式化结果并转换为模型可理解的 token 输入。
应用场景示例
假设智能体需要解决一个数学问题:
- 生成部分文本后,检测到需要计算某个表达式,生成
"python"标记。 - 继续生成代码
c = "print(2+2)",执行后得到结果4。 - 将
4格式化为文本并追加到上下文,后续生成直接引用结果完成答案。
优势与挑战
- 优势:
- 结合符号推理(代码执行)与生成模型,突破纯文本生成的局限性。
- 动态调用外部工具,提升解决复杂任务的能力(如计算、数据查询)。
- 挑战:
- 需要设计安全的代码执行环境
E,防止恶意代码注入。 - 策略模型
π需学习何时调用代码的时机,可能增加训练复杂度。
- 需要设计安全的代码执行环境
总结
该算法通过在 RL 的 rollout 过程中嵌入代码生成与执行,实现了“思考-行动-观察反馈”的智能体行为模式。其核心创新在于将代码作为动作空间的一部分,利用执行结果优化后续决策,适用于需要结合符号操作与生成能力的场景(如数学问题求解、自动化脚本编写等)。
ToRL 在 verl 基础上,非常清晰实现了以上过程,完整代码可参考 https://github.com/GAIR-NLP/ToRL/blob/main/verl/workers/rollout/vllm_rollout/vllm_rollout_spmd.py ,核心代码如下:
