Memory OS of AI Agent
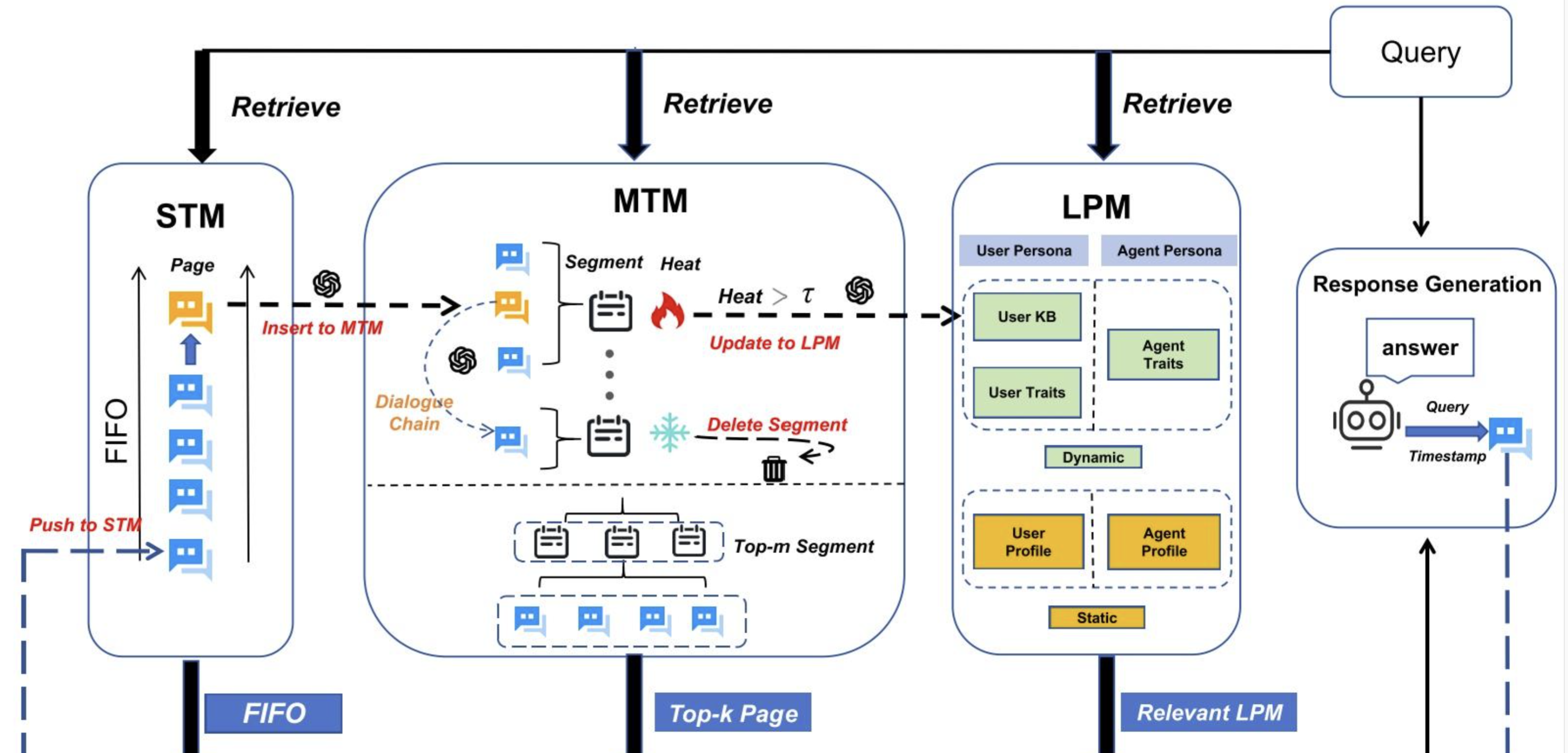
Memory OS of AI Agent 初读-1 北邮和腾讯nlpAI 受传统操作系统内存管理机制的启发,MemoryOS 构建了一套分层存储体系,由四个核心模块组成:记忆存储、更新、检索与生成。 该体系架构包括三个层级的记忆单元:短期记忆(STM)、中期记忆(MTM) 和 长期个性记忆(LPM) MemoryOS 支持关键的动态迁移操作: 短期向中期的更新遵循基于对话链的 FIFO 策略,而中期向长期的迁移则采用分段分页的组织方式,以提升记忆的可维护性和检索效率。 分4个模块: memory storage:将信息组织成短期、中期和长期存储单元 memory updating:通过基于对话链和基于热度的机制的分段分页体系结构动态刷新 memory retrieval:利用语义分段来查询这些层 response generation:将检索到的内存信息集成起来,以生成一致的个性化响应 现有技术分类: 1.knowledge-organization: 这类方法关注的是如何组织和保留模型的中间推理状态。更关注记忆的“结构”和“语义关系”,让模型能追踪自己是怎么想的,而...
