WebDancer:Towards Autonomous Information Seeking Agency
WebDancer: Towards Autonomous Information Seeking Agency
论文标题:WebDancer: Towards Autonomous Information Seeking Agency
论文链接:https://arxiv.org/pdf/2505.22648
论文代码:https://github.com/Alibaba-NLP/DeepResearch
这篇论文介绍了一个基于ReAct范式的网络智能体——WebDancer,通义团队透过训练赋予其自主寻求信息的能力。通义团队的训练流程主要有四个步骤,构造问答对、获得高质量轨迹、监督微调和强化学习。
问答对构造
不同于之前的简单的2到3步就能解决的问答问题,通义团队这里主要想构造的是那些可以激发模型多步推理、目标分解、交互等能力的问答对数据,因此希望对多跳推理的广度和深度都进行扩展。为此,他们提出了两个问答对数据集——CRAWLQA和E2HQA。
CRAWLQA问答对的获取跟之前WebWalkerQA数据集的构造很类似,都是从一个根网页出发递归浏览其中链接指向的网页,基于收集的内容令模型合成问答对。E2HQA的构造借鉴了BrowseCamp和BrowseCamp-zh的方法,它从大量的SimpleQA风格的问答对开始,对一个问答对,每次迭代取问题中的一个实体,构造一个查询该实体的查询,用以替换该实体,从而造成了模型要回答该问题,就必须先解决得到这个实体的子问题,不断迭代得到一个更为复杂的问题,而其最终答案不变。
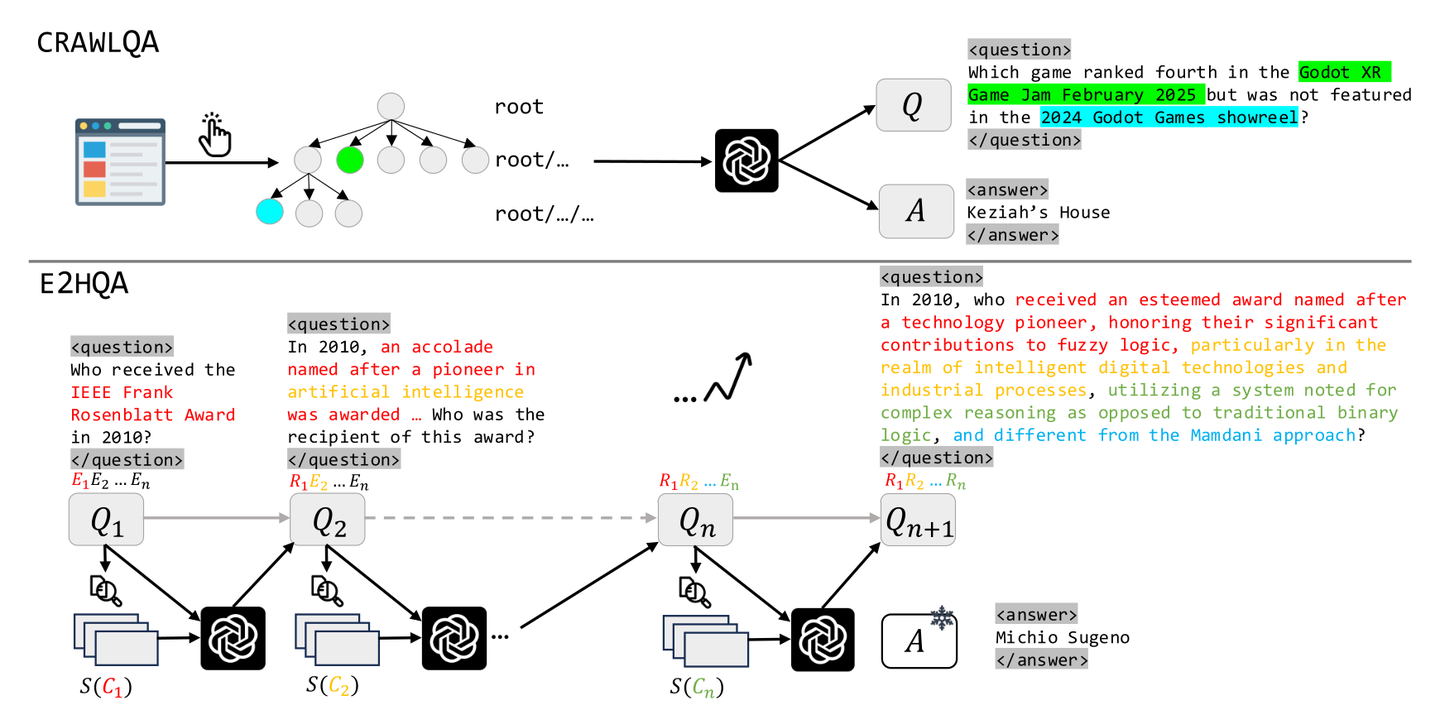
其实这里有点没看懂
1. CRAWLQA(基于网页爬取的问答对构造)
📌 核心思想:
通过爬取真实网站内容,从中自动合成需要多跳推理、点击操作才能回答的复杂问题。
🔧 构建流程:
- 收集根 URL:从权威网站(如 arXiv、GitHub、Wikipedia 等)获取根页面链接。
- 模拟人类浏览行为:
- 递归地点击页面上的子链接,深入爬取子页面内容。
- 构建一个“知识树”:root → root/… → root/…/…
- 用 LLM(如 GPT-4o)生成 QA 对:
- 输入爬取到的网页文本内容。
- 提示 LLM 生成特定类型的问题(如 COUNT、MULTI-HOP、INTERSECTION 等)。
- 保证问题依赖页面中的具体信息,且答案明确。
- 问题特性:
- 需要点击操作(visit)才能获取答案(例如跳转到子页面)。
- 支持多步交互轨迹(如先搜索,再点击)。
✅ 举例:
Question: “Which game ranked fourth in the Godot XR Game Jam February 2025 but was not featured in the 2024 Godot Games showreel?”
