Anthropic skils解读与实践
Anthropic skils解读与实践
https://github.com/anthropics/skills
全流程周期:https://zhuanlan.zhihu.com/p/1984015383276041355
介绍
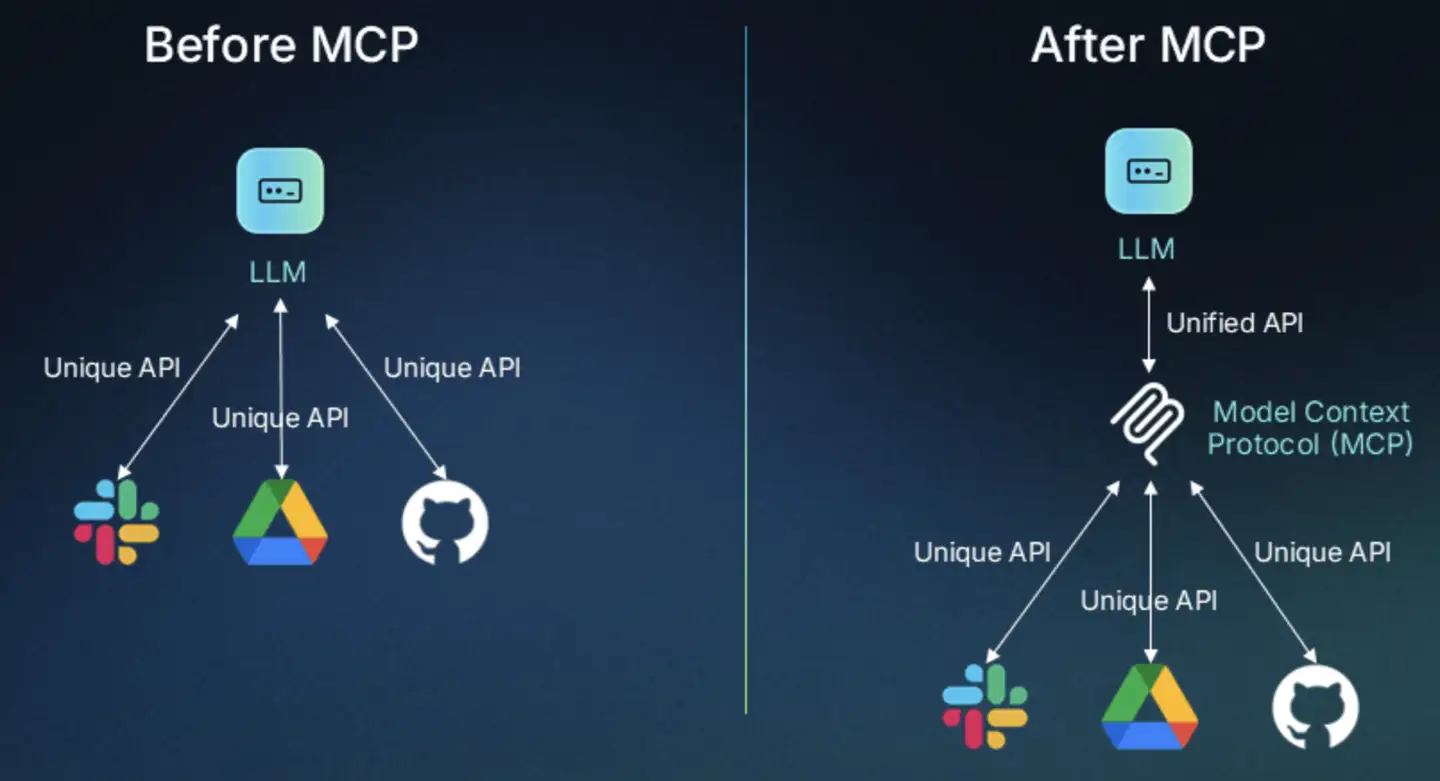
二者都是扩展LLM能力的一种手段。
Agent Skills 是一种标准化的程序性知识封装格式。如果说 MCP 为智能体提供了"手"来操作工具,那么 Skills 就提供了"操作手册"或"SOP(标准作业程序)",教导智能体如何正确使用这些工具。
这种设计理念源于一个简单但深刻的洞察:连接性(Connectivity)与能力(Capability)应该分离。MCP 专注于前者,Skills 专注于后者。这种职责分离带来了清晰的架构优势:
MCP 的职责:提供标准化的访问接口,让智能体能够"够得着"外部世界的数据和工具
Skills 的职责:提供领域专业知识,告诉智能体在特定场景下"如何组合使用这些工具"
MCP
在使用上的不同之处在于,MCP的流程是通过mcp client去server中拿到工具的列表,作为一个整体的上下文一股脑的进行塞入,后续的function call基于tool的schema再通过rpc进行调用(在这里是一种”倒置控制权“的RPC)。
这里的rpc与传统的rpc都是一项技术,但使用上略有不同:
-
传统微服务架构的rpc,整体的调用链都是确定的:

-
引入MCP:
本质区别在于”谁决定调用什么”,这里增加了不确定性——一种将控制权交给LLM的控制反转。
因此,会引入几个问题:
- Confused Deputy:MCP放大了这一点,MCP Server无法判断这是用户的真实意图还是LLM的幻觉,还是一次具体的攻击
- Trace黑洞->可观测性断裂:我们可以看到数据库报错,却不知道这是哪一次用户提问触发的
- 无状态协议和有状态业务的结构性冲突:MCP 协议本身不提供状态机、不支持事务、不记录中间结果。所有状态必须由 LLM 在上下文中“记住”,极易因 Token 截断或生成错误而丢失。
以上问题并非无法解决:
- 针对第一个问题,构建治理体系:注册、鉴权、校验、审计等
- 可观测性:trace id的全链路可追溯
- 使用边界:只用于低风险、只读、封闭场景。
