DeepResearch智能体方案
DeepResearch智能体方案
通义dr的解读:
https://zhuanlan.zhihu.com/p/1953262318352863784
关键在于训练一个专门的模型,为DR而生。
为什么通义DeepResearch不需要 chunk?RAG正在被Agent改写
https://zhuanlan.zhihu.com/p/1968442243783294997
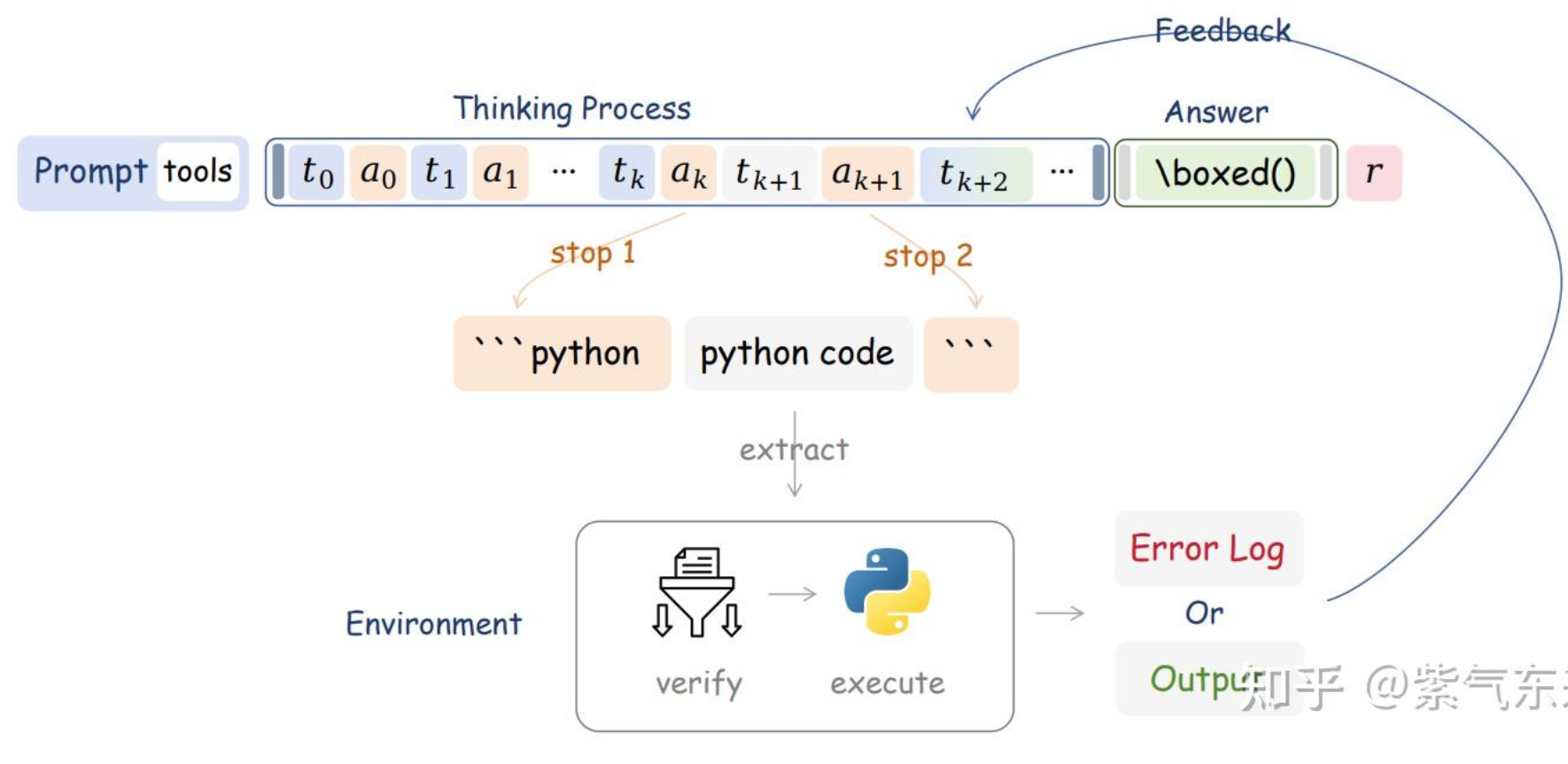
CPT->SFT->RL
DeepResearch 之所以不需要传统 RAG 的Chunking,是因为它从根本上改变了范式。
- 传统 RAG 是一个静态系统,模型是被动缝合你喂给它的碎纸片 (Chunks)。
- DeepResearch 是一个动态系统。模型是研究员,它主动去获取完整的信息(网页/文档),然后利用IterResearch范式(压缩笔记)来管理自己的认知焦点,再利用RL来优化自己的研究策略。
所以,RAG 不会被取代,而是正在被 DeepResearch 这样的 Agent 框架吸收和升维——检索不再是一个外部模块,而是 Agent 工具箱里一个最基础的动作而已。
JINA
看jina的这篇:https://zhuanlan.zhihu.com/p/26560000573
AI Search:
- Tavily: 整合多个现有搜索引擎(如 Bing、Google等)的搜索结果进行排序和过滤。Travily做的关键的事有三点: 查询重写(Query Rewriting):用NLP技术优化用户的Query。 去重和聚合(Deduplication & Aggregation):从多个来源中聚合信息,剔除重复链接。 结果重排序(Reranking):使用 LLM 或嵌入模型对搜索结果进行语义排序,提高相关性。
Deep Search:
- open ai 端到端大力出奇迹(一定的训练手段让模型自己去进行搜索与反思,特化模型)
- 构建长的搜索推理思维链的数据(COT),走RL能比SFT提供更好的泛化性能
- 非特化模型,工程化实现搜索+推理+搜索:
- 文本生成和搜索工具调用交替的过程
- 迭代执行搜索
- 原始问题->多个搜索query
- 特殊token标记搜索的调用:
- prompt-based
- sft-based
- rl-based
- 迭代执行搜索
- 文本生成和搜索工具调用交替的过程
DeepSearch 是 DeepResearch 的构建模块,是后者赖以运转的核心引擎。
换个角度来看,DeepSearch 可以被视作一个配备了各类网络工具(比如搜索引擎和网页阅读器)的 LLM Agent。

系统提示词:
在系统提示词的设计上,使用 XML 标签来定义各个部分,这样可以生成更健壮的系统提示词和生成内容。
知识空白问题处理:
在 DeepSearch 中,“知识空白问题”指的是在回答核心问题之前,Agent 需要先补足的知识缺口。Agent 不会直接尝试回答原始问题,而是会识别并解决那些能够构建必要知识基础的子问题。
对于知识空白问题,采用FIFO
FIFO(先进先出)队列,遵循以下规则:
- 新的知识空白问题会被优先推到队列头部。
- 原始问题始终位于队列尾部。
- 系统在每个步骤都从队列头部提取问题进行处理。
这种设计的精妙之处在于,它为所有问题维护了一个共享的上下文。也就是说,当一个知识空白问题被解决后,获得的知识可以立即应用于所有后续问题,最终也会帮助我们解决最初的原始问题。
查询重写:
查询重写的重要性远超预期,甚至可以说是决定搜索结果质量的最关键因素之一。一个优秀的查询重写器,不仅能将用户的自然语言转化为更适合 BM25 算法处理的关键词形式,还能扩展查询,从而覆盖不同语言、语调和内容格式下的更多潜在答案。
