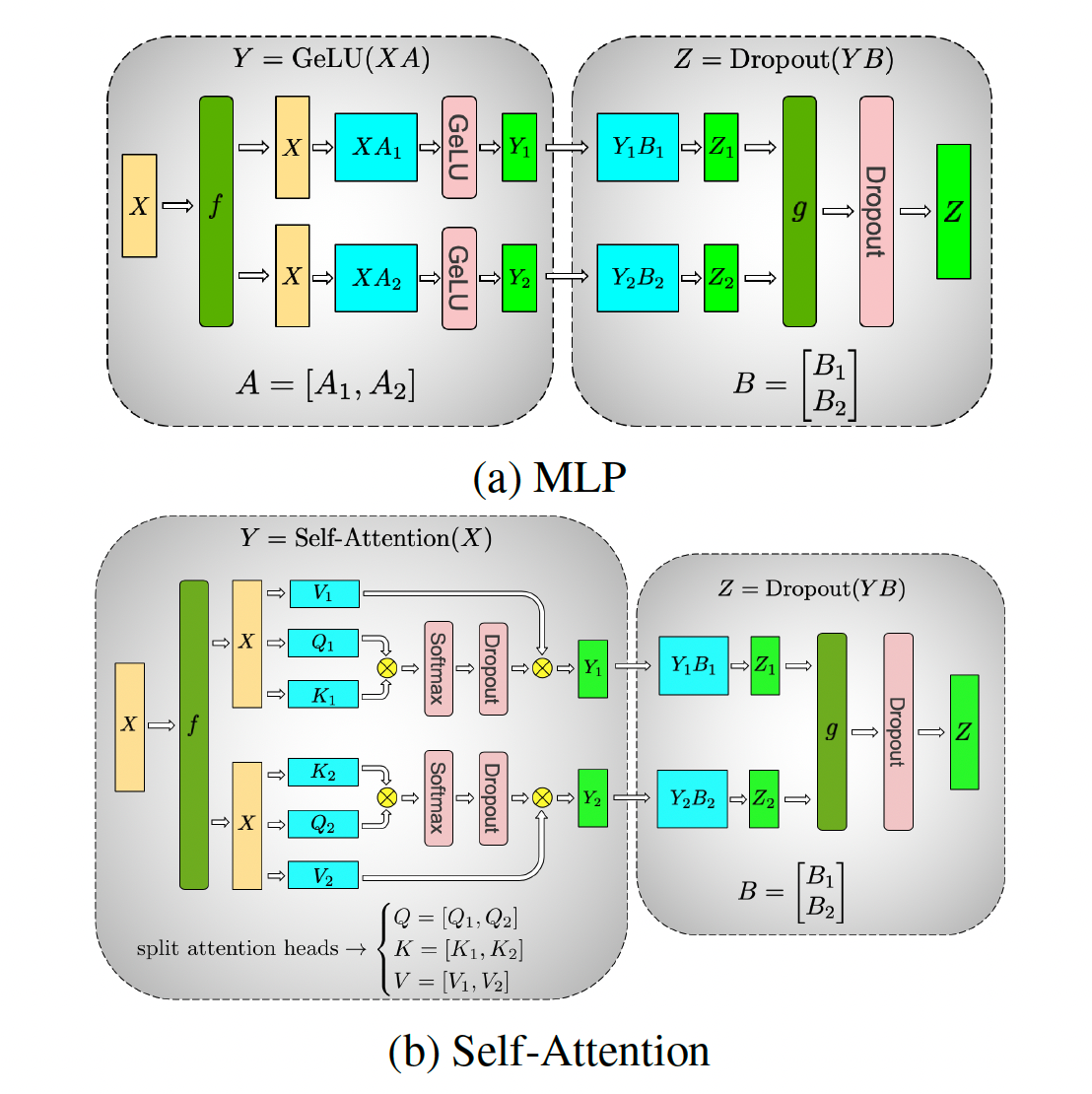
深入理解Megatron-LM
深入理解Megatron-LM
基础知识:https://zhuanlan.zhihu.com/p/650234985
原理介绍:https://zhuanlan.zhihu.com/p/650383289
megatron中的pipeline并行https://zhuanlan.zhihu.com/p/432969288
代码结构:https://zhuanlan.zhihu.com/p/650237820
并行设置:https://zhuanlan.zhihu.com/p/650500590
张量并行:https://zhuanlan.zhihu.com/p/650237833
流水线刷新机制:https://zhuanlan.zhihu.com/p/651341660
1F1B流水线并行负载不均衡:https://zhuanlan.zhihu.com/p/693425934
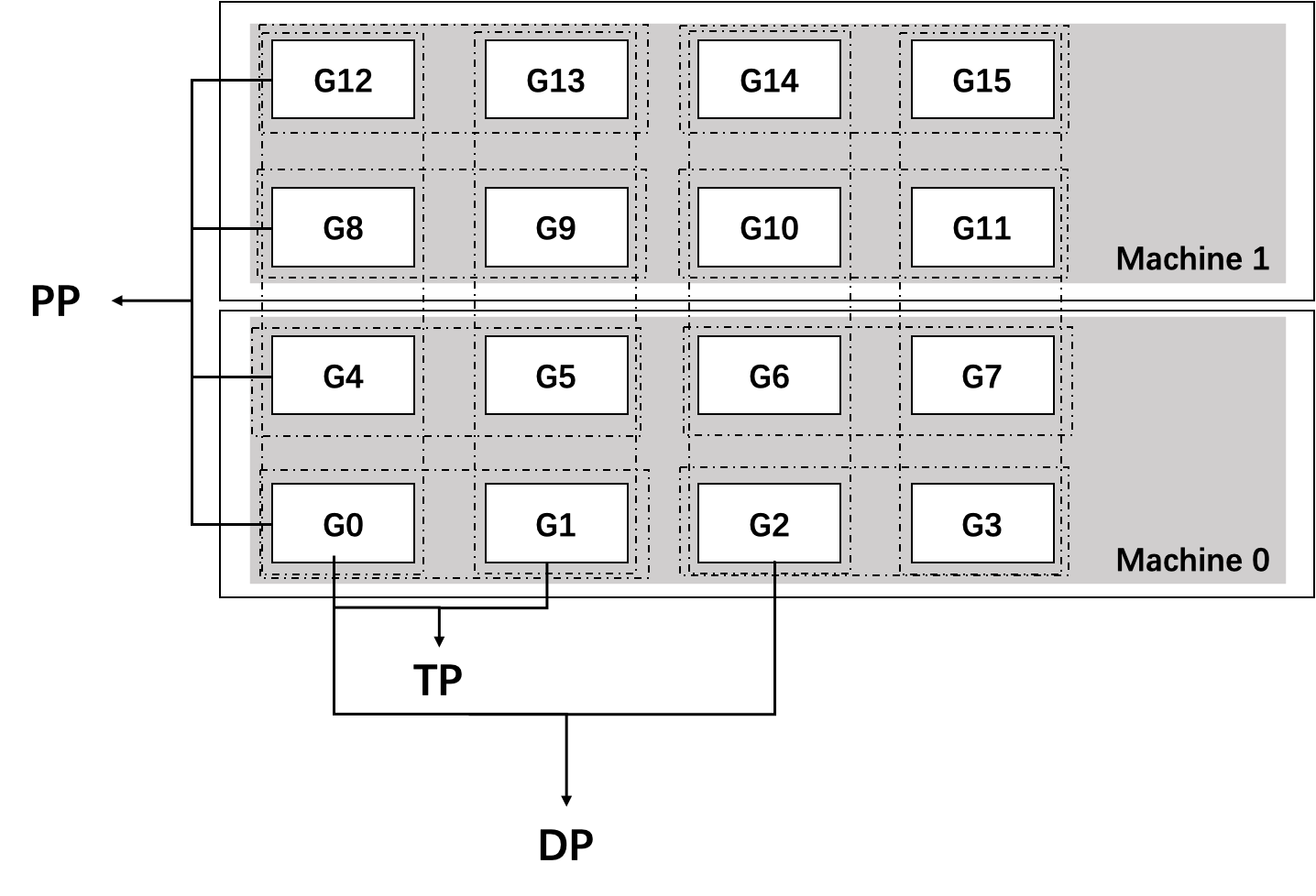
进程模型:
当你使用 torch.distributed.launch 或 torchrun 启动训练时,会启动 N 个独立的 Python 进程(N = GPU 数量),每个进程绑定到一个 GPU,并分配一个唯一的 rank(0 到 N-1)。所有进程执行相同的代码(training.py),但通过 get_tensor_model_parallel_group() 等函数获取不同的通信组,从而实现混合并行。
