verl框架学习
verl框架学习
https://zhuanlan.zhihu.com/p/24682036412
https://zhuanlan.zhihu.com/p/27676081245
verl资源管理:https://zhuanlan.zhihu.com/p/1943781624954192493
核心概念:
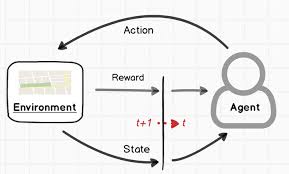
Ray:
Ray 是一个分布式计算框架,现在流行的RL框架如VeRL和OpenRLHF都依托Ray管理RL中复杂的Roles(比如PPO需要四个模型)和分配资源。以下是一些核心的概念:
- Ray Actor:有状态的远程计算任务,一般是被ray.remote装饰器装饰的Python类,运行时是一个进程(和PPO等Actor-Critic算法的Actor不要混淆了);
- Ray Task:无状态的远程计算任务,一般是被ray.remote装饰器装饰的Python函数,创建的局部变量仅在当前可见,对于任务的提交者不可见,因此可以视作无状态;
- 资源管理:Ray可以自动管理CPU、GPU、Mem等资源的分配(通过ray.remote装饰器或者启动的options参数可以指定指定的ray actor所需的计算资源),并且还可以设计资源组(placement group),将不同的ray actor指定放置在相同或者不同的资源位置(bundle);
- 通过使用ray,verl可以方便地实现各种角色、各种并行策略的资源分配,并且实现hybrid engine等colocate策略;
- 异步执行:ray的计算是异步的,一般执行一个ray的计算任务后,ray会立刻返回任务的执行句柄Object reference,用户的代码不会阻塞,可以自行使用ray.get/ray.wait进行阻塞式/轮询式的结果获取;
- PS: 在RL训练中引入异步的概念,可以方便actor/critic/generator/rm之间互相overlap掉一些处理时间(比如actor在更新上一个batch的时候,generator已经可以生成下一个batch了)。由于o1-liked rl的主要时间卡点在rollout位置,因此将rollout 更好地aynsc化(例如充分利用线上serving集群的夜晚空闲时间)是未来 rl infra优化的方向之一;
在 VeRL(Vision and Embodied Reinforcement Learning)框架中,“colocate”(共置)指的是多个模型(如 Actor、Critic、Reward Model、Generator 等)被部署在同一组计算资源(如同一组 GPU)上,并按时间片交替运行,而非各自独占资源。
RayWorkerGroup的作用
RayWorkerGroup 是“资源池”与“Worker 实现类”之间的粘合层——它拿到“在哪干”(RayResourcePool)和“怎么干”(Worker 类)后,真正在 Ray 集群里启动 actor 进程,并对外暴露统一的接口。
- 资源池(RayResourcePool)
只回答“有哪些 GPU/节点可用”,不会启动任何进程。 - Worker 类(如 FSDPActorRolloutWorker)
只回答“算法逻辑怎么写”,不知道自己会在哪台机器上跑。 - RayWorkerGroup 的职责
- 把上面两者“绑”在一起:
RayWorkerGroup(resource_pool=..., ray_cls_with_init=...) - 在
spawn()里遍历资源池的 GPU 拓扑,为每一块(或每一组)GPU 调用
ray.remote(...).options(num_gpus=k, resources=...).remote(...)
真正拉起 Ray actor 进程。 - 给上层暴露统一接口:
worker_group.generate_sequences(...)