1 | def _tir_generate(self, prompts=None, sampling_params=None, prompt_token_ids=None, use_tqdm=False): |
另外,zeroTIR 是基于 OpenRLHF 的实现,具体可参考 https://github.com/yyht/openrlhf_async_pipline ,有兴趣的同学,非常建议实际体验一下。
二、 Agentic RL 的工程问题
尽管从算法层面,Agent + RL 显得比较自然直接,且并不难实现,但是却带来了一些工程问题。从本质上来说,工程的目标即是在精度约束下实现性能(效率)的提高,本节将讨论 Agentic RL 对计算效率的影响,以及改进的方法。
2.1 RLHF 的计算过程与 timeline
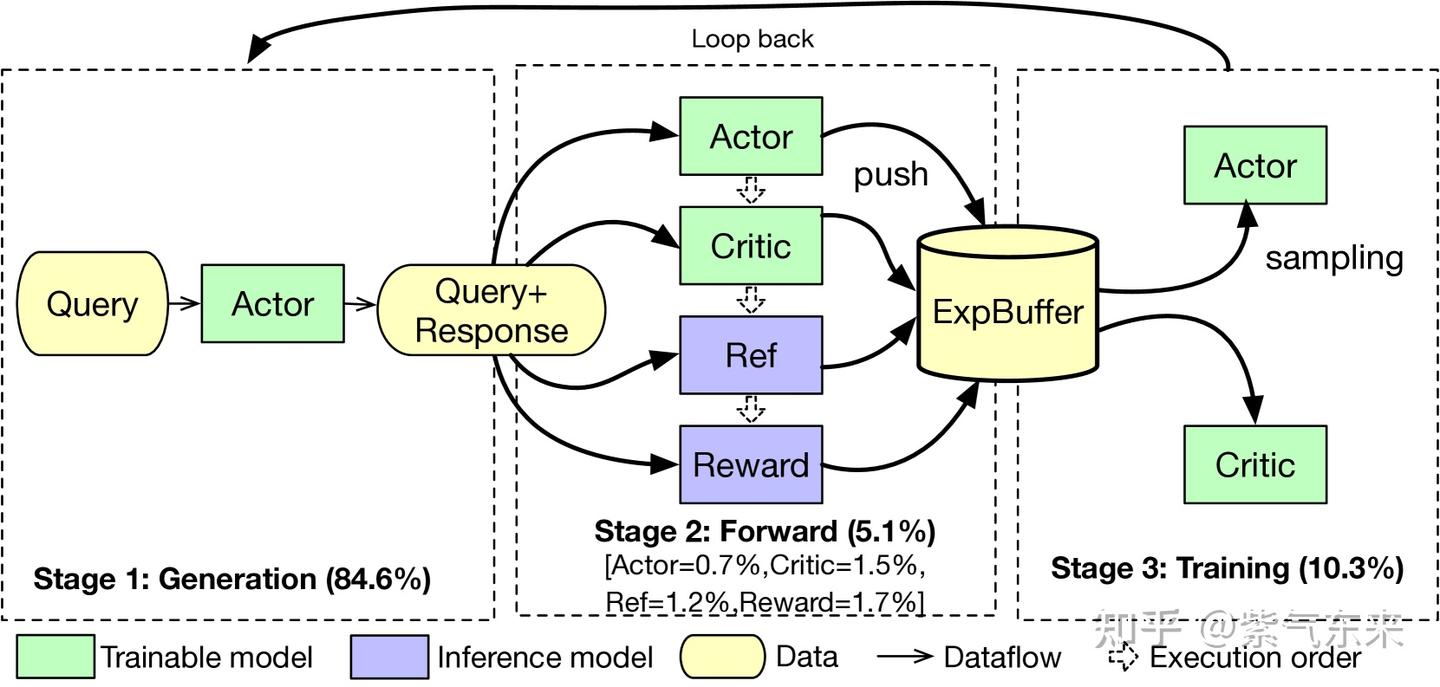
以基础的 PPO 算法为例,系统总共有4个模型,分别是 Actor、Critic、Ref、Reward 模型。从计算角度来看,可以分为 3 个阶段:
- Generation: 输入 prompt,Actor 产生 response 的过程, 由于 LLM 的 token by token 的生成方式及文本长度的因素,该过程会消耗大量的推理资源,并占用较多时间;
- Forward: 产生的 response 会和 query 一起传给 Actor、Critic、Ref、Reward 这4个模型执行 one-pass forward,forward的数据会放在 Experience Buffer 中, 该步和上一步通常被合称为 rollout;
