文章
193
标签
160
分类
54
关于笔者
主页
博文
分类
标签
归档
友链
留言板
Roger-Lv's space
搜索
关于笔者
主页
博文
分类
标签
归档
友链
留言板
强化学习
分类 - 强化学习
2025
2025-12-24
RL for LLM 高质量文章汇总
2025-12-10
verl框架学习
2025-09-01
LIMR解读
2025-09-01
Pass@k作为reward可以有效平衡探索与利用
2025-09-01
揭秘RLVR的真相:强化学习真的能提升大语言模型的推理能力吗?
2025-08-20
UloRL:An Ultra-Long Output Reinforcement Learning Approach for Advancing Large Language Models’ Reasoning Abilities
2025-08-13
基于 Ray 的分离式架构:veRL、OpenRLHF 工程设计
2025-08-13
TD lamda和GAE
2025-08-13
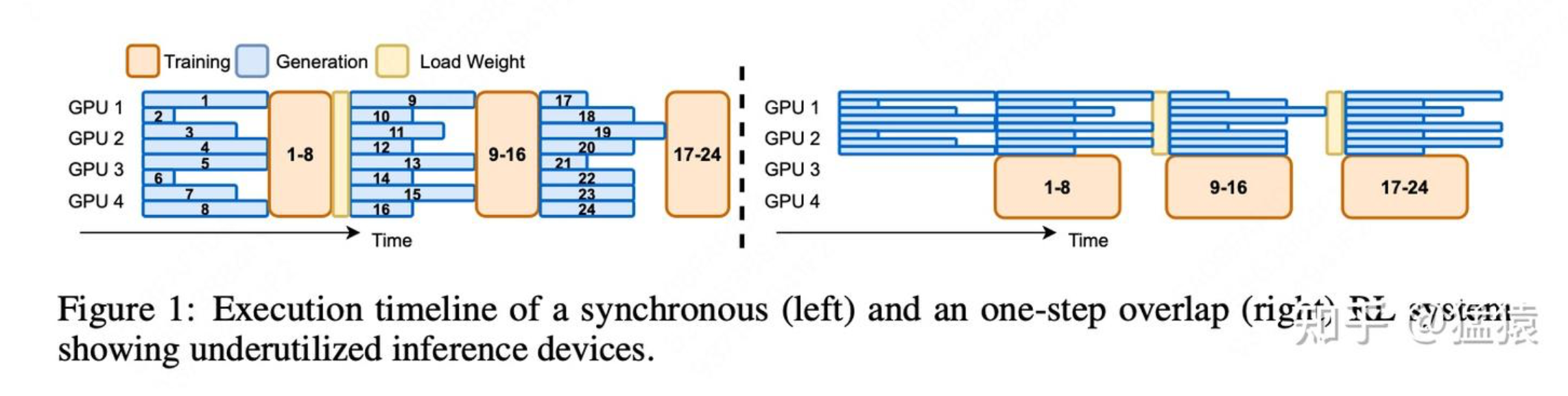
异步RL框架AReaL
2024
2024-09-11
RLHF
1
2
Roger-Lv
Send a flare and light the way.
文章
193
标签
160
分类
54
Follow Me
公告
Welcome!
最新文章
记录一次claude code->litellm->openrouter->claude/gpt模型调用bug的修复
2026-03-13
八字命理之贵人篇
2026-03-07
🦌 DeerFlow - 字节跳动开源的超级智能体框架
2026-03-03
最近遇到的一些事,抑郁杂谈
2026-02-20
OpenClaw解析
2026-02-04
分类
AI Infra
6
AIInfra
5
Agent
24
CUDA
1
Docker
1
Flowise
1
Golang
1
GraphRAG
1
标签
RPC
多模态
分页查询
Docker
c++
SpringBoot
训练
FutureTask
卷积神经网络
pod
深度学习
SFT
Seq2Seq
GPU
分布式锁
线程
集群
高性能网络
AI Infra
CNN
自然辩证法
nvml
状态压缩
微服务
Golang
OpenClaw
大模型学习路线
资源调度
机器学习
manus
基础设施
MySQL
llm
Ollama
rust
算法
ElasticSearch
并行计算
命理
线程池
归档
三月 2026
3
二月 2026
3
一月 2026
5
十二月 2025
28
十一月 2025
5
十月 2025
1
九月 2025
37
八月 2025
30
网站信息
文章数目 :
193
本站访客数 :
本站总浏览量 :
最后更新时间 :
搜索
数据加载中