内部通过 Ray 调用把请求路由到对应的 actor。
RayPPOTrainer整体的资源分配逻辑
RayPPOTrainer 通过 ResourcePoolManager 和 RayResourcePool 两个核心类,把「角色 → 资源池 → 物理 GPU」这三层映射关系串起来,实现为不同 worker group 按需分配 Ray 资源。下面按时间顺序把关键步骤拆开说明。
- 配置阶段:定义“资源池规格”
在训练脚本(如 main_ppo.py)里会构造一个ResourcePoolManager,核心字段只有两个:
1 | resource_pool_spec = { |
resource_pool_spec的 value 是一个 list,第 i 个元素代表“第 i 台节点上要几块 GPU”。mapping告诉系统:某个角色(如 ActorRollout)应该落到哪个资源池。
- 资源池初始化:把规格变成 Ray 对象
ResourcePoolManager.create_resource_pool() 会为每个 spec 创建一个 RayResourcePool:
1 | for name, process_on_nodes in self.resource_pool_spec.items(): |
RayResourcePool内部会调用ray.available_resources()做两次校验:
-
整个集群 GPU 总数够不够。
-
每个节点能否满足“单节点 GPU 数 × 节点数”的拓扑要求。
不满足直接抛ValueError,训练不会启动。 -
训练器初始化:把“角色”绑定到“资源池”
在 RayPPOTrainer.__init__() 里只是保存了 resource_pool_manager 和 role_worker_mapping,真正的 worker 还没创建。
- 真正创建 WorkerGroup:
init_workers()
这一步才把所有 Ray actor 真正拉起:
1 | self.resource_pool_manager.create_resource_pool() # 再次确认资源 |
RayWorkerGroup内部会为资源池里的每一块 GPU 启动一个 Ray actor(或一个 actor 占多卡,取决于 backend)。create_colocated_worker_cls允许把多个角色(如 actor + rollout)合并到同一个 actor 进程,减少跨进程通信。- 每个 actor 启动后执行对应 Worker 类的
__init__,完成模型加载、FSDP / Megatron 并行拓扑建立等。
- 运行期:worker group 与资源池一一对应
训练主循环里通过
1 | self.actor_rollout_wg.generate_sequences(...) |
即可把任务发到对应 Ray actor;Ray 的调度器会保证这些 actor 只运行在它们所属资源池划定的 GPU 上。
总结
RayPPOTrainer 的资源配置链路可以概括为:
配置文件 → ResourcePoolManager → RayResourcePool → RayWorkerGroup → Ray actor/GPU
- 配置阶段:用户用 list 形式指定“节点-级 GPU 需求”。
- 启动阶段:ResourcePoolManager 负责校验并创建 RayResourcePool;RayWorkerGroup 负责把 pool 映射成真正的 Ray actor。
- 运行阶段:不同角色(Actor、Critic、RewardModel…)通过各自的 worker group 访问独占或共享的 GPU 资源,实现灵活、可扩展的分布式 PPO 训练。
init_workers()方法的分析
在 RayPPOTrainer.init_workers() 中,“真正拉起 Ray actor” 的全过程可以拆成 5 个连续动作,每一步都对应一段可对照源码的代码块:
-
把“角色 → 资源池 → Worker 类”整理成一张三层映射表
1
2
3
4
5self.resource_pool_to_cls = {pool: {} for pool in ...}