MCP的实现并不复杂,server只需要设计好工具,把外部服务方的功能告诉LLM,然后等LLM来调用就好了。
MCP最大的问题,其实还是对于上下文的占用。
在mcp的场景中:
1 | System Prompt = 基础指令 + 所有工具描述 + 所有专业知识 |
大多数时候用户只需要其中一小部分能力。当用户问"帮我处理这个PDF"时,系统却加载了处理Excel、数据库、代码等所有能力的上下文。
SKILL
Claude Skils则换了种方式,这里就舍弃了通过代码构建MCP Server的方式,转而用SKILL.md进行替代,即在这个md文件中,用自然语言描述了如下信息:
- 具体任务对应的具体流程
- 有什么代码能用
简单来说,Skill是一种标准化的能力封装格式,它像是一本为AI编写的百科全书。与传统的API文档不同,Skill采用了一种层次化的目录结构,让AI能够像人类查阅手册一样快速定位所需知识。
举个例子,一个PPT制作Skill可能包含:
- SKILL.md文件:详细描述了具体操作方法和资源位置
- 目录:“PPT模版”、“PPT创作工具”、“内容规划指南”
渐进式披露
Agent Skill最核心的创新在于渐进式披露(Progressive Disclosure)机制。这种机制将技能信息分为三个层次,智能体按需逐步加载,既确保必要时不遗漏细节,又避免一次性将过多内容塞入上下文窗口。
1. 元数据(Metadata)
在 Skills 的设计中,每个技能都存放在一个独立的文件夹中,核心是一个名为SKILL.md的 Markdown 文件。这个文件必须以 YAML 格式的 Frontmatter 开头,定义技能的基本信息。
当智能体启动时,它会扫描所有已安装的技能文件夹,仅读取每个SKILL.md的 Frontmatter 部分,将这些元数据加载到系统提示词中。根据实测数据,每个技能的元数据仅消耗约100 个 token。即使你安装了 50 个技能,初始的上下文消耗也只有约 5,000 个 token。
这与 MCP 的工作方式形成了鲜明对比。在典型的 MCP 实现中,当客户端连接到一个服务器时,通常会通过tools/list请求获取所有可用工具的完整 JSON Schema,可能立即消耗数万个 token。
1 | --- |
2. 技能主体(Instructions)
