Tongyi DeepResearch技术报告解读及源码分析
Tongyi DeepResearch技术报告解读及源码分析 https://github.com/Alibaba-NLP/DeepResearch https://zhuanlan.zhihu.com/p/1966914265899329009
OpenSkills深度解析:如何让Claude Code获得超能力
OpenSkills深度解析:如何让Claude Code获得超能力 引言:AI编程助手的新纪元 在AI编程助手日益普及的今天,Claude Code作为Anthropic推出的专业编程助手,其技能系统(Skills System)为用户提供了强大的扩展能力。然而,原生的技能系统存在一些限制:只能从官方市场安装、无法使用私有技能、难以跨项目共享等。 OpenSkills项目应运而生,它完美复刻了Claude Code的技能系统,同时提供了更大的灵活性和控制权。本文将深入解析OpenSkills的技术架构,并详细说明如何让Claude Code使用这个项目作为技能。 一、OpenSkills项目核心价值 1.1 什么是OpenSkills? OpenSkills是一个开源命令行工具,实现了与Claude Code 100%兼容的技能系统。它允许用户: ✅ 从任何GitHub仓库安装技能(不仅仅是官方市场) ✅ 安装本地路径或私有Git仓库的技能 ✅ 跨多个AI代理共享技能 ✅ 在项目中版本控制技能 ✅ 通过符号链接进行本地技能开发 1.2 技术架构概览 graph TB ...
Context as a Tool:Context Management for Long-Horizon SWE-Agents
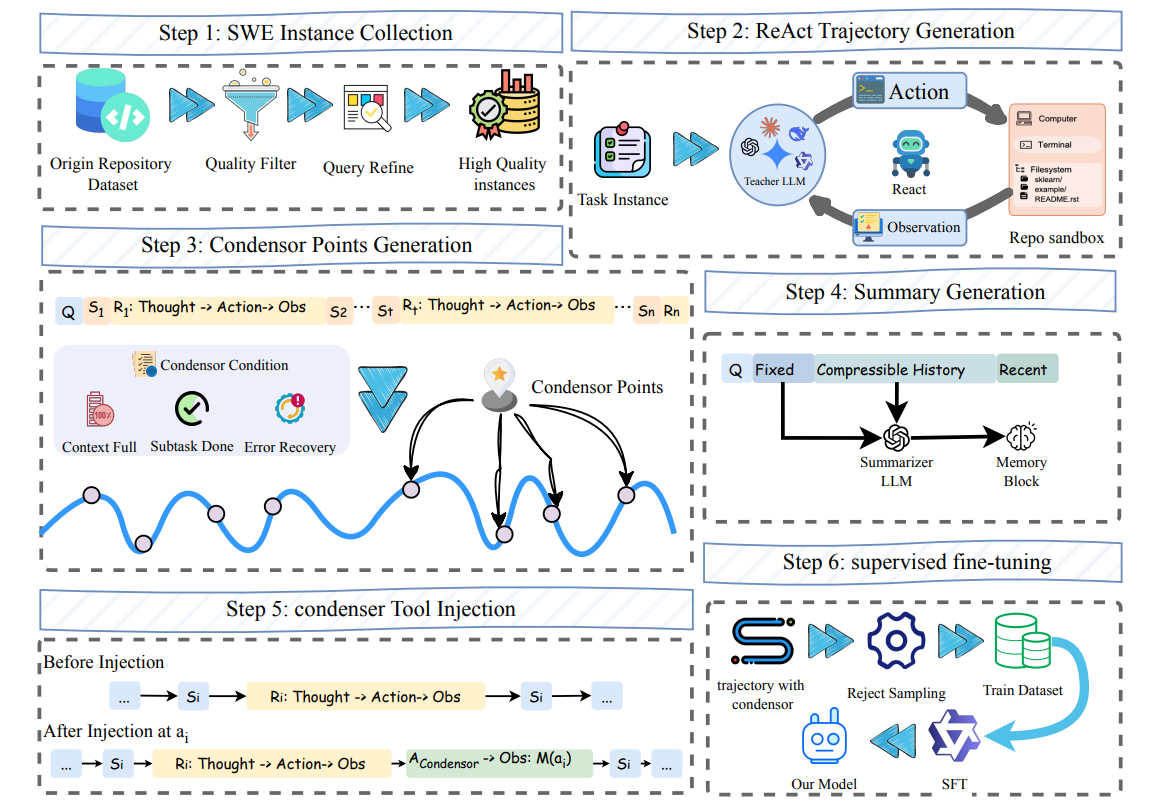
Context as a Tool: Context Management for Long-Horizon SWE-Agents 在软件工程(SWE)领域,大型语言模型(LLM)驱动的自主代理正逐渐从简单的代码生成器演变为能够处理复杂、长程任务的系统性实体。然而,随着任务复杂度的提升,代理在与大规模代码库进行长达数百轮的交互时,面临着严峻的上下文管理挑战。传统的“追加式”上下文维护策略往往导致上下文爆炸、语义偏移以及推理崩溃 1。