- Training: 从 Experience Buffer 中取数据对 Actor、Critic去进行训练
由于涉及的模型较多,也出现众多分布式策略,包括平铺策略、交错策略、训推分离策略、时分共用策略(即colocate),为简便起见,本节则以 colocate all 为例来介绍和分析不同生成方式的 timeline。
最基础的生成方式即是以 transformers 为代表的朴素的 batch 的生成方式,该方式需要等待一个batch同时生成完成时结束,如下图所示:
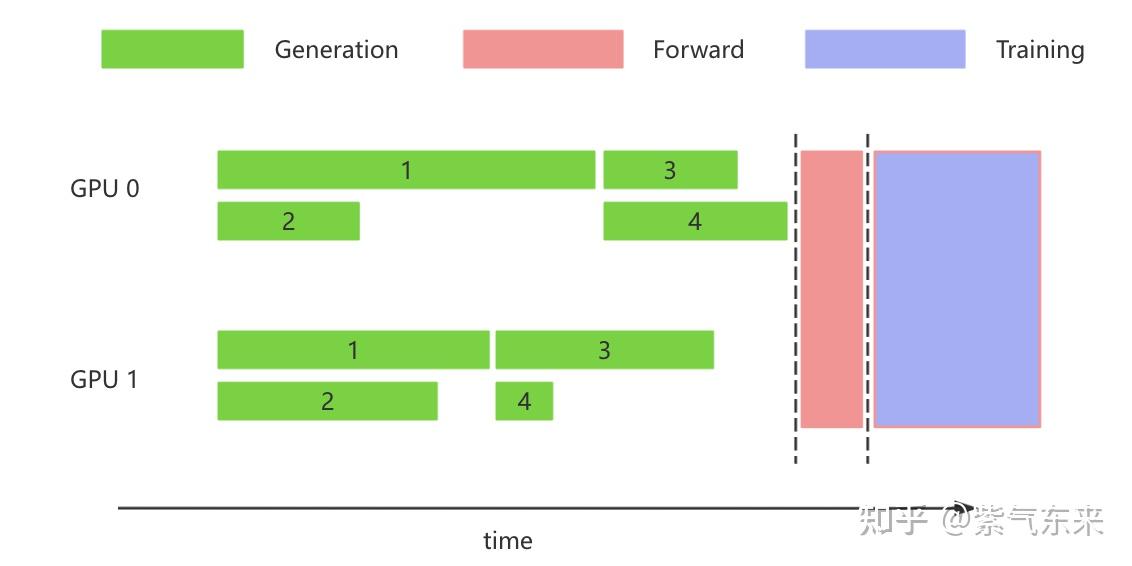
naive HF generation
为了提高生成效率,常见的做法是利用 vLLM, SGLang 等推理框架,其中集成了各个层面的优化,仅从 batch 的角度来看,其中 dynamic batch 就能够显著缩短总的生成时间
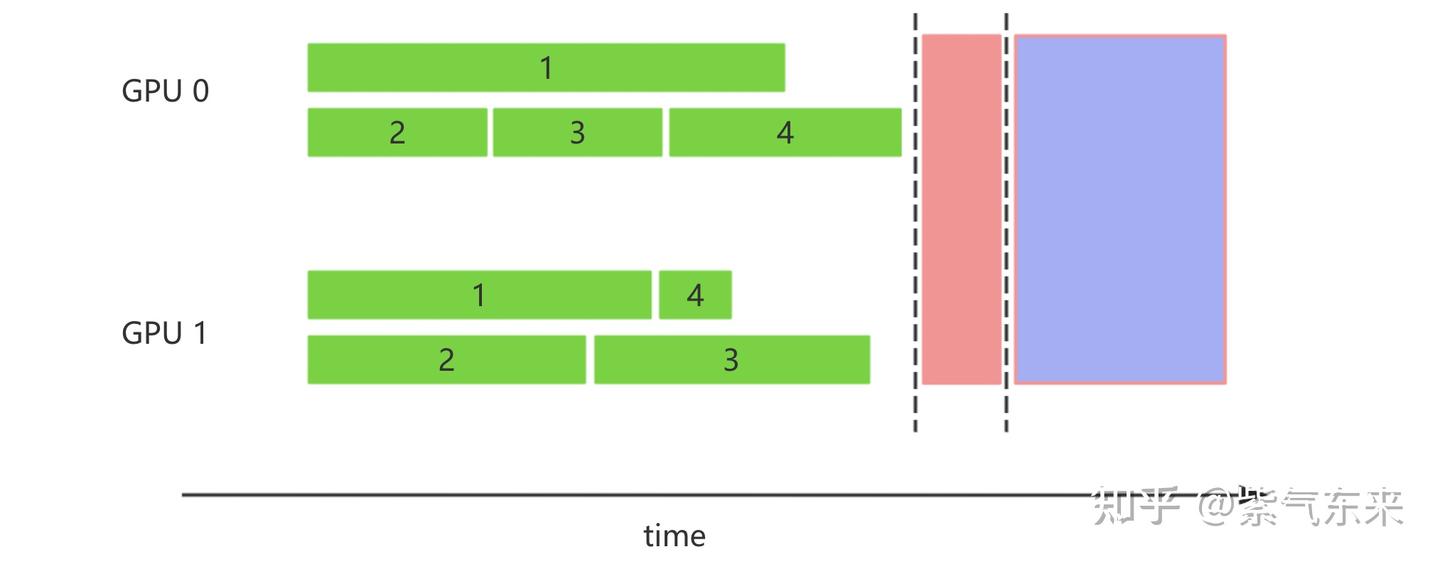
dynamic batch generation
当 agent 生成时,不同 prompt 不仅生成的长度不同,交互的次数也不同,因此之前的单轮就可得到结果的方式就不存在了,这样就需要完全异步的生成方式。
2.2 Agent 的影响与异步服务化