查询去重:没采用LLM的方式,采用embedding进行相似度层面的匹配去重(这里就是针对query去重,而非查询到的内容)。
爬取网页内容:
完整网页内容+搜索引擎返回的摘要片段。
URL规范化+限制每个步骤访问URL的数量。
内存管理:
考虑到 2025 年 LLM 的超长上下文趋势,我们选择放弃向量数据库,转而采用上下文记忆的方法。Agent 的记忆由上下文窗口内的三部分组成:获得的知识、访问过的网站以及失败尝试的日志。这种方法使 Agent 能够在推理过程中直接访问完整的历史记录和知识状态,无需额外的检索步骤。
答案评估:
答案生成和评估放在不同的提示词中完成效果更好。
这里评估会根据问题生成一批评估标准,然后针对每个评估标准对qa进行评估,只有每个标准符合要求后才会pass结束,否则继续思考。
预算控制:
需要灵活启用或禁用某些操作,比如回答失败后强制进行反思。
失败尝试的次数,强制进行总结(夸张的提示词)。
总结
首先,一个能生成规范格式输出(比如 JSON Schema)的长上下文 LLM 是非常必要的。也许还需要一个推理模型,提升行动推理和查询扩展的能力。
查询扩展也绝对是刚需,无论是使用 SLM、LLM,还是专门的推理模型来实现,都是绕不开的环节。但做了这个项目后,我们发现 SLM 可能不太适合这个任务,因为查询拓展必须是天生支持多语言的,而且不能仅仅局限于简单的同义词替换或关键词提取。它得足够全面,具备涵盖多语言的 Token 基础(这样规模很容易达到 3 亿参数),还得足够智能,能够跳出思维定势。所以,单靠 SLM 进行查询扩展可能是行不通的。
网页搜索和网页阅读能力,毫无疑问是重中之重,幸好我们的 [Reader (r.jina.ai)] 表现非常出色,不仅功能强大,而且有良好的扩展性,这也激发我对如何改进我们的搜索端点(s.jina.ai)的诸多灵感,在下一次迭代中可以重点优化。
向量模型是有用的,但用到的地方完全出乎意料。 我们本来以为它会用于内存检索,或者配合向量数据库来压缩上下文,但事实证明都不需要。最终,我们发现将向量模型用于去重效果最好,本质上是一个 STS(语义文本相似度)任务。由于查询和知识缺口的数量通常在数百个范围内,不需要动用向量数据库,直接在内存中计算余弦相似度就完全足够了。
我们没有采用 Reranker 模型,但从理论上讲,它可以根据查询、URL 标题和摘要片段来辅助判断哪些 URL 应该优先访问。对于 Embeddings 和 Reranker 模型来说,多语言能力是基本要求,因为查询和问题都是多语言的。长上下文处理对 Embeddings 和 Reranker 模型有一定帮助,但并非决定性的因素。我们没有遇到任何由向量使用导致的问题,这可能得益于 jina-embeddings-v3 优秀的上下文长度,达到了 8192 token)。综合来看,jina-embeddings-v3 和 jina-reranker-v2-base-multilingual 仍然是我的首选,它们具备多语言支持、SOTA 性能,以及良好的长上下文处理能力。
Agent 框架最终被证明是不必要的。 在系统设计上,我们更倾向于贴近 LLM 的原生能力,避免引入不必要的抽象层。Vercel AI SDK 在适配不同 LLM 供应商方面提供了很大的便利,极大地减少了开发工作量,只需修改一行代码即可在 Gemini Studio、OpenAI 和 Google Vertex AI 之间切换。代理内存管理是有意义的,但为此引入专门的框架还值得商榷。我个人认为,过度依赖框架可能会在 LLM 和开发者之间筑起一道屏障,其提供的语法糖可能会成为开发者的负担。许多 LLM/RAG 框架已经验证了这一点。拥抱 LLM 的原生能力,避免被框架束缚,才是更明智的选择。