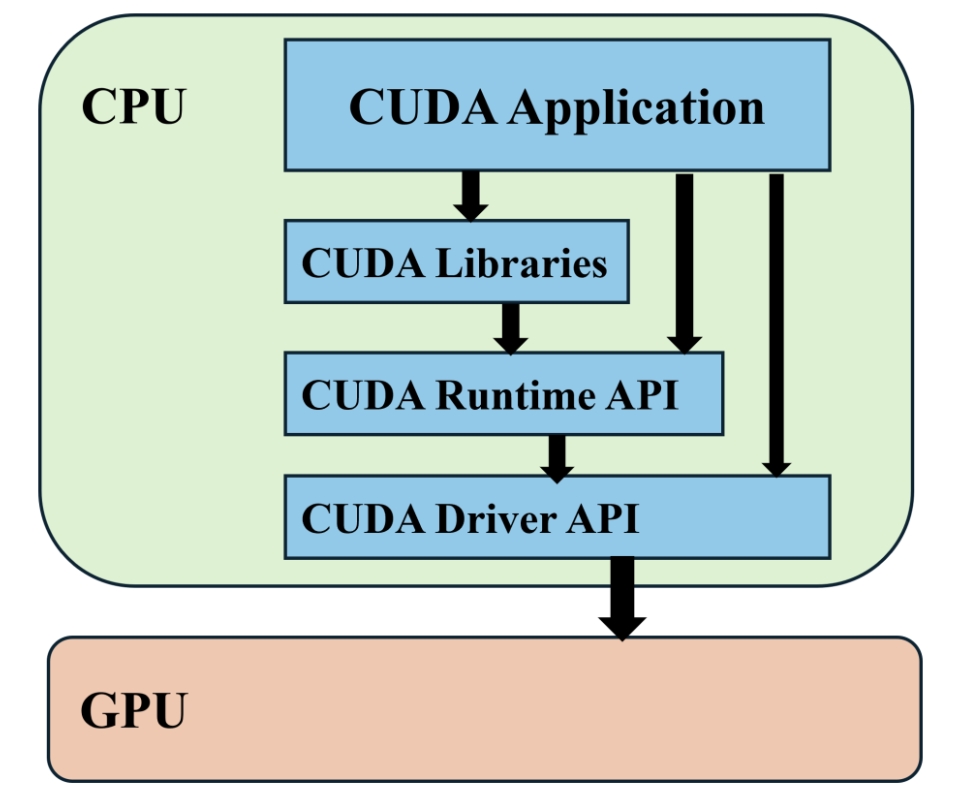
AI Infra相关
AI Infra相关
K8S
异构容错
会有一些挑战:
- 大规模分布式训练任务为了适应国产芯片需要更大规模
- 原因在于国产卡的算力比不上N卡,自然需要更大规模
- 大模型分布式训练任务频繁中断
- 目前几乎所有的大模型训练方式都是同步训练(DDP/MPI),训练的进程共同使用一个通信拓扑,当某一个进程发生错误时,其他进程也会相继退出
- 异构芯片及服务器集群的故障率与集群规模成正比,且随着集群规模的扩大训练任务的中断次数成倍增加
- BLOOM 176B的训练, 在大约400个GPU的新集群上,平均每周都会遇到1-2个GPU故障。
- 字节的大规模训练也呈现相应的特征。[from MegaScale]
- 大模型分布式训练任务出错原因难排查
- net ib?