2.2.1 Agent 的对推理框架的需求
仍以 1.1 小节的例子为例,Agent 需要得到最终答案至少需要两次生成过程,通常在 2~10 次,这样就使得 timeline 发生明显变化。假设使用了带 dynamic batch 的推理框架,其主要过程为:所有请求会在起始时间全部发送给推理框架,收到请求后 scheduler 会根据 FIFO 原则进行调度,这样的话,如果需要多轮生成,第二轮生成需要等待第一轮全部结束才会开始,其 timeline 如下所示
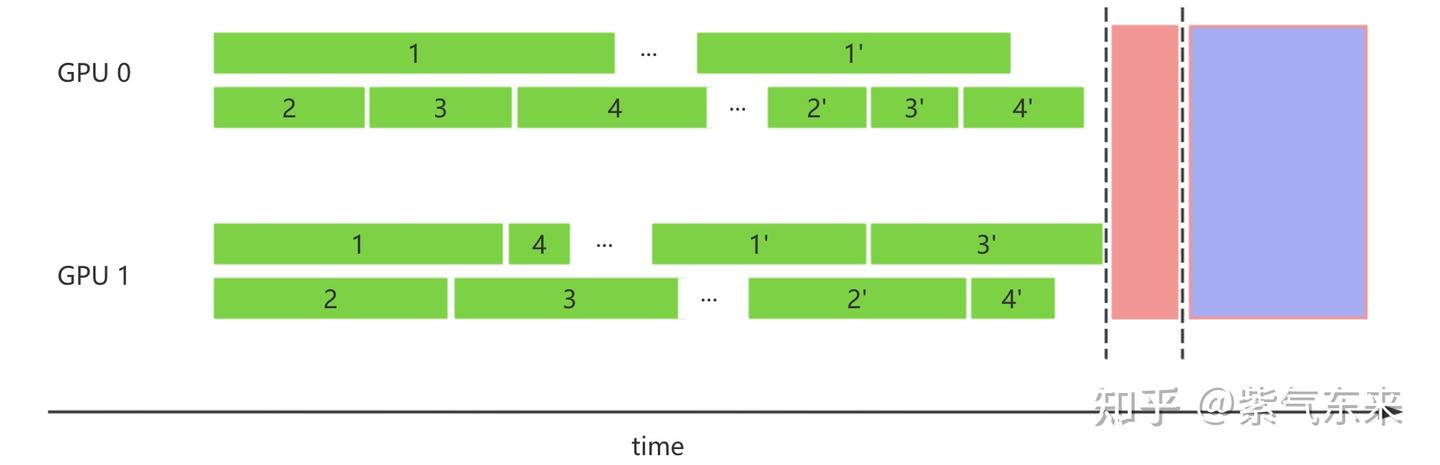
这样,如果 prompt 数量过多,或者生成轮次过多,都会导致解决单一问题的时间被极大拉长,非常不利于调试及分析过程,因此需要一种异步的方式,将请求在适当的时候逐条发送并调度计算,其 timeline 如下所示
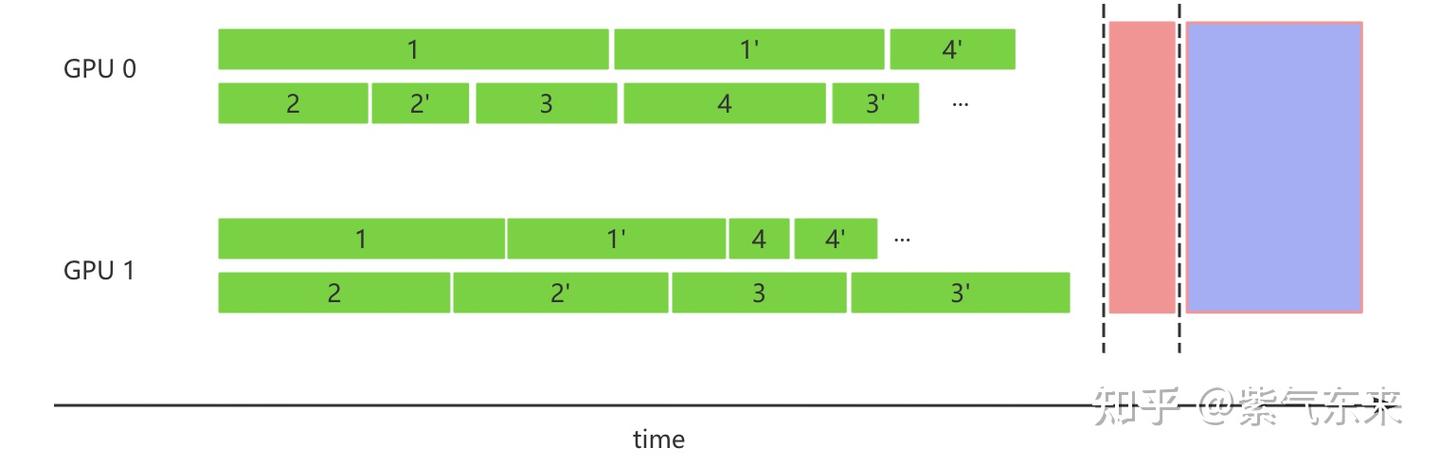
事实上二者的主要不同只是请求方式的变化,接下来将以 vLLM 的 AsyncLLM 来说明具体实现过程。
2.2.2 AsyncLLM 的核心思想与使用方法
简单来说, AsyncLLMEngine 就是将 LLMEngine 类封装为异步形式。它使用 asyncio 创建一个后台循环,持续处理传入的请求。当等待队列中有请求时,generate 方法会触发 LLMEngine。generate 方法将 LLMEngine 的输出传递给调用者。