ITBench:Evaluating AI Agents across Diverse Real-World IT Automation Tasks
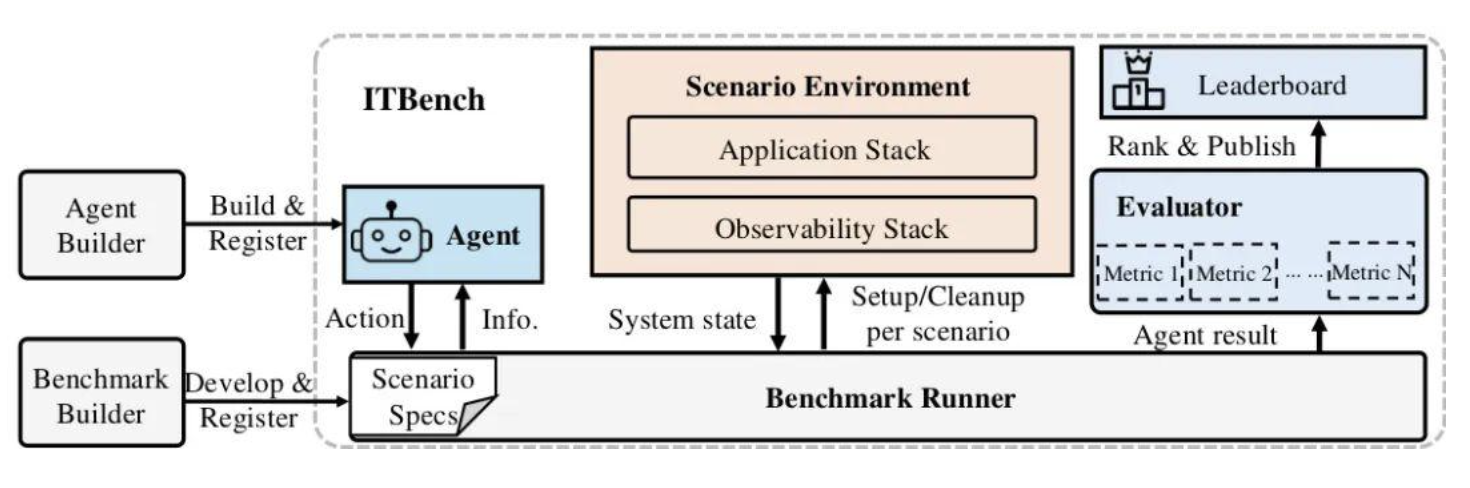
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks 1. 研究背景与核心问题 本文介绍了ITBench,一个用于评估AI代理在真实世界IT自动化任务中表现的基准测试框架。随着现代IT系统复杂性不断增长,尤其是微服务和无服务器计算架构的普及,IT可靠性挑战日益严峻。尽管大型语言模型(LLMs)和AI代理被广泛尝试应用于IT自动化领域,但其实际效能缺乏系统性评估。 研究指出,尽管在IT自动化领域已有大量研究(包括故障检测、诊断、缓解等),但"完全自动化事件解决或向人类提供可行见解仍然难以实现",主要挑战在于: 真实系统的复杂性 事件的多变性 将上下文知识整合到AI系统中的困难 2. ITBench框架设计 2.1 框架定位与目标 ITBench是一个开源框架,旨在: 为研究人员和从业者提供评估AI代理在IT自动化任务中表现的标准基准 模拟真实IT环境,使代理能够与系统交互并执行任务 促进IT领域AI驱动自动化的创新,确保其"正确、安全、快速&quo...