在分布式训练中,每个 rank 对应一个独立的进程(通常是一个 GPU 上的 Python 进程)。这些进程通过 NCCL 或 Gloo 等通信库进行通信。Megatron-LM 采用 数据并行 + 模型并行 的混合并行策略,其中模型并行又分为张量模型并行(Tensor Model Parallelism, TP)和流水线模型并行(Pipeline Model Parallelism, PP)。
Megatron 进程模型示例
假设我们使用 4 个 GPU(即 4 个进程,rank 0~3),并配置:
- 张量模型并行大小(TP) = 2
- 流水线模型并行大小(PP) = 2
- 数据并行大小(DP) = (总 GPU 数)/(TP × PP)= 4 / (2×2) = 1
则进程组划分如下:
-
张量模型并行组(Tensor Model Parallel Groups):
- 组 0:rank 0, rank 1(这两个 rank 共同持有模型的前半部分参数)
- 组 1:rank 2, rank 3(共同持有模型的后半部分参数)
- 在每个组内,rank 之间通过
get_tensor_model_parallel_group()获取自己的组,并进行 all‑reduce 等通信。
-
流水线模型并行组(Pipeline Model Parallel Groups):
- 组 0:rank 0, rank 2(rank 0 是流水线第一层,rank 2 是第二层)
- 组 1:rank 1, rank 3(rank 1 是第一层,rank 3 是第二层)
-
数据并行组(Data Parallel Groups):