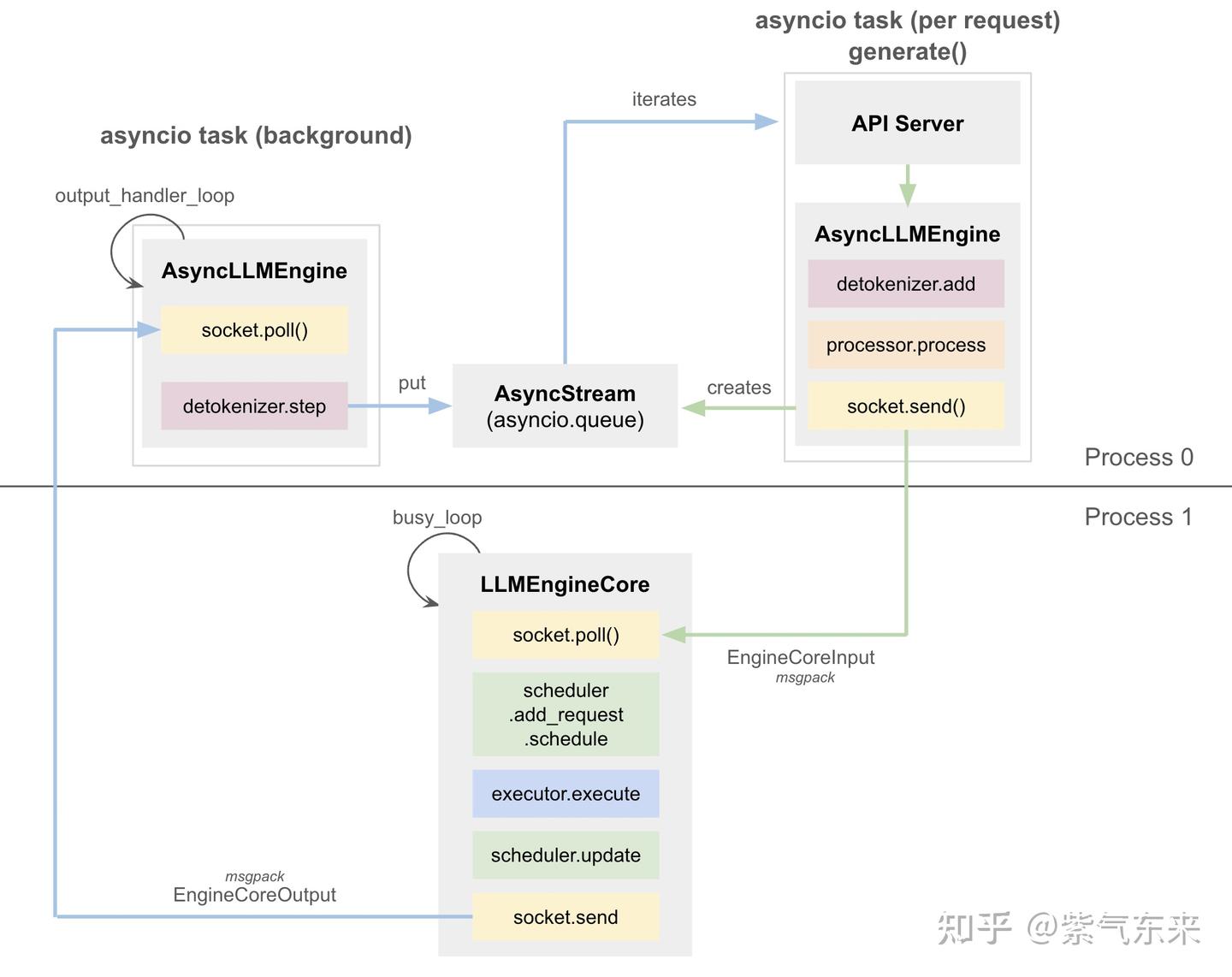
为避免过于繁琐,本文将不会对推理框架的细节进行剖析,感兴趣的可以自行研究。理解了以上核心思想就足够了,如果想要自己构建一个异步的推理引擎,那么直接用AsyncLLM + async就可以了,当然也可以在外层包装成一个APIServer,例如 verl 中的 AsyncvLLMServer 的实现。
这样我们就完成了异步的生成过程,当然 forward 中的计算过程即单步的推理过程,也可采用类似的方式来实现,当然如果采用验证器的reward,可以按照1.2.2小节的方式做成异步服务即可。训练及其他部分兼容之前的训练方式。
2.2.3 思考、讨论与展望
Agentic LLM 的复杂交互需求催生了异步的生成方式,这与经典 RL 的很多场景已经变得非常类似,从更宏观的视角来看,异步的方式不仅限于生成的过程中,也可以用于生成和训练的关系中。
在 AReaL 实现了中一个纯异步的方案,即解耦生成和训练,分别在独立的 GPU 集群上运行。生成节点持续生成新输出而不等待,而训练工作节点在收集到一批数据时随时更新模型。
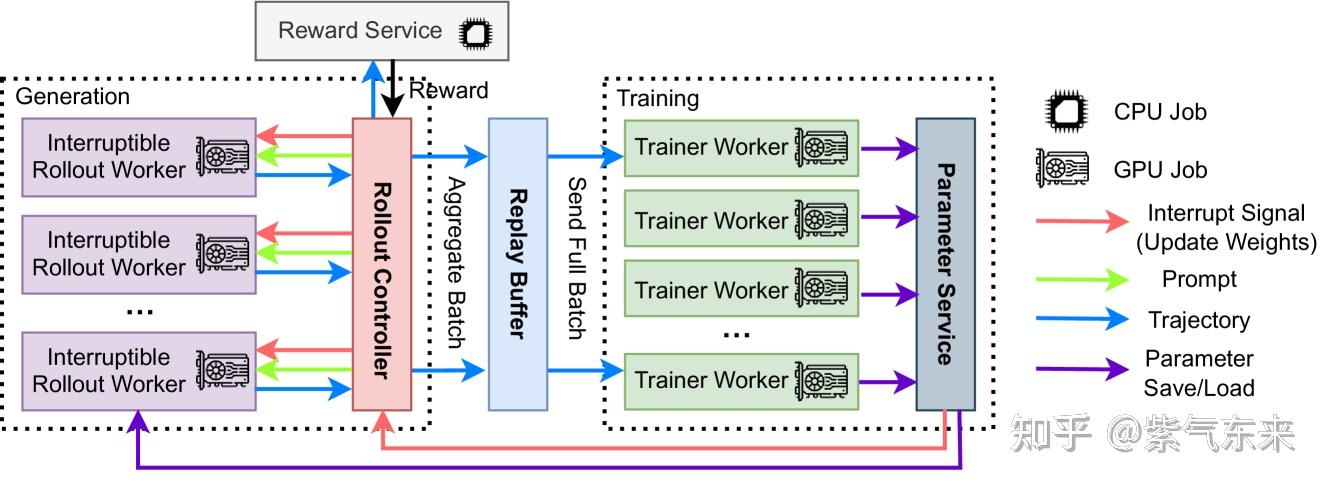
其 timeline 如下所示,需要说明的是其中断逻辑:更新权重请求会中断所有正在进行的生成,并加载新版本的模型。在中断时,rollout 工作器会丢弃由旧权重计算出的 KV 缓存,并使用新权重重新计算它们。之后,rollout 工作器会继续解码未完成的序列,直到下一次中断或终止。