近期由 Liu 等人提出的 CAT(Context as a Tool)框架,通过将上下文维护提升为一种可调用、可规划的工具能力,为长程代理的稳定性与可扩展性提供了新的范式 1。本报告旨在深入探讨 CAT 框架的技术架构、数据生成管线、实验表现及其在 2025 年智能代理生态系统中的战略地位。 长程交互中上下文失效的根源分析 在软件工程任务中,如修复 GitHub 存储库级别的 issue,代理通常需要执行数十次甚至数百次的环境交互,包括文件读取、搜索、代码编辑和测试运行 1。大多数现有的代理架构,如 ReAct 框架,采用的是一种被动且线性的上下文增...
MEMORY-T1:REINFORCEMENT LEARNING FOR TEMPORAL REASONING IN MULTI-SESSION AGENTS
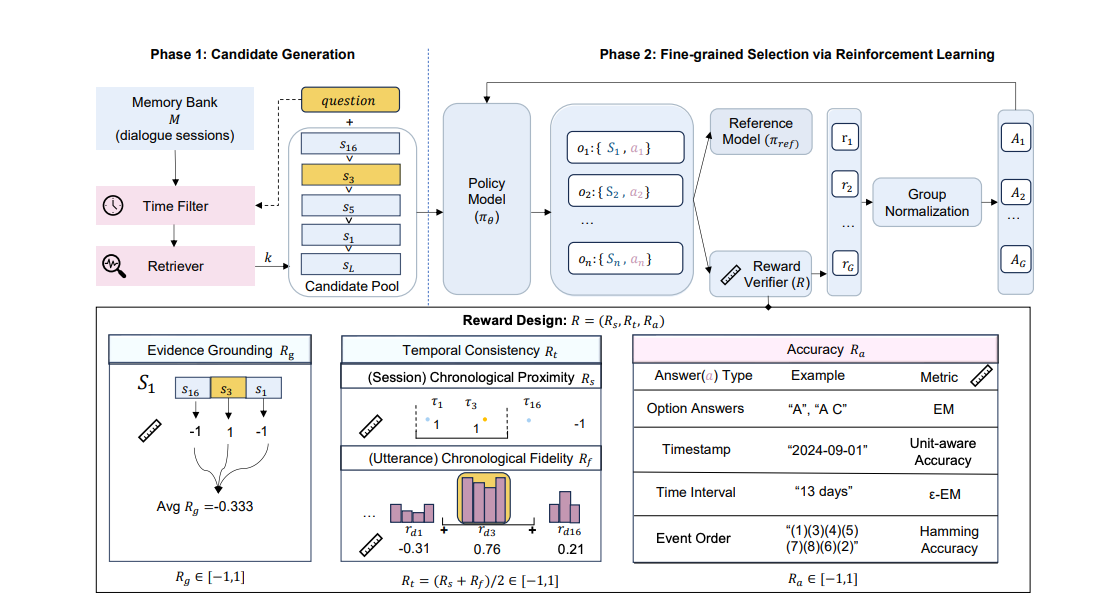
MEMORY-T1: REINFORCEMENT LEARNING FOR TEMPORAL REASONING IN MULTI-SESSION AGENTS 这里其实就是对自己跨对话的的上下文(即对话历史)做智能过滤和选择。 从历史中 选出最相关的部分,丢弃无关内容。 主要应对 时间错乱、证据不精准 的问题。 输入:全部对话历史(很长很乱) 处理:先按时间过滤,再按内容过滤,最后用强化学习选出最佳证据子集 输出:只把精选后的上下文片段喂给模型生成答案 在当代人工智能的研究范式中,大型语言模型(LLM)已逐步从单纯的文本生成工具演化为具备长期记忆与复杂规划能力的自主智能体。然而,当这些智能体被部署于现实世界中需要跨越数周、数月甚至数年的多会话(Multi-session)交互场景时,一个核心的技术瓶颈凸显出来:如何精准地理解和推理对话历史中的时间维度信息 1。现有的长文本模型虽然在处理数十万字的技术文档时表现优异,但在处理充满噪音、非结构化且具有复杂时间依赖性的多会话对话时,往往会表现出显著的性能衰退,无法准确识别时间相关的关键证据,导致回答出现逻辑冲突或事实性错误 1...
MemEvolve:Meta-Evolution of Agent Memory Systems
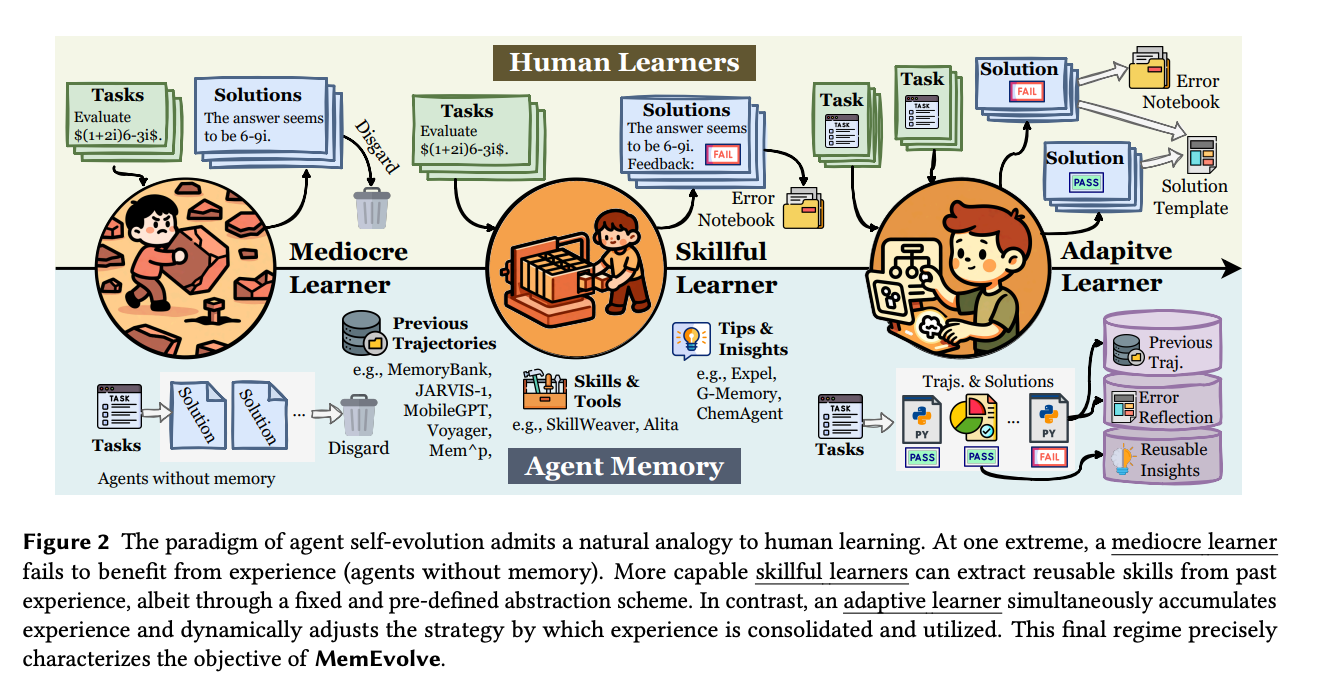