# 以 ActorRollout 为例
pool = self.resource_pool_manager.get_resource_pool(Role.ActorRollout)
self.resource_pool_to_cls[pool]["actor_rollout"] = RayClassWithInitArgs(...)这一步只是 Python 层面的字典填充,没有任何 Ray 进程被创建。
-
为每个资源池生成“共址 Worker 类”
worker_dict_cls = create_colocated_worker_cls(class_dict=class_dict)
create_colocated_worker_cls会把同一个资源池里的多个角色(如 actor + rollout)打包成一个 Ray actor class,后续一个 Ray 进程里就能同时承载多个角色,减少跨进程通信。 -
创建
RayWorkerGroup对象
wg_dict = self.ray_worker_group_cls( resource_pool=resource_pool, # 关键:这里把 RayResourcePool 传进去 ray_cls_with_init=worker_dict_cls, **wg_kwargs )
这一步仍然只是 Python 对象级别的实例化;Ray 集群里还没有 actor。 -
真正在 Ray 集群上“spawn” actor
spawn_wg = wg_dict.spawn(prefix_set=class_dict.keys())
RayWorkerGroup.spawn()会遍历resource_pool中指定的所有 GPU/节点组合,为每一块(或每一组)GPU 调用ray.remote(...).options(num_gpus=..., resources=...).remote(...)。- 此时 Ray 的 GCS 开始调度,物理进程在对应机器上被拉起,每个进程内运行第 2 步生成的“共址 Worker 类”实例。
- 返回值
spawn_wg是一个字典,键是角色名(如"actor_rollout"),值是对应的RayWorkerGroup句柄,后续训练代码通过它来做 RPC 调用。 - 初始化模型权重
self.actor_rollout_wg = all_wg[“actor_rollout”] self.actor_rollout_wg.init_model()
每个 actor 进程收到 init_model() 后,才真正加载 HuggingFace/Megatron/FSDP 权重,完成 NCCL 初始化、FSDP/Megatron 并行拓扑建立等。
至此,所有 Ray actor 已根据资源池规格分布在集群各节点上,并完成了模型加载,后续训练循环即可通过 self.actor_rollout_wg.generate_sequences() 等接口进行分布式计算。
三层映射表
“角色”决定“该干什么”,“资源池”决定“在哪干”,“Worker 类”决定“怎么干”。
三者通过一张三层映射表把“任务、位置、实现”串在一起。
- 角色(Role)
枚举值:ActorRollout / Critic / RefPolicy / RewardModel …
职责:告诉系统“我需要什么功能”。
例:Role.Critic → “我要算 value”。 - 资源池(RayResourcePool)
内容:由ResourcePoolManager根据resource_pool_spec创建,内部保存
- 节点列表
- 每节点 GPU 数
- 总 GPU 数
职责:告诉 Ray“这些 GPU 专供某类任务使用”。
例:名为"critic"的资源池 = 2 节点 × 4 GPU/节点。 - Worker 类(WorkerType)
内容:真正的 Python 类,如 FSDPActorRolloutWorker、MegatronCriticWorker。
职责:实现前向、loss、更新等具体算法逻辑。
三层映射表长什么样(代码级)
1 | # 第一层:Role → 资源池名 |