- socket timeout
- gpu ecc error
- 这些问题靠重新调度是无法解决的,需要准确定位到节点出错的位置,这需要花费数小时甚至数天的时间(可观测性建设)
- 
- 大模型分布式训练任务基于检查点恢复的读写开销大
- 所谓容错,就是把检查点快照(优化器状态、模型权重)等持久化到存储中。checkpoint总大小与参数量成正比
解决办法:
架构如下

- 训练任务的自动容错恢复
- k8s容器层面和调度层面做到在不侵入训练框架的前提下,在训练任务遇到故障时,可以做到worker容器不退出,原地检测异常问题 ,保存训练状态,并针对异常检测出来的错误进行定向重启。
- 训练任务的异常检测
- 聚类算法/机器学习算法:CPU 内存 IO 网络指标
- 训练任务的异步检查点读写
- 限制:存储介质的读写速度 硬盘读写速率和网络传输速率的限制 带宽竞争
- 内存缓存机制
- 异步读写
基础
https://cloud.tencent.com/developer/article/1628686
https://zhuanlan.zhihu.com/p/721588398
构成
Master节点:
Kubectl:客户端命令行工具,作为整个K8s集群的操作入口;
Api Server:在K8s架构中承担的是“桥梁”的角色,作为资源操作的唯一入口,它提供了认证、授权、访问控制、API注册和发现等机制。客户端与k8s群集及K8s内部组件的通信,都要通过Api Server这个组件;
Controller-manager:负责维护群集的状态,比如故障检测、自动扩展、滚动更新等;
**Scheduler:**负责资源的调度,按照预定的调度策略将pod调度到相应的node节点上;
**Etcd:**担任数据中心的角色,保存了整个群集的状态;
Node节点:
Kubelet:负责维护容器的生命周期,同时也负责Volume和网络的管理,一般运行在所有的节点,是Node节点的代理,当Scheduler确定某个node上运行pod之后,会将pod的具体信息(image,volume)等发送给该节点的kubelet,kubelet根据这些信息创建和运行容器,并向master返回运行状态。(自动修复功能:如果某个节点中的容器宕机,它会尝试重启该容器,若重启无效,则会将该pod杀死,然后重新创建一个容器);
Kube-proxy:Service在逻辑上代表了后端的多个pod。负责为Service提供cluster内部的服务发现和负载均衡(外界通过Service访问pod提供的服务时,Service接收到的请求后就是通过kube-proxy来转发到pod上的);
container-runtime:是负责管理运行容器的软件,比如docker、containerd
Pod:是k8s集群里面最小的单位。每个pod里边可以运行一个或多个container(容器),如果一个pod中有两个container,那么container的USR(用户)、MNT(挂载点)、PID(进程号)是相互隔离的,UTS(主机名和域名)、IPC(消息队列)、NET(网络栈)是相互共享的。我比较喜欢把pod来当做豌豆夹,而豌豆就是pod中的container;
探针
三种探针、四种检测方法:https://cloud.tencent.com/developer/article/2339948
创建流程
情况一、使用 kubectl run 命令创建的 pod:
注意:
kubectl run 在旧版本中创建的是 deployment,但在新的版本中创建的是 pod,其创建过程不涉及 deployment。如果是单独创建一个 pod,过程如下:
- 用户通过
kubectl或其他 API 客户端工具提交需要创建的 pod 信息给apiserver; apiserver验证用户权限信息,生成 pod 对象信息并存入etcd,然后返回确认信息给客户端;apiserver将etcd中的 pod 对象变化反馈给其他组件,其他组件使用watch机制跟踪变动;- 调度器
scheduler发现有新的 pod 对象,调用算法为 pod 分配最佳主机,并将结果更新至apiserver; kubelet通过watch机制跟踪到分配给本节点的 pod,调用 Docker 启动容器,并反馈结果给apiserver;apiserver将 pod 状态信息存入etcd,至此 pod 创建完毕。
情况二、使用 deployment 创建 pod:
- 用户通过