MemEvolve: Meta-Evolution of Agent Memory Systems 代理记忆系统从静态架构向动态自适应的范式转变 在大语言模型(LLM)驱动的智能体(Agent)研究领域,自我演化(Self-evolving)记忆系统正在以前所未有的速度重塑人工智能的进化范式。传统的智能体系统在处理复杂、长程任务时,往往依赖于静态的记忆架构。这些架构通常由研究人员根据特定任务手动设计,用于存储交互轨迹、蒸馏经验以及合成可重用的工具 1。然而,这种范式存在一个根本性的局限性:记忆系统的架构本身是静态的。尽管记忆内容可以随时间积累,但底层的记忆机制(包括编码、存储、检索和管理)无法根据多样化的任务上下文进行元自适应(Meta-adaptation) 1。 为了填补这一空白,MemEvolve 框架应运而生。这是一个元进化框架,旨在实现代理经验知识与其记忆架构的联合进化。通过这种方式,智能体系统不仅能积累经验,还能通过与环境的持续交互,逐步优化其“学习如何学习”的机制 1。这种转变标志着智能体从“熟练学习者”(能够提取可重用技能,但遵循固定模式)向“自适应学习者”(能够...
Function Call 的多轮对话要怎么处理?为什么它是最难的部分?
Function Call 的多轮对话要怎么处理?为什么它是最难的部分? https://mp.weixin.qq.com/s/HJXyiX1Di8GHuubnP8Mp8w 在 Function Call 微调中,多轮对话是核心难点。我把业务拆成多个工作流,每个工作流根据变量来决定是否需要追问参数。 追问完成后,再进入工具链式调用,工具结果可能触发下一轮调用,最终在所有工具完成后统一生成结果。 为了让模型真正学会流程,使用沙盒方式构建数据: 根据标签选择工作流 根据变量决定是否需要追问 自动构造反问句 用户回答由模板生成 工具链由代码模拟 工具返回由 mock 数据生成 最后用 base 模型重写自然语言 通过用户画像、query 模板、工具返回扰动、多轮追问模板等方式,为每个分支生成足够数量的数据,并保证所有分支场景都有覆盖。 最终模型可以:需要追问时追问,参数齐全时调用工具,工具链顺序正确,工具为空时 fallback,并且能保持多轮对话的一致性与连贯性。
RL for LLM 高质量文章汇总