Answer: “Keziah’s House”
→ 该问题需先访问比赛页面(可能通过搜索找到),再查看排名和 showreel 名单,进行对比。
2. E2HQA(Easy-to-Hard QA,从简单到复杂的问答对演化)
📌 核心思想:
从一个简单事实型问题出发,通过迭代引入新实体和外部信息,逐步“复杂化”问题,使其需要多步检索才能解答。
🔧 构建流程(迭代式):
- 起始点:一个简单的 QA 对,如
- Q₁: “Who received the IEEE Frank Rosenblatt Award in 2010?”
- A: “Michio Sugeno”
- 选择实体:从 Q₁ 中选取答案实体(如 “Michio Sugeno”)。
- 检索新信息:用搜索引擎查询该实体(e.g.,
S(C₁) = search("Michio Sugeno fuzzy logic"))。 - 重写问题:用 LLM 将新检索到的信息(C₁)融入原问题,生成更复杂的问题 Q₂:
- Q₂: “In 2010, who received an esteemed award named after a technology pioneer, honoring their significant contributions to fuzzy logic…?”
- 保持答案不变:在整个演化过程中,答案始终是原始实体(Michio Sugeno),确保 QA 对有效性。
- 重复迭代:可多次执行上述过程,生成 n-hop 的复杂问题。
✅ 优势:
- 自动控制任务难度(通过迭代次数)。
- 强制模型进行多步推理 + 多次工具调用。
- 生成的问题更贴近真实用户提出的复杂查询。
获取高质量轨迹