当智能体通过分析用户请求,判断某个技能与当前任务高度相关时,它会进入第二层加载。此时,智能体会读取该技能的完整SKILL.md文件内容,将详细的指令、注意事项、示例等加载到上下文中。
此时,智能体获得了完成任务所需的全部上下文:数据库结构、查询模式、注意事项等。这部分内容的 token 消耗取决于指令的复杂度,通常在 1,000 到 5,000 个 token 之间。
3. 附加资源(Scripts & References)
对于更复杂的技能,SKILL.md可以引用同一文件夹下的其他文件:脚本、配置文件、参考文档等。智能体仅在需要时才加载这些资源。
例如,一个 PDF 处理技能的文件结构可能是:
skills/pdf-processing/
├── SKILL.md # 主技能文件
├── parse_pdf.py # PDF 解析脚本
├── forms.md # 表单填写指南(仅在填表任务时加载)
└── templates/ # PDF 模板文件
├── invoice.pdf
└── report.pdf
在SKILL.md中,可以这样引用附加资源:
- 当需要执行 PDF 解析时,智能体会运行parse_pdf.py脚本
- 当遇到表单填写任务时,才会加载forms.md了解详细步骤
模板文件只在需要生成特定格式文档时访问
这种设计有两个关键优势:
- 无限的知识容量:通过脚本和外部文件,技能可以"携带"远超上下文限制的知识。例如,一个数据分析技能可以附带一个 1GB 的数据文件和一个查询脚本,智能体通过执行脚本来访问数据,而无需将整个数据集加载到上下文中。
- 确定性执行:复杂的计算、数据转换、格式解析等任务交给代码执行,避免了 LLM 生成过程中的不确定性和幻觉问题。
具体内容如下:
SKILL Structrue
每个skill都是一个文件夹,其中包含一个SKILL.md带有 YAML frontmatter 的文件:
1 | skill-name/ |
注意到,这里除了SKILL.md,其他几个都是可选的。
具体展开:
SKILL.md :核心文件,必须存在。里面用YAML写元数据(名字、描述),用Markdown写详细的指令,告诉Claude在什么情况下、以及如何使用这个Skill。
scripts/ :存放可执行的Python、Shell脚本。比如PDF处理Skill里,就有fill_fillable_fields.py这种确定性极强的代码。