kubectl create或kubectl apply提交创建 deployment 请求; apiserver处理请求,进行身份验证,并将 deployment 信息存入etcd,返回确认信息给客户端;apiserver反馈etcd中对象的变化,其他组件使用watch机制跟踪变动;controller-manager监听到 deployment 的创建,生成 ReplicaSet,并由ReplicaSet Controller处理;- 调度器
scheduler通过内部算法为未调度的 pod 分配节点,并反馈结果给apiserver; kubelet监听到本节点分配的 pod,创建 pod 并启动容器,最终将状态反馈至apiserver;- Pod 创建成功后,
ReplicaSet Controller持续监控 pod 状态,确保副本数量与期望值一致。
终止流程
- 用户向
apiserver发送删除 pod 命令; - pod 对象信息更新,在宽限期内(默认 30 秒),pod 被视为
dead; - 将 pod 标记为
terminating状态; kubectl监控到terminating状态,启动 pod 关闭过程;endpoint控制器监控到 pod 关闭,将其从endpoint列表中删除;- 若定义了
preStop钩子,执行相关操作; - 容器进程收到停止信息;
- 宽限期结束后,若 pod 仍运行,
kubelet请求apiserver设置宽限期为 0 完成删除操作。
pod 的生命周期状态
Kubernetes 的 pod 具有以下几种生命周期状态:
- Pending:API server 已创建 pod,但尚有一个或多个容器镜像未创建或正在下载;
- Running:pod 内的所有容器已经创建,至少有一个容器处于运行状态或正在重启;
- Succeeded:pod 内所有容器已退出且不会再重启;
- Failed:pod 内所有容器已退出,且至少有一个容器退出失败;
- Unknown:
apiserver无法获取 pod 状态,可能由于网络问题导致。
pending原因排查
调度器调度失败:
调度器无法为 pod 分配合适的 node 节点。可能的原因包括:
- Node 节点 CPU、内存不足;
- Pod 的资源请求超出节点可用资源;
- Node 节点存在污点,pod 没有定义容忍;
- Pod 定义了亲和性或反亲和性,无法匹配合适的节点。
PVC 或 PV 无法动态创建:
当 pod 使用 StatefulSet 但未正确配置存储时,pod 可能一直处于 pending 状态。可能的原因包括:
StorageClassName配置错误;- PVC 动态创建失败;
- 存储供应异常,PV 无法创建。
pod资源请求限制
- limits:限制 Pod 能使用的最大 CPU 和内存。
- requests:Pod 启动时申请的最小 CPU 和内存。
- Guaranteed(保证型)
- 最高优先级的 QoS 等级
- 条件:Pod 中所有容器必须同时设置 CPU 和内存的
requests和limits,并且每种资源的requests值必须等于limits值 - 特点:
- 资源得到完全保证,K8s 承诺分配所请求的全部资源
- 在节点资源紧张时,最后被驱逐
- 内存不足时,OOM Killer 最后考虑杀死这类 Pod
- 适用于关键业务、数据库等需要稳定资源保障的应用
- Burstable(突发型)
- 中等优先级的 QoS 等级
- 条件:Pod 不符合 Guaranteed 条件,但至少有一个容器设置了
requests或limits - 特点:
- 资源有最低保障(
requests),但可以按需使用更多资源(不超过limits) - 在节点资源紧张时,优先级高于 BestEffort,低于 Guaranteed
- 内存不足时,OOM Killer 会优先杀死超出
requests内存使用最多的 Burstable Pod - 适用于大多数生产应用,兼顾资源保障和弹性
- 资源有最低保障(
- BestEffort(尽力而为型)
- 最低优先级的 QoS 等级
- 条件:Pod 中所有容器都没有设置任何
requests和limits - 特点:
- 没有任何资源保障,只能使用节点上剩余的闲置资源
- 在节点资源紧张时,最先被驱逐
- 内存不足时,OOM Killer 最先杀死这类 Pod
- 适用于非关键任务、测试环境、批处理作业等可中断的应用
Pod 的定义中有个 command 和 args 参数,这两个参数不会和 Docker 镜像的 ENTRYPOINT 冲突吗?