运行时如何串联
- 训练代码通过 Role 拿到资源池:
pool = resource_pool_manager.get_resource_pool(Role.Critic) - 通过资源池拿到 Worker 类:
worker_cls = resource_pool_to_cls[pool]["critic"] RayWorkerGroup.spawn()用worker_cls在pool指定的 GPU 上启动 Ray actor。
因此:
- 换角色 → 换功能;
- 换资源池 → 换 GPU 拓扑;
- 换 Worker 类 → 换实现(FSDP ↔ Megatron ↔ vLLM)。
三者解耦,可任意组合。
训练流程
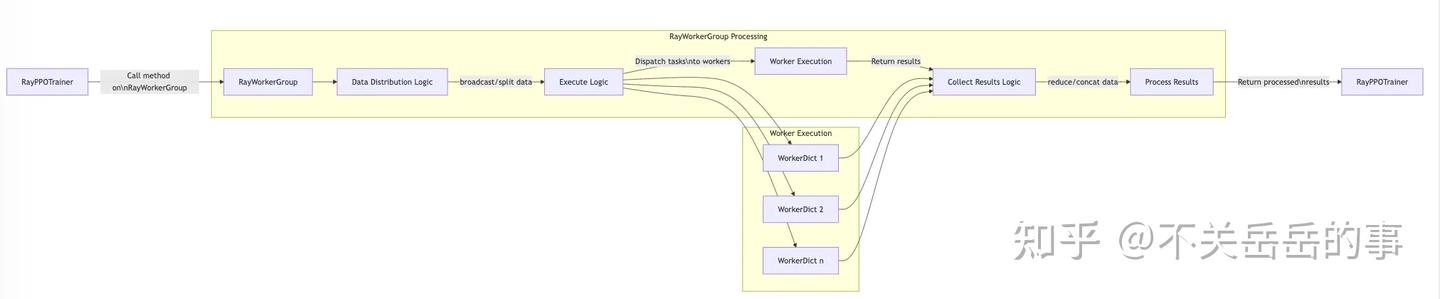
VeRL训练的具体数据传输&执行流程:
- RayPPOTrainer 向 RayWorkerGroup 发起方法调用;
- 在 RayWorkerGroup 内部:
- 首先执行数据分发逻辑(dispatch protocol)
- 然后执行逻辑判断哪些 worker 需要运行任务(可能是所有 WorkerDicts 或仅 rank0)
- 带有数据的任务被分发给指定的 WorkerDicts(先是定义角色的ModelWorkerDict,然后是定义计算的ParallelWorkerDict)
- 任务执行:
- 每个 WorkerDict 通过 Ray 远程执行接收其任务
- 完成任务后,结果返回给 RayWorkerGroup
- 结果处理:
- 结果通过收集逻辑进行处理(collect protocol)
- 最终,处理后的结果返回给 RayPPOTrainer
一级目录结构:
protocal
为了支持RL过程中更好的数据管理和传输,verl设计了DataProto这一数据结构,主要包括:
- 基于TensorDict所实现的batch,用于管理a dictionary of tensors;
- 基于Dict所实现的meta_info,用于管理当前DataProto的信息;
- 其余non-tensor数据,存在non_tensor_batch中;
- 以及DataProto使用所需要的各类数据管理逻辑,如pop、chunk、union、concat、rename、reorder等等;
DataProtoFuture则是为了支持DataProto的异步处理而构造的,支持负责reduce的collect_fn和负责scatter的dispatch_fn,从而方便worker的非阻塞执行;
models
主要包含常见模型结构(主要是llama结构和qwen2结构,允许用户集成更多的结构)的定义,包括:
- Transformers版本的模型结构定义:
- FSDP版本的RL训练推理、Rollout引擎、导出模型权重需要使用;
- 自定义新的模型结构:Add models with the FSDP backend
- Megatron版本的模型结构定义:
- Megatron版本的RL训练推理需要使用;
- Megatron版本需针对4D Parallelism做较多的适配;
- 自定义新的模型结构:Add models with the Megatron-LM backend
single_controller
实现verl的核心混合编程模型的重点,即基于single controller机制去管理RL的控制流;
- Worker:方便管理worker进程在workergroup进程组内部的信息(如rank_id和world_size),以及资源分配的信息;
- ResourcePool:管理某个资源池,包括池内节点信息和进程信息;
- Workergroup:管理多个worker所组成的workergroup,如负责管理data parallelism。最重要的函数是**_bind_worker_method:**
- 将用户定义的方法bind到WorkerGroup实例上;
- 处理被@register装饰器修饰的方法;
- 配置数据分发/收集模式和执行模式;
- 同步执行当前group内所有worker的该方法,并且根据分发&执行模式正确管理执行逻辑和数据传输逻辑;