references/resources :存放参考文档。比如API文档、数据库Schema、公司政策等,这些是给Claude看的知识库。
assets :存放资源文件。比如PPT模板、公司Logo、React项目脚手架等,这些是Claude在执行任务时直接使用的文件,而不是阅读的。
这里有个发现是,似乎除了SKILL.md和scripts目录外,其他的目录名称都不是固定的。
仓库:
这里有一堆现成的skils:https://github.com/ComposioHQ/awesome-claude-skills/tree/master
比较
所以SKILL相较于MCP,到底有什么优势与不同呢?
三点不同
根据相关说明,暂列为以下几点:
-
资源级别
-
节省token: mcp的实现中,这里会一股脑将mcp server中的所有的工具信息都塞进上下文;而SKILL这里能够按需动态加载上下文,在用到某个具体的Skill时就去读取对应的文件到context即可。
-
本质上说,在上下文工程方面,其能够准确精炼地给LLM提供上下文。
- MCP是急切加载,一次加载终生使用
- Skills是惰性加载,按需加载
-
比如,让Claude“提取PDF里的表单数据”,它会自动加载「pdf skill」,不用你手动贴规则;而且只会加载当前任务需要的信息,不会让上下文“臃肿过载”,处理复杂任务时速度和准确率都明显提升。
-
用户请求 → Agent识别需要PDF技能 → 动态加载PDF处理指令 → 执行专业任务 → 返回结果1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
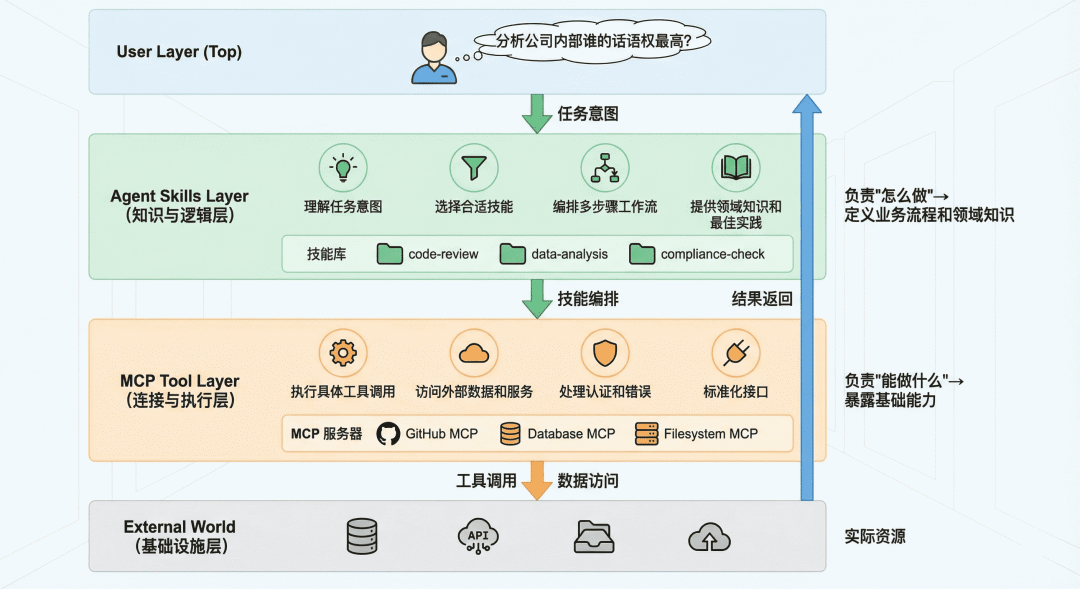
2. 工程视角:
1. MCP:能访问这些API,能调用API
2. Skills 告诉智能体"应该"做什么、如何组织审查流程、需要关注哪些公司特定的规范。
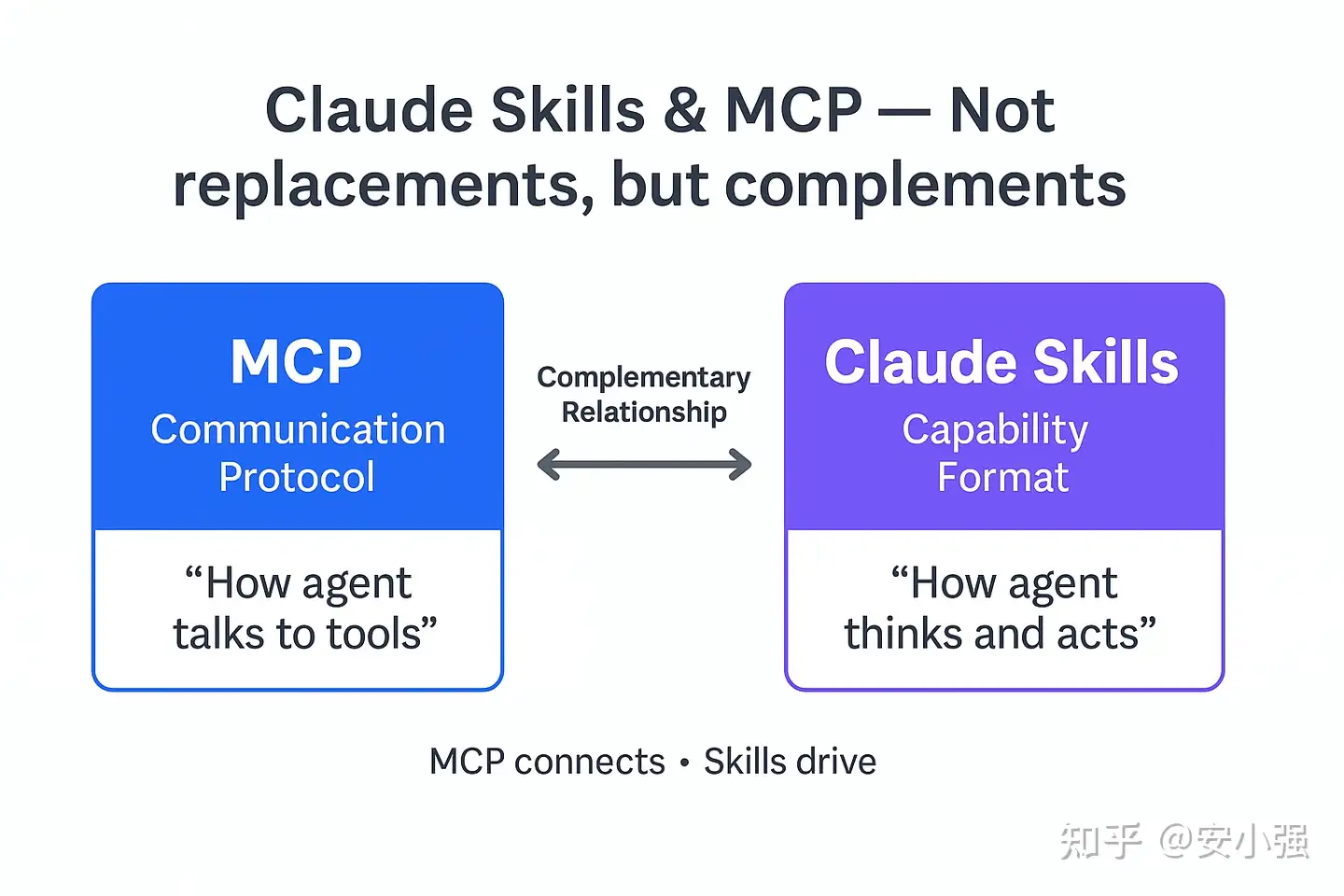
3. 关系:并非竞争,而是互补
- 让MCP专注于”能力“:工具本身的使用、查询等
- 而Skills专注于”计划“:
- 识别任务,加载技能
- 分解子步骤
- 根据MCP的执行结果和skill的领域知识,解读结果并生成分析
Skill里的知识可以指导Agent如何更有效地去使用一个遵循MCP协议的工具。一个Agent完全可以加载一个Skill,然后根据Skill里的指令,去调用一个远程的MCP服务器。