通义团队要求智能体输出的轨迹仍然是遵循ReAct范式,即思考-行动-观察流程。智能体会根据问题和历史轨迹进行思考,以决定下一步之行动,采取行动后拼接环境给予之反馈,进入下一个思考。这里模型可以采取的行动有三种——搜索、访问和回答。
- 搜索:给定查询和过滤年份作为参数,得到搜索结果前十条的标题和片段
- 访问:给定目标和URL链接作为参数,得到证据和总结
- 回答:当动作为回答时,循环终止
思维链对于提高Agent模型的能力十分重要,通义团队提出了获取两种不同思维链的方法。对于短思维链的获取,他们直接使用ReAct框架取得;而对于长思维链,则是借助推理模型(这里他们用的是QwQ-Plus),具体而言是每一次将历史动作和对应观察作为输入(这里通义团队没有将历史的思考加入输入,他们认为推理模型训练的时候没有接触过这样的内容),令模型预测下一个动作,然后该动作即作为新一轮的动作,而对应的推理内容("<reasoning_content>"标签中的内容)则作为思考内容加入轨迹。
为了得到高质量的轨迹数据,通义团队对得到的轨迹进行了过滤,过滤分为三个阶段:有效性控制(实际上就是格式过滤)、正确性验证和质量评估。 - 有效性控制:过滤掉那些不符合ReAct格式要求的轨迹
- 正确性验证:仅保留结果正确的轨迹
- 质量评估:过滤掉采取了超过两个动作的轨迹(通义团队的解释是这些轨迹可能意味着幻觉和严重的重复,这里我实际上并不理解),然后过滤掉信息冗余、与目标不对齐或逻辑推理错误的轨迹。
这阶段过滤数据主要是为了给SFT提供高质量的监督数据,那些被过滤掉轨迹的问答对可以被用于RL的训练,而非直接丢弃。
监督微调
监督微调事实上就是将之前得到的高质量的轨迹用于微调模型,与一般的SFT是十分类似的,区别在于防止被外部反馈影响,计算损失的时候会忽略观察部分的标记。