- 因为 DP=1,所以每个 rank 自己就是一个数据并行组。
代码执行流程
每个 rank 上运行的代码是相同的(SPMD,单程序多数据),但通过 get_tensor_model_parallel_group() 等函数获取不同的通信组,从而表现出不同的行为。
举例:在 megatron/core/tensor_parallel/mappings.py 的 all_reduce 函数中:
1 | def all_reduce(input_): |
- rank 0 调用时,
group是包含 rank 0 和 rank 1 的进程组。 - rank 2 调用时,
group是包含 rank 2 和 rank 3 的进程组。
总结
- 每个 rank 是一个独立的进程,运行相同的代码副本。
- 在 Megatron 的混合并行中,每个 rank(即每个 GPU 上的进程)同时属于多个维度的通信组:
- 一个张量模型并行组(通过
get_tensor_model_parallel_group()获取) - 一个流水线模型并行组(通过
get_pipeline_model_parallel_group()获取) - 一个数据并行组(通过
get_data_parallel_group()获取) - 可能还有其他组(如上下文并行组、专家并行组等)
- 一个张量模型并行组(通过
get_tensor_model_parallel_group()的调用者是每个 rank 进程中的代码。- 函数返回与该 rank 绑定的张量模型并行组,用于在该组内进行集体通信。
- 这种设计使得 Megatron 能够灵活地组合多种并行维度,高效地训练超大模型。