深入 FastMCP 源码:认识 tool()、resource() 和 prompt() 装饰器
深入 FastMCP 源码:认识 tool()、resource() 和 prompt() 装饰器 在使用 FastMCP 开发 MCP 服务器时经常会用到 @mcp.tool() 等装饰器。虽然它们用起来很简单,但当作黑匣子总让人感觉"不得劲"。接下来我们将深入相关的源码实现,别担心,不会钻没有意义的“兔子洞”,你可以通过这篇文章了解到: 如何简单启动本地的 MCP Server 和 MCP Inspector 这些装饰器具体做了什么 @mcp.tool() @mcp.resource() @mcp.prompt() MCP 官方 Python SDK 地址:https://github.com/modelcontextprotocol/python-sdk。 代码文件下载:server.py,debug_func_metadata.py 安装库 需要注意的是,Python>=3.10 才可以安装 MCP: 1pip install mcp server.py 下面是一个简化的 server.py 示例: 123456789101112131...
LIMR解读
LIMR解读 之前已经有很多文章研究「如何用少量精选数据提升LLM效率」这个话题了,包括之前媒体声量很大的s1和LIMO,这些工作的核心观点就是——Less is More,数据质量 > 数量。 LIMR这篇论文可以看做这种思想的延续,不过关注的点在与RL,而不是SFT。这篇论文对我来说,最有意思的点是,「如何衡量哪些数据好呢」?作者给出了一个指导思想:好的训练样本应该与模型的整体学习轨迹对齐。通俗地解释一下,这就是一种「同步进化」的思想,即高价值样本的奖励变化需要与模型能力提升同频共振。就像教学生数学,要选择那些当前稍难,但通过练习就能掌握的题目(样本A),而不是一直做简单题(样本B)或超纲题(样本C)。 实验目前做的还不是很完善,论证链条有待进一步加强。 论文与代码:GitHub - GAIR-NLP/LIMR 主要内容 1. 作者和团队信息 作者:Xuefeng Li, Haoyang Zou, Pengfei Liu。 团队:来自上海交通大学 (SJTU), 上海人工智能研究院 (SII), 通用人工智能研究院 (GAIR)。 主要贡献者:Pengfei Liu...
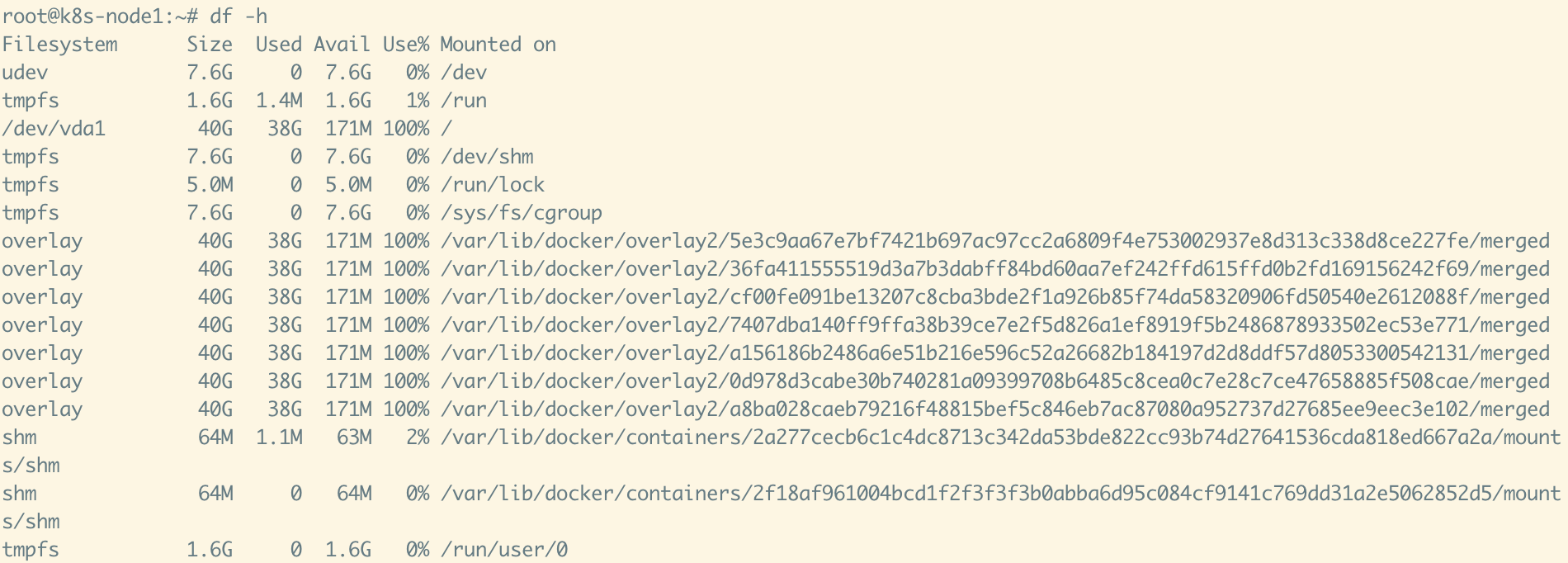