- Decorator:主要定义了各种worker的数据分发和函数执行模式的装饰器,装饰后,workergroup在执行worker的方法时,将会通过装饰器自动配置数据分发和执行的模式;
- Ray:该处代码主要是基于ray后端,去管理worker(WorkerDict)和workergroup(RayWorkerGroup)。通过Python语法糖,实现了worker的method rebind,以让同一个workergroup在不同的rl角色之间灵活切换;
thrid_party(主要针对vllm)
目前主要是对开源的推理引擎vLLM,做了一些针对verl进行的定制化适配和封装(如SPMD);
之前支持4个版本:031,042,054,063,最近应该刚刚支持了07版本(Upgrading to vllm >= 0.7);
主要是继承了原始的vllm,以支持verl所需要的一些功能,比如取出特定计算结果、更好地支持hybrid engine(如sync/offload params,device mesh管理,weight loader的兼容…)等;
sglang的接入也在wip;
trainer(训练的核心逻辑)
- 支持sft: fsdp_sft_trainer.py
- 基于FSDP(dpsd zero3),一个torch-native的FSDP标准Trainer实现。
- 基于ulysess实现了sft训练时对超长序列的序列并行支持
- device mesh:管理各种并行的设备间通信
- PPO/GRPO/Reinforce++/RLOO等RL算法
- main_ppo.py
- 选择奖励函数(utils目录下,也可以自定义)
- 选择训练后端(FSDP/Megatron,Megatron对模型规模比较大的场景有性能优势)
- 调用RayPPOTrainer进行具体的训练流程:调用trainer的init_workers函数,初始化rl各个角色的的workergroup,然后调用fit函数执行实际的训练逻辑。
- RayPPOTrainer.py:
- 初始化RL中各个Role(Actor,Critic,RM,Ref):预先定义好各个模型的角色,设计resource_pool的定义和分配、workerdict和workergroup的初始化和分配
- workergroup支持没类colocate model group的具体实现:
- actor_rollout_wg: actor和generator互相切换的hybird engine
- critic_wg: 支持critic角色,仅ppo需要
- ref_policy_wg(可选):支持reference角色,开启kl需要
- rm_wg(可选):支持RM角色,model based reward需要
- 由init_workers方法初始化资源池和各个worker group
- ResourcePoolManager:资源池管理,封装ray的placement_group,将指定role合理分配到设备上
- 实现了一些PPO算法计算loss所需要的函数:
- apply_kl_penalty:计算PPO的token-level kl reward
- KL loss:在core_algos.py中实现的
- compute_advantage:计算优势函数的逻辑,核心算法是在core_algos.py中实现的
- 支持多种rl算法的advantage的计算,这套逻辑也在core_algos.py内部
- 一些timer,metics计算的函数(compute_data_metrics、compute_timing_metrics),save/load和断点续传以及ckpt保存的逻辑以及validate的逻辑等
- fit方法实现了rl的完整的training group,调用了各个worker进行实际的计算。fit是单进程运行的,如果是在ray cluster上运行,尽可能不要把trainer调度到head节点上
- main_generation.py和main_eval.py的逻辑,适用于离线生成和评估
- core_algo.py
- 各种loss的计算逻辑
- 各种advantage的计算逻辑