### Token消耗
在社区有实践案例:
- **传统 MCP 方式**:直接连接一个包含大量工具定义的 MCP 服务器,初始加载消耗**16,000 个 token**
- **Skills 包装后**:创建一个简单的 Skill 作为"网关",仅在 Frontmatter 中描述功能,初始消耗仅**500 个 token**
初始阶段差了32倍
## 实践:TODO
目前在vs code中还不支持skill。
目前似乎只能在Claude Code,Claude.ai和 API中使用。后续待补充。
不过目前有一些编写Skill的原则:
### 编写Skill的原则
1. description的编写:这部分尤其重要,因为在初始加载时只会加载相关元数据(description就是其中一部分关键的数据)
- 精准的描述(Description):
- 定义适用场景与范围
- 包含能够触发的关键词(意图识别与匹配)
- 独特之处(同样是避免llm混淆)
- e.g.
- ```markdown
// 反面例子:
description:处理数据库查询
// 证明例子
description: 将中文业务问题转换为 SQL 查询并分析 MySQL employees 示例数据库。 适用于员工信息查询、薪资统计、部门分析、职位变动历史等场景。 当用户询问关于员工、薪资、部门的数据时使用此技能。
-
-
-
-
模块化单一职责:一个Skill应该专注于一个明确的领域,而非所谓集大成者:
- 一方面,这样便于description的编写,有助于意图识别
- 同时,节省上下文,便于解耦和skill的维护
-
确定性有限原则:
对于复杂的、需要精确执行的任务,优先去维护一个确定的script(.py/.sh),而非让LLM自己去生成
-
渐进式披露原则:
根据skiil的执行过程的原理,将信息按照阶段、重要性进行合理分层。
所以由此观之,Skiil也并非银弹,也需要不断去设计和维护,涉及到类似prompt调优的工作
源码
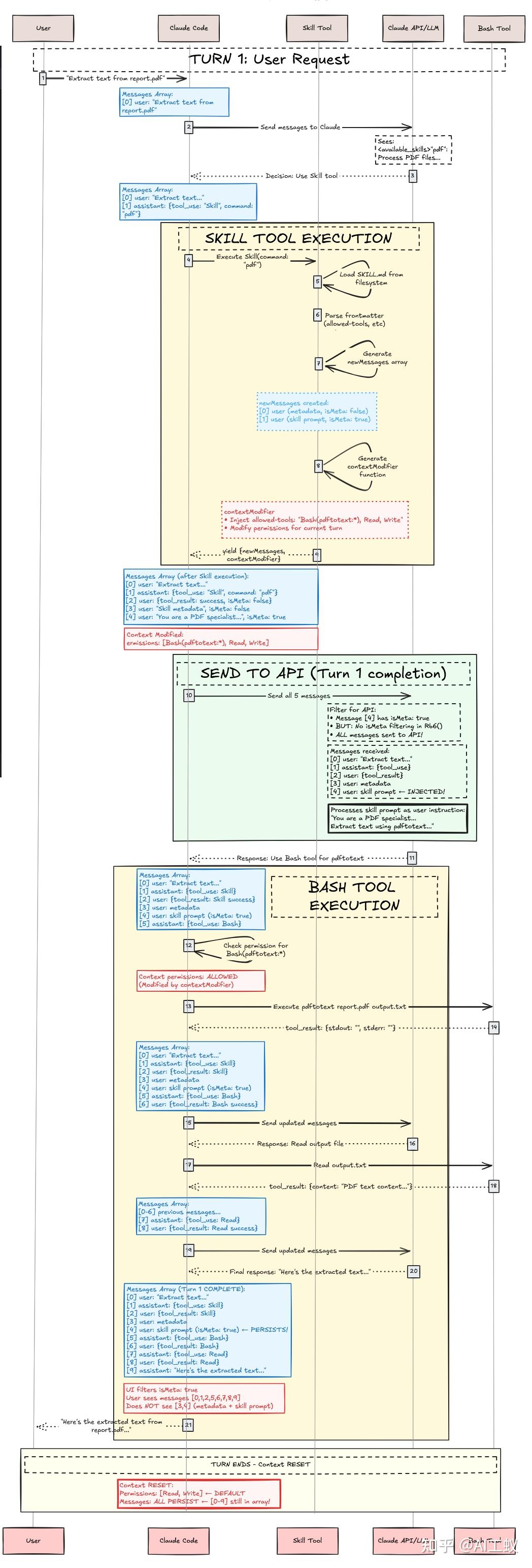
所以为什么claude回去目录下读取这些skiil呢?到底是怎么实现的呢?
有人逆向分析出来了:https://zhuanlan.zhihu.com/p/1984015383276041355
Claude