Linux 云服务器根分区扩容流程(ext4 示例)
Linux 云服务器根分区扩容流程(ext4 示例) 1. 云厂商控制台扩容磁盘 登录云服务商(AWS、阿里云、腾讯云等) 找到对应实例的 系统盘 / 数据盘 修改磁盘大小,例如从 40G → 80G 这一步完成后,虚拟磁盘 /dev/vda 就会变大,但分区和文件系统不会自动变大 2. 确认磁盘和分区情况 12lsblkdf -h lsblk 会显示磁盘和分区大小 df -h 会显示文件系统挂载的空间大小 例子: 12vda 80G└─vda1 40G / 👉 说明磁盘是 80G,但分区还只有 40G 3. 安装扩容工具 (Ubuntu/Debian) 12sudo apt updatesudo apt install -y cloud-guest-utils (CentOS/RHEL) 1sudo yum install -y cloud-utils-growpart 4. 扩展分区 1sudo growpart /dev/vda 1 /dev/vda → 磁盘名 1 → 分区号(即 /dev/vda1) 执行后再看: 1lsblk 应该变成: ...
Pass@k作为reward可以有效平衡探索与利用
Pass@k作为reward可以有效平衡探索与利用 https://zhuanlan.zhihu.com/p/1940934363450672938 这篇感觉和https://www.arxiv.org/abs/2504.13837 有点矛盾 主流的基于强化学习的推理模型训练(RLVR)方法通常使用 Pass@1 作为优化目标和奖励信号。这导致模型倾向于“保守”地利用已知的有效推理路径,而缺乏探索新路径的动力,容易陷入局部最优,限制了性能提升。 论文提出的方法:Pass@k 训练 为了解决上述问题,论文提出了一种新的训练方法——Pass@k 训练。 核心思想: 将广泛用于代码生成评估的 Pass@k 指标直接用作 RLVR 训练的奖励信号。Pass@k 衡量的是模型在 k 次尝试内至少成功一次的概率。 奖励机制: 在训练中,模型为每个问题生成 N 个候选答案。将这些答案分成若干组(每组 k 个,可通过完全采样、自助采样或解析方法构建)。如果某一组内至少有一个答案正确,则该组获得正向奖励(例如 1),否则为负向奖励(例如 0)。该组的奖励(或计算出的优势值)会平均分配给组内的所有...