不会冲突。
Kubernetes 中的 command 和 args 参数可以覆盖 Docker 镜像中的 ENTRYPOINT 和 CMD。具体的行为是:
- 如果
command和args都没写,使用 Dockerfile 里的ENTRYPOINT和CMD。 - 如果只写了
command,会覆盖ENTRYPOINT,但仍会使用 Dockerfile 里的CMD。 - 如果只写了
args,会覆盖 Dockerfile 里的CMD,但还是会用ENTRYPOINT。 - 如果
command和args都写了,Dockerfile 里的ENTRYPOINT和CMD都会被覆盖。
这意味着,Kubernetes 允许你灵活控制容器启动时的命令和参数。
ps:竟然command和cmd不是对应的
k8s监控节点pod资源
Kubelet 主要通过 cAdvisor(Container Advisor)来监控 Node 节点的资源使用情况。cAdvisor 能够收集和报告容器的 CPU、内存、网络、文件系统等资源的使用数据。
这些数据不仅可以用于实时监控,还可以为调度决策提供依据,帮助 Kubernetes 更好地分配和管理资源。
k8s负载均衡器
三种方案:
- kube-proxy(userspace)
- iptables(防火墙)
- ipvs
1、kube-proxy
使用kube-proxy的负载方案是使用kube-proxy来监控pod的状态,如果pod发生了变化,则需要kube-proxy去修改service和pod的映射关系(endpoints),同时修改路由规则,并且由kube-proxy转发请求,这种方式kube-proxy的压力比较大,性能可能会出现问题。

2、IPtables
IPtables是K8S默认采用的负载策略,这种方式中,kube-proxy同样用来监控pod和修改映射关系以及修改路由规则,但是转发请求是采用轮询iptables路由规则的方式进行调用处理的。

这种模式kube-proxy主要做好watching Cluster API即可,路由和请求的转发都交给了iptables,但是kube-proxy在请求无响应时会换一个pod进行重试,而iptables则是一条条的路由规则,不会进行重试。
在iptables中,默认的轮询策略是随机的轮询策略,但是也可以将其设置为轮询。
(1)设置为随机策略
1 | # 随机:(Random balancing) |
在iptables命令中,命令的执行和顺序有关,在上述命令中,用–probability 设置了命中几率,第一条设置了纪律是0.33,也就是整个请求的0.33,第二条命中率为0.5,实际是剩余请求的0.5,也就是总请求的0.335,第三条是剩余的流量全部打到该ip上,也就是0.335,基本上就是随机分配了。
(2)设置为轮询策略
1 | #every:每n个包匹配一次规则 |
3、IPVS
ipvs (IP Virtual Server) 实现传输层负载均衡,通常称为第四层LAN交换,是Linux内核的一部分。
ipvs与iptables的区别:
- ipvs为大型集群提供了更好的可扩展性和性能
- ipvs支持比iptables更复杂的负载均衡算法
- ipvs支持服务器的健康检查和连接重试等。
对于上述差异做个说明:
在linux中iptables设计是用于防火墙的,对于比较少的规则,没有太多的性能影响,如果对于一个庞大的K8S集群,会有上千Service服务,Service服务会对应多个pod,每条都是一个iptables规则,那么对于集群来说,每个node上都有大量的规则,简直是噩梦。而IPVS则是使用hash tables来存储网络转发规则的,比iptables更有优势,而且ipvs主要工作在kerbespace,减少了上下文的切换。
IPVS有轮询(rr)、最小连接数(lc)、目的地址hash(dh)、源地址hash(sh)、最短期望延迟(sed)、无须队列等待(nq)等负载均衡算法,在node上通过 “–ipvs-scheduler”参数,指定kube-proxy的启动算法。
kube-proxy和IPVS合作的流程:
(1)kube-proxy仍然是watching Cluster API,获取新建、删除Service或Endpoint pod指令,如果有新的Service建立,kube-proxy回调网络接口,构建IPVS规则。
(2)kube-proxy会定期同步Service和Pod的转发规则,确保失效的转发可以被及时修复
(3)有请求转发到后端的集群时,IPVS的负载均衡直接将其转发到对应的Pod上
四层:基于 IP+端口 转发(传输层)
七层:基于 应用内容 转发(应用层)
七层:ingress-nginx

https://zhuanlan.zhihu.com/p/453338705