Phase 1:Discovery & Loading(启动时)
1 | Claude Code 启动 |
最开始这里,直接在Claude启动时,就回去固定的路径下读取skill元数据,加载到SKILL工具的description中
1 | "tools":[ |
Phase 2:User Request & Skill Selection
1 | 用户请求:"Extract text from report.pdf" |
Phase 3:Skill Tool Execution
1 | 验证 → 权限检查 → 加载 SKILL.md |
Phase 4:Bash Tool Execution(带 Skill 上下文的工具使用)
1 | Claude 接收注入的对话上下文 |
类似的开源项目:
https://link.zhihu.com/?target=https%3A//github.com/femto/minion
minion版本的实现

完整流程步骤
阶段1:技能发现与注册
-
技能放置:用户将技能目录放置在标准位置:
- 项目级:
.minion/skills/或.claude/skills/ - 用户级:
~/.minion/skills/或~/.claude/skills/
- 项目级:
-
技能结构:每个技能目录包含:
1
2
3
4
5skill-name/
├── SKILL.md # 技能定义文件(YAML frontmatter + Markdown)
├── references/ # 参考文档
├── scripts/ # Python脚本
└── assets/ # 资源文件 -
自动加载:
SkillLoader扫描所有搜索路径,发现并加载技能 -
注册管理:
SkillRegistry管理已加载技能,处理优先级(项目级 > 用户级)
1 | SkillLoader.discover_skills() → 扫描目录 |
注入的内容包括:
- 技能使用说明:如何调用技能
- 可用技能列表:所有技能的元数据(名称、描述、位置)
- 但不包含:技能的具体指令内容
setup阶段注入的是元数据:
1 | <available_skills> |
阶段2:代理集成
-
工具添加:创建代理时包含
SkillTool:1
2
3agent = await CodeAgent.create(
tools=[SkillTool(), BashTool(), ...]