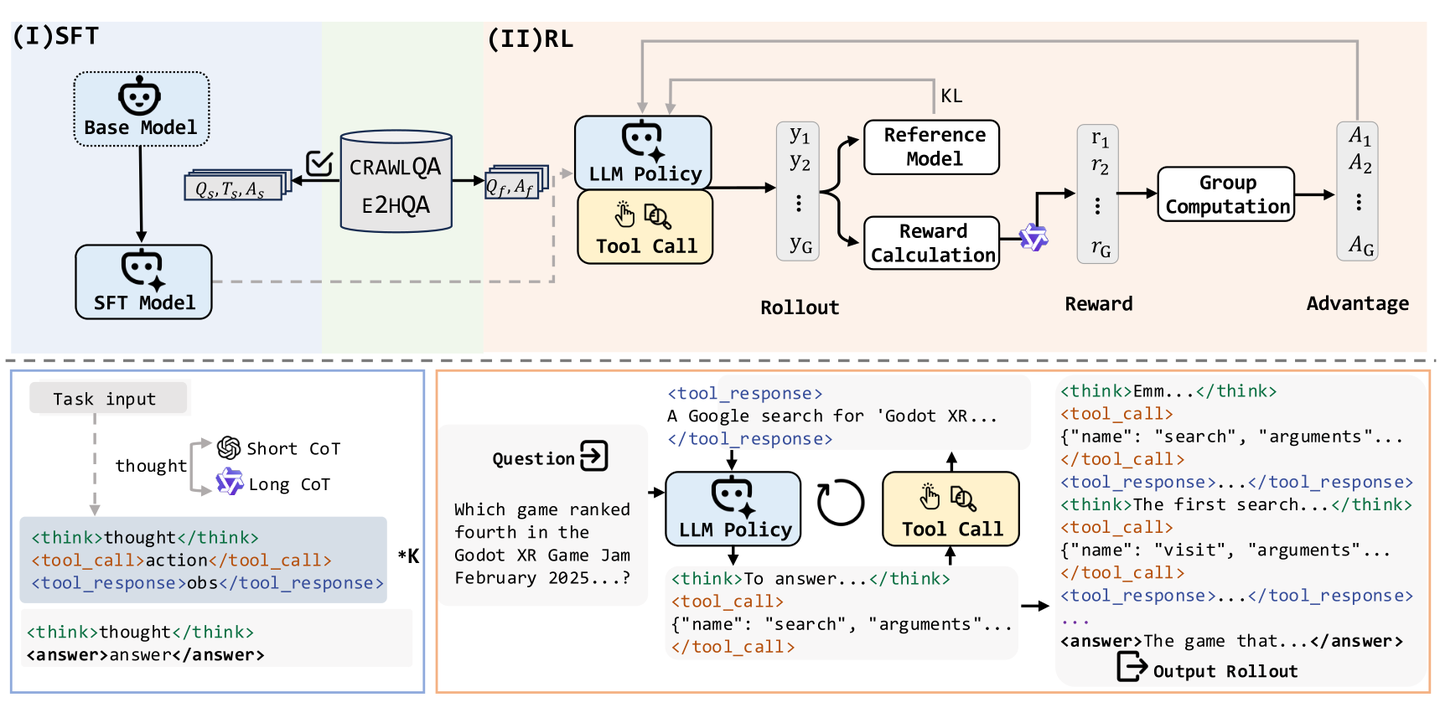
强化学习
强化学习采用的是字节提出的DAPO算法,跟SFT类似,计算损失的时候会将外部反馈(即观察)进行掩码。在Rollout的时候,思考会被 <think> 和 </think> 标签包围,而动作,如果是搜索和观察这类工具调用,会被 <tool_call> 和 </tool_call> 标签包围,而回答则是 <answer> 和 </answer> ,外部反馈,即观察,则是被 <tool_response> 和 </tool_response> 包围。奖励函数包含格式奖励和答案奖励两个部分,其中格式奖励仅当格式遵循ReAct格式并且所有JSON格式的工具调用都合法的适合为1,其余情况为0。由于问答问题不能使用基于规则或是F1或精确匹配的方式验证正误,这里通义团队使用大语言模型来判断正确与否,即所谓的LLM-as-Judge或者所谓的GenRM(生成式奖励模型)。最终的奖励为二者的加权和。
实验结果
通义的实验表明,他们提出的WebDancer比其他的直接使用ReAct提示的模型在GIGA和WebWalkerQA两个Benchmark上表现稳定地更优
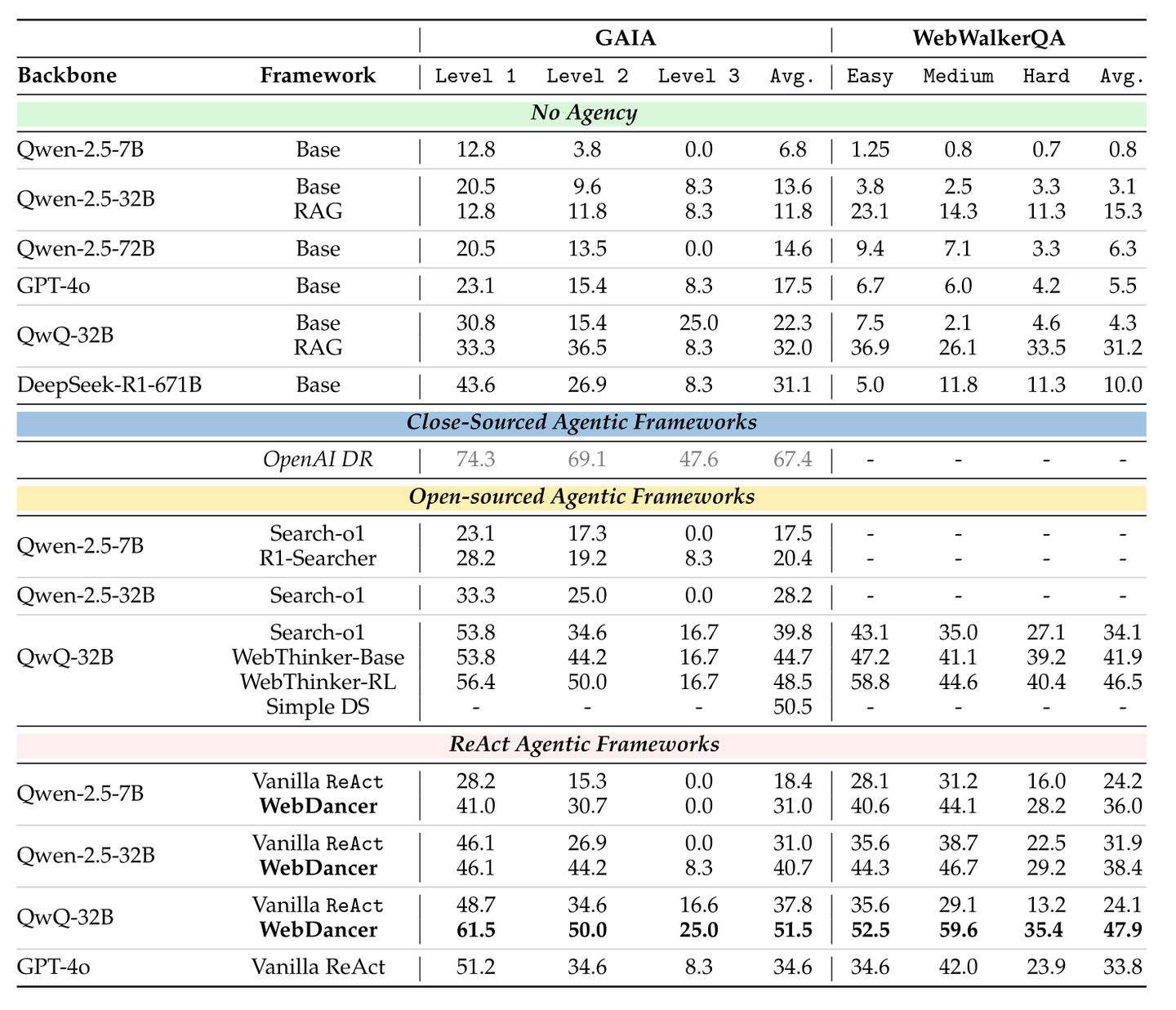
在更有挑战性的BrowseCamp和BrowseCamp-zh上,表现也比GPT-40和QwQ-32B更优

分析
通义团队分析了实验结果,作出了一些分析:
- 高质量的轨迹数据对于高效的监督微调至关重要
- 监督微调可以增强模型多步多工具指令跟随能力,对于冷启动是十分必要的
- 强大推理模型的思考范式知识要迁移到指令模型存在困难
- 强化学习使得模型能够进行更长的推理和支持更复杂的智能体动作
- Web智能体在不断变化的环境中运行,很难保持稳定