- main_ppo.py
utils
在utils文件夹下定义了一些重要的工具和组件,包括:
- Dataset:
- 主要包括:rl、sft和rm的dataset;
- 处理数据集中的各个key,包括取出了制作好的parquet里面的prompt列,apply_chat_ml + tokenize后设为input_ids;
- VeRL的dataset和dataloader没有和训练过程强绑定,可以在训练过程中比较轻松地做到dataloader的重载或者修改,所以实现一些功能会比较方便,如动态的课程学习等;
- Debug:
- 主要包括**:**监控Performance(如GPU usage)和Trajectory(即保存rollout结果)的逻辑;
- Logger:
- 顾名思义,主要是将一些监控指标输出到指定的位置(console或者wandb)的逻辑;
- Megatron:
- 主要是为了在verl中使用megatron所编写的一些utils,以及对原有megatron实现适配verl所进行的一些patch;
- Reward_score:
- 这里主要存着适配不同的rule-grader所编写的逻辑,包括各种parse answer的逻辑和compare answer的逻辑;
- 其他:如checkpoint管理的工具、hdfs文件管理的工具、支持ulysess/seq_balancing等feature的工具等;
version
worker
-
该文件夹下定义了RL中各个角色的worker(high-level,主要负责描述逻辑)以及各个角色计算时实际依赖的worker(low-leval,主要负责描述计算)
-
worker被workerdict封装后,每个gpu会运行一个。一个colocate的role依托于workergroup管理,每个workergroup下管理者一组远程运行的workers。workergroup就是single controller和workers之间的中介。
将worker的方法绑定到workergroup的方法上,通过装饰器实现具体的方法执行/数据分发逻辑。

-
fsdp_workers.py:基于FSDP训练后端,定义了一系列RL训练过程中可能使用的Worker。这些workers是基于实际负责运算的worker(后面会介绍)所进行的进一步封装;
- ActorRolloutRefWorker:
- 可以选择扮演单独的RL中的Actor(Policy Model)、Rollout(负责generate response)、Reference(负责提供ref_log_prob计算KL);
- 可以选择基于hybrid engine,同时扮演多个角色,然后verl通过参数的offload/reload/reshard进行灵活的切换;
- 目前支持了Data Parallelism(fsdp)和Sequence Parallelism(context维度,基于ulysess实现);
- 关键方法:
- init_model:根据config指定的model类型,来初始化当前worker:
- update_actor:
- 基于DataParallelPPOActor的update_policy,计算policy-Loss并更新Policy模型的权重;
- 基于ulysses_sharding_manager支持sequence parallel的数据前处理和后处理,从而实现序列并行;
- generate_sequences:
- 基于vllm封装的rollout引擎,推理生成数据,使用rollout_sharding_manager管理数据的形状,match rollout引擎的切分;
- compute_log_prob:基于actor的训练引擎,同步计算old_logprobs,方便进行importance sampling;
- compute_ref_log_prob: 基于训练引擎,计算ref_logprobs,方便计算kl constraint;
- save_checkpoint/load_checkpoint:实现模型参数的offload/reload,以及保存到外部硬盘;