RL for LLM 高质量文章汇总 算法 PPO Proximal Policy Optimization Algorithms 日期:2017.08.28 从头理解PPO(Proximal Policy Optimization):从公式到代码 图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读 人人都能看懂的RL-PPO理论知识 RLOO Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs 日期:2024.02.22 大模型 | PPO 和 DPO 都不是 RLHF 的理想形式 一文对比4种 RLHF 算法:PPO, GRPO, RLOO, REINFORCE++ GRPO DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models 日期:2024.04.27 DeepSeek的GRPO算法是什么? 强化学习...
DeepAgents:基于LangChain的下一代智能代理框架
DeepAgents:基于LangChain的下一代智能代理框架 https://docs.langchain.com/oss/python/deepagents/overview 概述 DeepAgents是一个构建在LangChain之上的高级智能代理框架,旨在提供更强大、更灵活的代理构建能力。该框架通过模块化设计,为开发者提供了文件系统操作、子代理管理、可插拔后端存储等核心功能,使得构建复杂的多步骤AI代理变得更加简单和高效。 DeepAgents构建在以下基础之上: LangGraph - 提供底层图执行和状态管理 LangChain——工具和模型集成与深度代理无缝协作 LangSmith - 可观测性、评估和部署 例子:https://zhuanlan.zhihu.com/p/1979938537802597911 核心架构 DeepAgents采用分层架构设计,主要包含以下核心模块: 1. 核心入口模块(graph.py) create_deep_agent():框架的主要入口函数,用于创建深度代理 默认使用Claude Sonnet 4作为模型 内置多种中间件...