UI-R1:通过强化学习增强GUI代理的动作预测能力
UI-R1:通过强化学习增强GUI代理的动作预测能力 最近的DeepSeek-R1展示了通过基于规则的强化学习(RL)在大型语言模型(LLMs)中涌现出的推理能力。基于这一理念,我们首次探索了如何利用基于规则的RL来增强多模态大语言模型(MLLMs)在图形用户界面(GUI)动作预测任务中的推理能力。 为此 我们精心整理了一个包含136个具有挑战性任务的小而高质量的数据集,涵盖了移动设备上的五种常见动作类型。 我们还引入了一种统一的基于规则的动作奖励机制,使模型可以通过基于策略的算法(如组相对策略优化(GRPO))进行优化。 实验结果表明,我们提出的数据高效模型 UI-R1-3B 在领域内(ID)和领域外(OOD)任务上都取得了显著改进。具体来说,在ID基准测试 AndroidControl 上,动作类型准确率提高了 15% ,而定位准确率提高了 10.3% ,相较于基础模型(即Qwen2.5-VL-3B)。在OOD GUI定位基准ScreenSpot-Pro上,我们的模型超越了基础模型,提高了 6.0% ,并实现了与更大模型(例如OS-Atlas-7B)相当的性能,这些模型是...
Web Agent综述
WebAgents综述:大模型赋能AI Agent,实现下一代Web自动化 https://finance.sina.cn/tech/csj/2025-08-08/detail-infkhmtz1833863.d.html?vt=4&cid=206650&node_id=206650 这篇文章是香港理工大学研究人员发表的首篇关于WebAgents的系统性综述,全面梳理了基于大模型的Web自动化智能体研究进展。 核心内容 背景与意义 互联网已深度重塑生活,但网络活动存在大量重复低效的"数字苦力"(如反复填写个人信息、手动比对商品参数) WebAgents能够根据用户自然语言指令自动完成复杂Web任务,实现网络活动的自动化与智能化 例如ChatGPT Agent能独立规划执行任务,无需用户持续监督 WebAgents架构 文章将WebAgents工作流程分为三个关键环节: 感知:观察环境 基于文本(利用HTML等) 基于视觉(利用截图) 多模态(结合文本与视觉信息) 规划与推理:分析环境并决策 任务规划(显式/隐式分解任务) 动作...
揭秘RLVR的真相:强化学习真的能提升大语言模型的推理能力吗?
揭秘RLVR的真相:强化学习真的能提升大语言模型的推理能力吗? 近年来,大型语言模型(LLM)在数学和编程任务中的推理能力取得了显著突破,而**基于可验证奖励的强化学习(RLVR:Reinforcement Learning with Verifiable Rewards)**被认为是这一进步的核心驱动力。RLVR通过自动计算奖励(如数学答案的正确性或代码的单元测试通过率),绕过了传统依赖人工标注的监督学习方法,被认为能够激励模型自我进化,甚至超越基础模型的推理能力边界。 然而,这篇由清华大学LeapLab团队领衔的研究却提出了一个颠覆性的问题:**RLVR真的能让模型学会全新的推理能力吗?还是仅仅在优化已有能力的采样效率?**通过大规模的实验和分析,研究团队发现,RLVR并未真正扩展模型的推理边界,反而可能限制其探索潜力。这一发现不仅挑战了当前对RLVR的主流认知,也为未来LLM的训练范式提供了新的思考方向。 论文地址:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond...
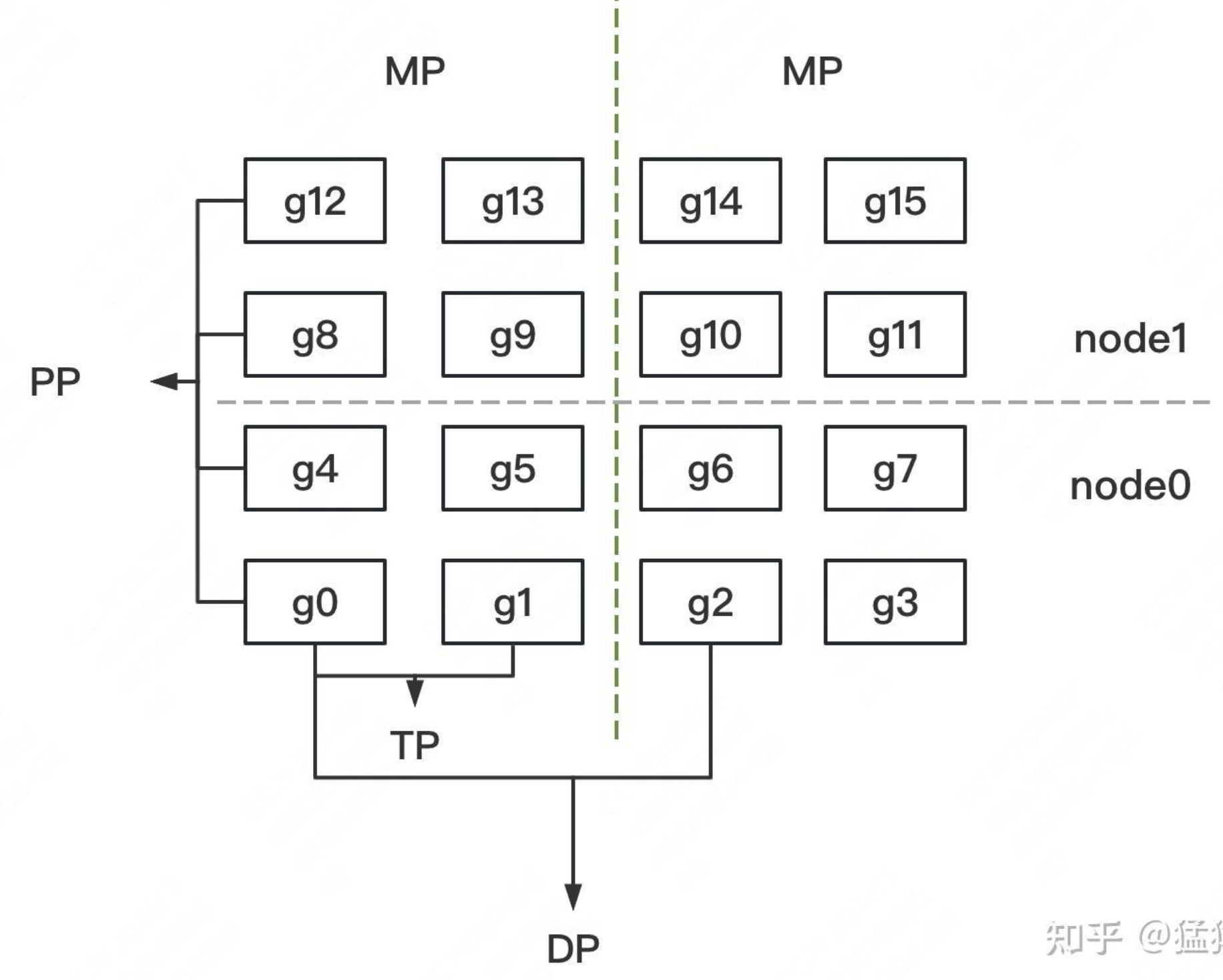
大模型混合并行DP/TP/PP,如何划分机器?
大模型混合并行DP/TP/PP,如何划分机器? 1 DP/TP/PP的通信量比较 在大规模深度学习模型的训练过程中,为了加速训练和减少单个计算节点的压力,通常会使用分布式训练技术。分布式训练涉及到几种并行策略,其中最常提到的是数据并行(Data Parallelism, DP)、模型并行(Model Parallelism, MP)和流水线并行(Pipeline Parallelism, PP)。另外,模型并行中还有一种称为张量并行(Tensor Parallelism, TP)的方式,它是指将模型的张量(如权重矩阵)分割到不同的设备上进行计算。 数据并行(DP):解决计算墙的问题。每个设备上都会有一个模型的完整副本,每个设备独立地处理一部分数据集,然后将各自的梯度汇总起来(通常是通过AllReduce操作)。因此,DP的通信主要发生在训练的每个epoch结束时,各个设备之间需要交换梯度信息。这种通信通常量较大,因为它涉及到模型所有参数的同步。 张量并行(TP):解决内存墙的问题。模型的权重矩阵被分割成多个部分,每个部分由不同的设备负责计算。TP的通信主要发生在前向和后向传播过...