- _build_model_optimizer:
- 指定optim_config一般是actor,需要基于FSDP进行训练,需要初始化fsdp wrap的模型(进一步传给DataParallelPPOActor封装)、optimizer和lr_scheduler;
- 不指定optim_config一般是ref,统一推理引擎和训练引擎,确保KL计算的数值准确性;
- 所有的涉及运算的函数,都有dispatch_mode装饰器,以实现workergroup内部的数据传输逻辑(single-controller的设计模式);
- CriticWorker:
- 和ActorRolloutRefWorker逻辑大体一致,只不过基于的后端是DataparallelPPOCritic
- 不需要rollout,且额外多出compute_values这个操作,通过value head计算token-level value以便PPO计算Adv
- RewardModelWorker:
- 基于模型的RM打分实现
- ActorRolloutRefWorker:
-
megatron_workers.py:基于megatron后端实现的RL Workers
- 基于megatron支持4D并行,DP, TP, SP, PP
- 核心逻辑基本和FSDP版本一致,但是底层逻辑需要适配megatron框架
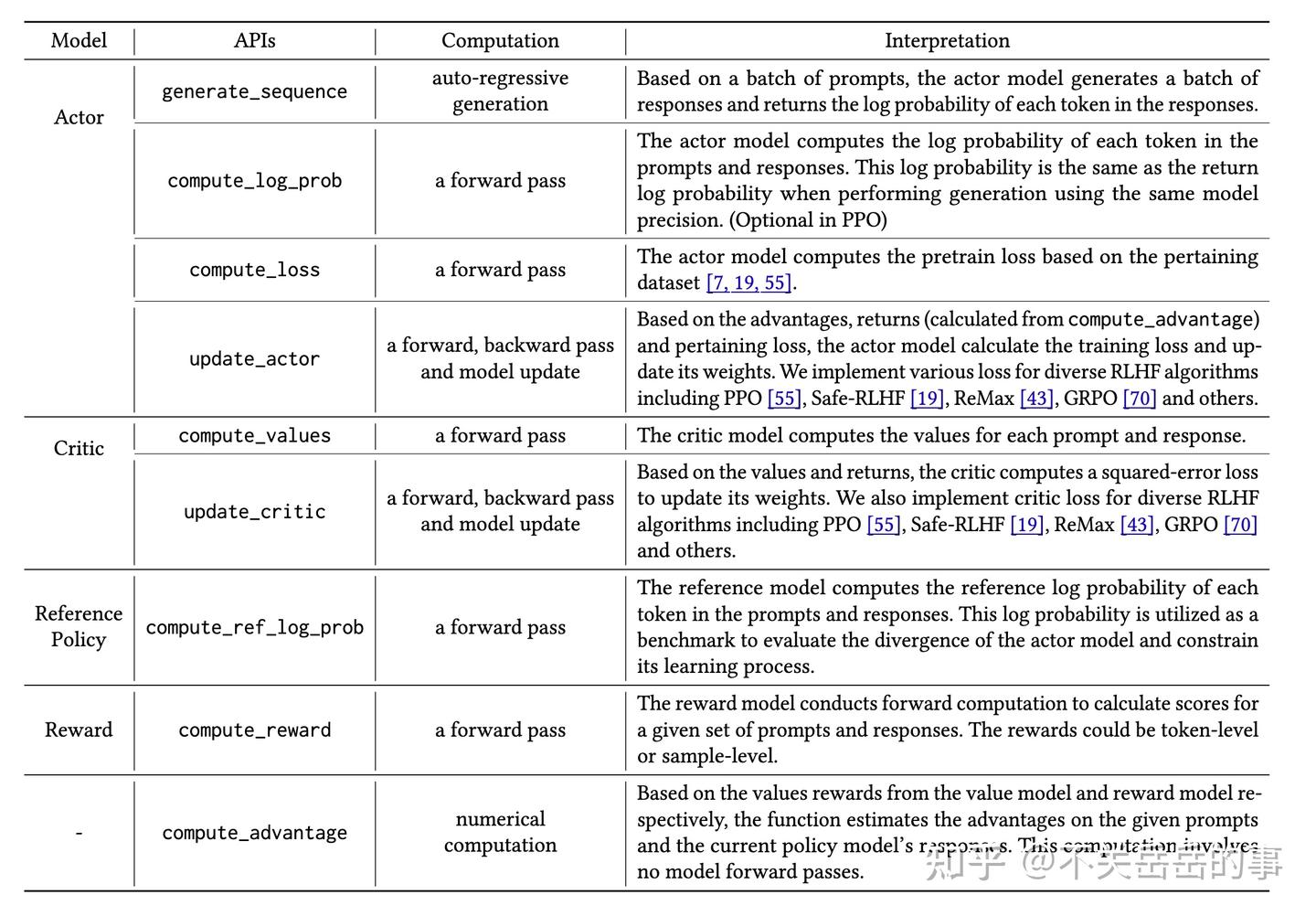
具体的Actor运算Worker,他们被放置在worker目录的子文件夹下,默认都有fsdp(torch-native)和megatron两个版本的写法,以兼容两套训练引擎。
- Actor:
- RL中(PPO)扮演Actor角色的worker(reference model可以调用)
- 核心功能:
- compute_log_prob:计算KL或者Importance Sampling,前向传播推理得到各token位置的logits和对数概率
- update_policy: 基于预先计算好的advantage,计算policy loss、entropy loss和kl loss,更新policy model
- Critic:
- Actor-Critic-Based RL算法(如PPO)中扮演Critic角色的worker
- 核心功能:
- compute_values:计算values,参与计算PPO算法的advantage
- update_critic: 计算value loss,然后更新value model
- Reward_model:
1.
2. 基于Model-based的打分模型,计算response-level reward;
3. 核心功能主要就是compute_reward;
4. rule-based reward不需要; - Rollout:
- 核心功能就是在训练时候rollout response,主要函数为generate_sequences;
- 支持不同的生成引擎后端:
- 原生的rollout逻辑,最简单的从logits->softmax->sampling的逻辑;
- huggingface TGI后端的rollout逻辑;
- vllm的rollout逻辑;
- 目前开源版本的推理引擎以vllm为主,但sglang也在接入中;
- 基于third_party中修改的vllm engine进行推理;
- repreat采样没有使用n_samples参数而是直接repeat_interleave输入,多次生成;
- old_log_probs没有使用vllm引擎得到的结果,为了确保importance sampling和kl divergence计算的准确性,要用训练引擎(FSDP或者Megatron)统一计算,避免引擎不同带来的误差;
此外,该文件夹下还有sharding_manager,主要是负责管理不同的parallelism下的sharding,包括:
- data sharding(preprocess_data,postprocess_data);
- device mesh的管理;
- 模型参数的reload & offload逻辑(基于上下文管理器);