当然这种方式也会带来新的问题:即当前产生的样本可能并不来源于上一个版本的策略,可能来源于更早版本的策略,所幸的是因为有基础模型的大量训练以及 KL 散度的约束,不同版本之间的差异并不明显,因此只需要约束版本差异的范围即可。
以上观点在其他工作中也能得到证明,在 ProRL 中,Reset Point 即模型同步,在参数无明显变化时,由于“熵坍”,而使得多个版本的模型差异不大。
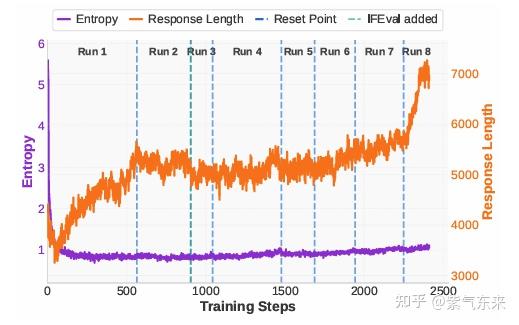
事实上,极致的异步就是 off-policy,而 off-policy 则有更高的样本效率,从另一方面来了,off-policy 本质等同于 SFT 和 DPO,这样 SFT 与 RLHF 的概念又再次被模糊,并且已经有许多工作更严谨地证明了这一点,例如 Bridging Supervised Learning and Reinforcement Learning in Math Reasoning
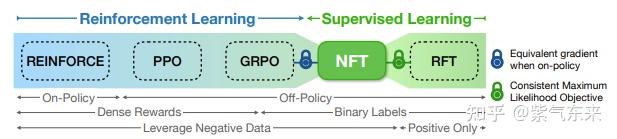
因此最终的形态可能,根据具体的场景,进行效果、成本等多方面的平衡和综合。欢迎大家提出自己的看法。
参考资料
[2] Get Started | Sandbox Fusion
[3] https://github.com/TIGER-AI-Lab/verl-tool
[4] ToRL: Scaling Tool-Integrated RL
[5] Nemotron-Research-Tool-N1: Exploring Tool-Using Language Models with Reinforced Reasoning
[6] Agent RL Scaling Law: Agent RL with Spontaneous Code Execution for Mathematical Problem Solving
[7] OTC: Optimal Tool Calls via Reinforcement Learning
[8] Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning
[9] An Adaptive Placement and Parallelism Framework for Accelerating RLHF Training
[10] OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
[11] HybridFlow: A Flexible and Efficient RLHF Framework
[12] AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning