Agent框架集成多模态能力底层实现
Agent框架集成多模态能力底层实现 该项目处理多模态RAG返回图片的完整流程: 架构概述 该项目采用分层架构处理多模态RAG: 前端接口层:通过schema.py中的ImageContent和ImageUrl模型支持base64和HTTPS两种图片URL格式 RAG核心层:rag.py中的RagClient提供统一的向量检索接口 多模态嵌入层:multi_model.py中的AliyunEmbeddings使用阿里云DashScope的多模态嵌入API 数据存储层:使用Qdrant向量数据库存储图片和文本的嵌入向量 图片处理流程 1. 图片存储阶段 在feishu-crawler子项目中,图片处理流程如下: 图片下载:DownloadImageTransform从飞书下载图片到本地文件系统 图片摘要生成:GenerateImageSummaryTransform使用VLLM模型为图片生成文字描述 多模态嵌入:EmbedImageTransform调用MultiModelEmbedder生成图片+文字的联合嵌入向量 向量存储:将base64编码的图片数据、文字描述和嵌入向量...
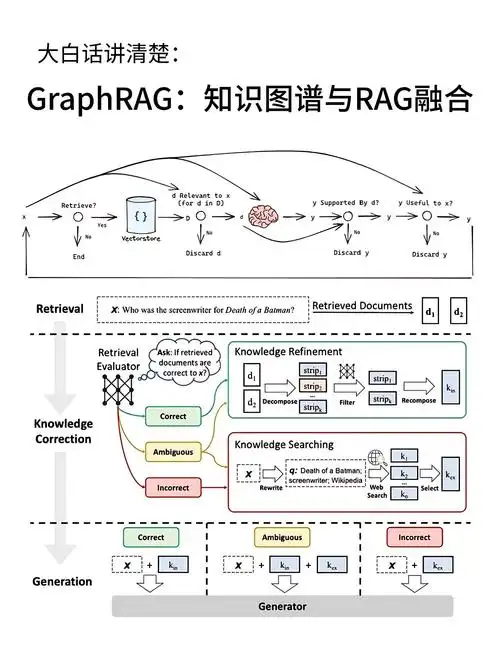
多路召回+Graph RAG调研和实践
多路召回+Graph RAG调研和实践 简介 多路召回简单来说就是指的通过多种途径——包括从已有的Qdrant、Memgraph甚至是web上等去拿到与query相关的上下文信息的过程。 Graph RAG这里有一些文档可以看看: memgraph+spacy构建知识图谱:https://memgraph.com/blog/extract-entities-build-knowledge-graph-memgraph-spacy 从知识图谱到 GraphRAG:探索属性图的构建和复杂的数据检索实践:https://cloud.tencent.com/developer/article/2441475 利用 LlamaIndex 和 Memgraph 构建知识图谱并查询:https://www.llamaindex.ai/blog/constructing-a-knowledge-graph-with-llamaindex-and-memgraph 一篇RAG+知识图谱的博客:https://qiankunli.github.io/2024/07/12/llm_graph.htm...
LangGraph 中 checkpoint_id 的更新时机:每个对话轮次还是每个节点流转?
LangGraph 中 checkpoint_id 的更新时机:每个对话轮次还是每个节点流转? 在使用 LangGraph 构建多轮对话或工作流时,我们经常会遇到 checkpoint(检查点)的概念。每个检查点都有一个唯一的 checkpoint_id,用于标识该次状态快照。一个常见的问题是:checkpoint_id 是在每个对话轮次更新一次,还是在节点(node)之间流转时就会更新一次? 本文将通过分析 LangGraph 源码(基于 langgraph==0.2.0 左右版本)来回答这个问题,并解释其背后的设计逻辑。 1. checkpoint_id 是如何生成的? 首先,我们来看 checkpoint_id 的生成方式。在 langgraph/checkpoint/base/__init__.py 中,有一个 create_checkpoint 函数: 12345678910111213141516171819def create_checkpoint( checkpoint: Checkpoint, channels: Mapping[str, BaseC...
从知识图谱到 GraphRAG:探索属性图的构建和复杂的数据检索实践
从知识图谱到 GraphRAG:探索属性图的构建和复杂的数据检索实践 为什么知识图谱+RAG>RAG:https://mp.weixin.qq.com/s?__biz=MzIyOTkzNDczMw==&mid=2247508213&idx=1&sn=a1d3505a55ef8456cdceaea64fb66091&chksm=e8b9f317dfce7a01be4827a834d09141608762ad7109d79a05ae3bf82ebfaf130cfd46df0b6e&scene=21#wechat_redirect 比如query:感冒了吃什么?db:1、感冒了可能会发烧和头痛。2、对乙酰氨基酚是一种退烧和止疼药物。相似度搜索极难查询到第2个结果,而Graph方法可以将对1和2连接在一起,从而在检索到1结点的时候将相邻结点一起检索出来。 当你问:“这个数据集的主题是什么?”这类高级别、概括性的问题时,传统的RAG可能就会束手无策。为什么呢?那是因为这本质上是一个聚焦于查询的总结性任务(Query-Focused Summa...
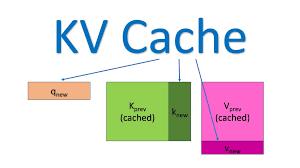
深入 KV Cache 的运作过程
深入 KV Cache 的运作过程 KV Cache 的工作主要发生在 Transformer 模型的 Decoder Block 中,特别是其多头自注意力(Multi-Head Self-Attention)层。 整个推理过程通常分为两个阶段:预填充阶段 (Pre-fill) 和 解码阶段 (Decoding)。 1. 预填充阶段 (Pre-fill / Prompt Encoding) 这个阶段处理用户的整个输入 Prompt(比如 100 个 token)。 步骤详解: 输入与投影: 完整的输入序列 [t1,t2,…,t100][t_1, t_2, \dots, t_{100}][t1,t2,…,t100] 进入 Transformer 的每一层。 计算 Q,K,VQ, K, VQ,K,V: 在自注意力层中,模型使用权重矩阵 WQ,WK,WVW_Q, W_K, W_VWQ,WK,WV 对输入向量进行投影,一次性计算出所有 token 的 QQQ、 KKK 和 VVV 矩阵: Kfull=[K1,K2,…,K100]K_{\text{full}} = ...
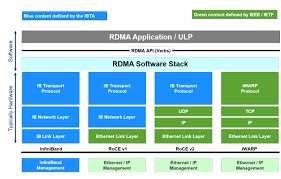
高性能网络InfiniBand & ROCE学习
高性能网络InfiniBand & ROCE学习 第一章:导论 - 为什么标准以太网(TCP/IP)“喂不饱” GPU?: https://blog.csdn.net/qq_38334677/article/details/154359174 这篇文章的核心是解释为什么传统TCP/IP网络无法满足大规模AI训练的需求,并引入RDMA技术作为解决方案。文章逻辑清晰,层层递进: 一、核心问题:TCP/IP在AI训练中的瓶颈 1.1 AI训练对网络的极端要求 分布式训练:尤其是AllReduce操作,需要频繁同步梯度 三大核心需求: 极低延迟:GPU集群计算步伐受最慢网络节点制约 高带宽:需要匹配GPU间的高速通信(如NVLink的数百GB/s) 低CPU开销:CPU应专注于数据处理,而非网络任务 1.2 TCP/IP的根本缺陷 缺陷一:高昂的CPU开销与内核干预 123TCP/IP数据发送流程:应用数据 → 系统调用 → 用户空间到内核空间拷贝 → TCP/IP协议栈处理 → 内核到网卡驱动拷贝 → 网卡发送 性能杀手: 系统调用:用户态/内核态切换(0.5-2微...
非结构化文档->memgraph提取(GraphDocument)
非结构化文档->memgraph提取(GraphDocument) https://www.llamaindex.ai/blog/constructing-a-knowledge-graph-with-llamaindex-and-memgraph 这里用LlamaIndex可以自动做到这一点,但是缺点是需要openai的key,用不了mass的 还有一种方式使用from langchain_experimental.graph_transformers import LLMGraphTransformer,其用提示词将非结构化的Document转化为GraphDocument: 提示词涵盖以下方面: 概述:定义任务和目标。 节点标注:规定节点类型的一致性和基本性。 关系标注:规定关系类型的一般性和永恒性。 共指消解:实体消歧,确保实体一致性。 严格合规:要求严格遵守规则。 将纯文本文档中的信息转化为 Memgraph 图数据库中的 节点 (nodes) 和 边 (edges),主要涉及以下几个步骤: 解析 (Parsing) / 提取 (Extraction): 从...

Gemini CLI上下文压缩魔改实践
仿照 Gemini CLI 的上下文压缩:智能对话历史管理 引言 在构建基于大语言模型(LLM)的智能体时,一个常见的挑战是如何处理不断增长的对话历史。随着交互轮次增加,上下文长度可能迅速接近模型的 token 限制,导致后续响应质量下降甚至请求失败。传统的截断方法会丢失重要信息,而简单的摘要又可能遗漏关键细节。 Google 的 Gemini CLI 在这方面提供了一个优雅的解决方案:聊天历史压缩。当对话接近 token 限制时,系统会自动将历史压缩为一个结构化的摘要,既保留了核心信息,又大幅减少了 token 占用。Infini-Agent-Framework 借鉴了这一设计思想,实现了自己的上下文压缩模块,本文将深入解析其设计与实现。 压缩模块概览 Infini-Agent-Framework 的压缩模块位于 infini_agent_framework.langgraph.compression,提供了以下核心能力: 阈值触发:当对话历史 token 数超过预设阈值(默认 70% 的模型最大长度)时自动触发压缩。 结构化摘要:使用 LLM 将历史转换为格式化的 XML ...

Python异步编程完全指南:从新手到实践
Python异步编程完全指南:从新手到实践 引言 在现代Python开发中,异步编程已成为处理I/O密集型应用的关键技术。无论是Web服务、网络爬虫还是数据处理,异步编程都能显著提升程序性能。本文将从基础概念出发,逐步深入探讨Python异步编程的核心机制。 一、异步编程的核心思想 1.1 同步 vs 异步:一个生动的比喻 想象你在咖啡厅点单: 同步方式:你点一杯咖啡,然后站在原地等待咖啡制作完成,期间什么也不做 异步方式:你点完咖啡后,立刻去找座位、看手机、和朋友聊天,咖啡做好了服务员会通知你 这就是异步编程的本质:在等待耗时操作时,不阻塞程序执行,而是继续处理其他任务。 1.2 事件循环:异步编程的"大脑" 事件循环是异步编程的调度中心,它负责: 管理和调度所有异步任务 监控任务状态 在适当的时候恢复挂起的任务 123456789import asyncioasync def main(): print("Hello") await asyncio.sleep(1) print("World"...
NCCL通信原语
NCCL通信原语 参考: https://blog.csdn.net/2401_84208172/article/details/142610913?fromshare=blogdetail&sharetype=blogdetail&sharerId=142610913&sharerefer=PC&sharesource=a1150568956&sharefrom=from_link 1. Broadcast 其实就是把自己卡上面的东西让所有卡都知道 2. Scatter 其实就是把自己的东西分成多块,按照顺序向其他GPU发送data block 3. Reduce 就是把所有卡的部分在自己卡上面作一个sum。注意这里只有自己的卡作sum 4. Gather 其实对应于Scatter,是把分布在其他卡上的data block在自己卡上面拼起来。注意,这里也是只有自己这一张卡 5. AllReduce 每张卡都对所有卡作一个sum=reduce scatter+all gather, 通信成本也等于这俩加起来 官方说法:将每个节点的数据规约并...