) -
提示注入:
CodeAgent.setup()中自动检测SkillTool并注入技能提示:- 调用
generate_skill_tool_prompt()生成技能列表 - 将技能提示追加到
system_prompt
- 调用
-
系统提示更新:最终系统提示包含:
- 原始系统指令
- 技能使用说明
- 可用技能列表(XML格式)
1 | # minion/agents/code_agent.py |
阶段3:运行时执行
-
技能识别:LLM根据用户请求和可用技能列表,决定是否调用技能
-
技能调用:代理调用
SkillTool:1
2# LLM生成的工具调用
SkillTool(skill="data-analysis") -
技能加载:
SkillTool.execute_skill():- 从注册表获取技能对象
- 返回技能提示和元数据
- 包含基础目录路径用于解析相对资源
-
指令注入:技能的具体指令被注入到对话上下文中
-
继续执行:代理使用技能指令继续处理任务
具体内容在调用时才加载:
minion/tools/skill_tool.py
1 | # minion/tools/skill_tool.py |
流程对比:
setup阶段(初始化时):
1 | 1. 扫描技能目录 → 发现所有SKILL.md文件 |
调用阶段(运行时):
1 | 1. LLM根据任务决定调用哪个技能 |
关键设计特点
- 模块化设计:
- 技能系统与代理系统解耦
- 通过
SkillTool作为桥梁连接 - 支持动态加载和卸载技能
- 优先级管理:
- 项目级技能覆盖用户级技能
- 支持技能版本管理
- 资源解析:
- 技能执行时提供基础目录路径
- 支持相对路径引用(
references/,scripts/,assets/)
- 提示工程:
- 技能指令作为Markdown格式
- XML格式的技能列表便于LLM解析
- 清晰的技能使用说明
- 向后兼容:
- 无技能时正常运作
- 技能工具作为可选组件
- 不影响现有代理功能
使用示例
1 | # 1. 创建带技能的代理 |
评价与总结
Agent Skills 与 MCP(Model Context Protocol)代表了构建下一代 AI 智能体(Agent)架构的两个关键抽象层,它们分别从“连接性”与“能力性”两个维度推动了 LLM 能力的工程化落地:
- MCP(Model Context Protocol)
聚焦于“连接性”(Connectivity)——为智能体提供标准化、可互操作的外部工具访问能力。它相当于智能体的“神经系统”或“双手”,负责打通 LLM 与外部世界的接口。然而,MCP 的急切加载机制(eager loading)导致上下文臃肿、成本高昂,且在复杂业务场景下面临状态管理、可观测性和安全治理等挑战。 - Agent Skills
聚焦于“能力性”(Capability)——以标准化、模块化、可复用的方式封装领域知识与操作流程。它如同智能体的“大脑皮层”或“SOP 操作手册”,指导 LLM 在什么时机、以何种方式调用工具,并如何解读结果、组织推理。通过渐进式披露(Progressive Disclosure)机制,Skills 实现了上下文的按需加载,极大提升了 token 利用效率、推理精准度与系统可维护性。
互补而非替代
二者并非互斥方案,而是协同增强的关系:
- Skills 可以指导智能体如何有效使用 MCP 工具(例如:“在完成表单提取后,调用 MCP 提供的 validate_form 工具进行校验”);
- MCP 为 Skills 提供可执行的底层能力支撑(例如:Skills 中描述的“查询员工数据库”依赖于 MCP 暴露的 SQL 查询接口)。
在实际工程中,理想的智能体架构应是:Skills 负责任务规划与知识引导,MCP 负责原子操作执行,形成“计划–执行–反馈”的闭环。
其实我也有点存疑,既然skill是为了规避长上下文,这里又引入mcp干嘛?我想到的解释是这里mcp不是一个大杂烩了,而就是一个单纯的能够接入工具的接口,比如在skill中有编写相关连接mcp的方式,可能就会通过某些基本工具去连接mcp然后再去根据skill的spo去调用工具?所以说,两者是作为互补的,Skills 里面可以集成不同的 MCP,然后采用渐进式的读取策略以后,就不需要读取过多的 MCP 信息,从而达到节省 token 的效果。
“We’ll also explore how Skills can complement MCP servers by teaching agents more complex workflows that involve external tools and software.” --Anthropic
实践启示
- 上下文工程优先:在 LLM 上下文成为稀缺资源的今天,惰性加载(lazy loading)和分层披露是提升系统效率的关键设计原则。
- 确定性下沉:将易出错、高精度要求的操作(如 PDF 填写、数据清洗)封装为脚本,由 LLM 调用而非生成,可显著降低幻觉风险。
- 模块化治理:每个 Skill 应遵循单一职责原则,便于组合、测试、版本迭代与权限控制。
- 可观测性设计:即使采用 Skills 架构,仍需在技能调用链路中注入 trace ID,确保从用户提问到脚本执行的全链路可追踪。
其实许多公司内部(如字节)也有类似的设计,只不过anthropic还是太有话语权了。