一些保姆级别的说明:https://zhuanlan.zhihu.com/p/671031276
对外暴露:nodeport loadbalancer ingress
客户端- ingress -server ip- node ip - pod ip -> 容器地址
网络
https://zhuanlan.zhihu.com/p/6112293273
CNI 插件网络模式
- 覆盖网络(Overlay Network)
- CNI 插件通过 Overlay Network 模式,以 VXLAN 或 IPIP 等再次封装数据包后进行传输的方式,实现集群内 Pod 之间的互相访问,常见的有:
- Flannel 插件的 VXLAN 模式
- Calico 插件的 VXLAN、IPIP 模式
- CNI 插件通过 Overlay Network 模式,以 VXLAN 或 IPIP 等再次封装数据包后进行传输的方式,实现集群内 Pod 之间的互相访问,常见的有:
- 底层网络(Underlay Network)
- CNI 插件通过 Underlay Network 模式,以节点作为路由设备、Pod 学习路由条目的方式,实现复杂场景下(如跨集群、跨云环境)集群外部直接访问集群内 Pod,常见的有:
- Flannel 插件的 HOST-GW 模式
- Calico 插件的 BGP 模式
- Cilium 插件的 Native-Routing 模式
- CNI 插件通过 Underlay Network 模式,以节点作为路由设备、Pod 学习路由条目的方式,实现复杂场景下(如跨集群、跨云环境)集群外部直接访问集群内 Pod,常见的有:
2、Bridge 与 veth-pair
Bridge 和 veth-pair 都是 Linux 中的虚拟网络接口。
Pod 通过 veth-pair 将自己的 Network Namespace 与 Node 节点的 Network Namespace 打通,然后使用 Bridge 将所有 veth-pair 连接在一起,实现大量 Pod 之间的互通和管理。
常见的 Bridge 有 docker0(Docker 服务启动时自动创建的网桥)、tunl0(由 Calico 插件的 IPIP 模式创建)、vxlan.calico(由 Calico 插件的 VXLAN 模式创建)。
3、kube-proxy
kube-proxy 作为 Node 节点的一个组件,主要作用是监视 Service 对象和 Endpoint 对象的变化(添加、移除)并刷新负载均衡,即通过 iptables 或 IPVS 配置 Node 节点的 Netfilter,实现网络流量在不同 Pod 间的负载均衡,并为 Service 提供内部服务发现。
kube-proxy 和 CNI 插件本质上都只是为 Linux 内核提供配置,而实际的数据包处理仍由内核完成,因此面临以下问题:
- 随着集群中 Service 对象和 Pod 对象数量的增长,iptables 的规则匹配效率会下降,即使 IPVS 进行了优化依然面临性能开销
- 频繁的 Service 对象和 Pod 对象更新会导致规则重新应用,可能带来网络延迟或中断
- 强依赖于 Linux 内核的 Netfilter,一旦内核配置不当或不兼容,可能会引发网络问题
当前,Cilium 等插件通过 eBPF 等技术可以绕过 Linux 内核,直接在用户空间处理数据包,实现了无代理的服务流量转发,完全可以替代 kube-proxy。但需要注意在使用 Istio 的场景下,若出现诸如 Service 对象的 port 与 targetPort 不一致等情况,可能导致 Istio 无法命中对应的路由规则。
存储
pv pvc storageclass
- PV是集群中的存储资源,通常由集群管理员创建和管理;
- StorageClass用于对PV进行分类,如果配置正确,Storage也可以根据PVC的请求动态创建PV;
- PVC是使用该资源的请求,通常由应用程序提出请求,并指定对应的StorageClass和需求的空间大小;
- PVC可以作为数据卷的一种,被挂载到pod中使用;

在创建pv这个资源对象时,采用的回收策略是清除PV中的数据,然后自动回收,而PV这个资源对象是由PVC来申请使用的,所以不管是容器也好,pod也好,它们的销毁并不会影响用于实现数据持久化的nfs本地目录下的数据,但是,一旦这个PVC被删除,那么本地的数据就会随着PVC的销毁而不复存在,也就是说,采用PV这种数据卷来实现数据的持久化,它这个数据持久化的生命周期是和PVC的生命周期是一致的。
其他
kubectl drain和cordon的区别
简单来说:
cordon是“标记”或“隔离”节点,防止新Pod调度上来,但不干扰现有Pod。drain是“排空”节点,在cordon的基础上,还会驱逐或删除节点上现有的Pod。