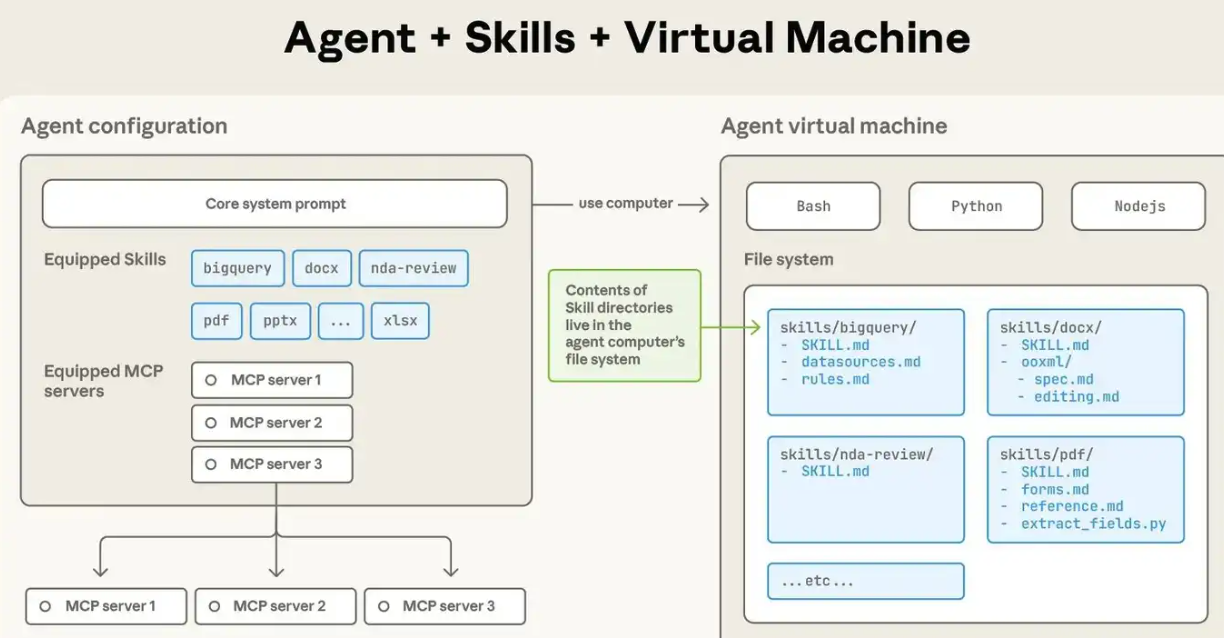
Anthropic skils解读与实践
Anthropic skils解读与实践 https://github.com/anthropics/skills 全流程周期:https://zhuanlan.zhihu.com/p/1984015383276041355 介绍 二者都是扩展LLM能力的一种手段。 Agent Skills 是一种标准化的程序性知识封装格式。如果说 MCP 为智能体提供了"手"来操作工具,那么 Skills 就提供了"操作手册"或"SOP(标准作业程序)",教导智能体如何正确使用这些工具。 这种设计理念源于一个简单但深刻的洞察:连接性(Connectivity)与能力(Capability)应该分离。MCP 专注于前者,Skills 专注于后者。这种职责分离带来了清晰的架构优势: MCP 的职责:提供标准化的访问接口,让智能体能够"够得着"外部世界的数据和工具 Skills 的职责:提供领域专业知识,告诉智能体在特定场景下"如何组合使用这些工具" MCP 在使用上的不同之处在于,MCP的流程是...

LLM强化学习算法演进之路:MC->TD->Q-Learning->DQN->PG->AC->TRPO->PPO->DPO->GRPO
LLM强化学习算法演进之路:MC->TD->Q-Learning->DQN->PG->AC->TRPO->PPO->DPO->GRPO https://zhuanlan.zhihu.com/p/20949520788: 这文章很详细




