从知识图谱到 GraphRAG:探索属性图的构建和复杂的数据检索实践
从知识图谱到 GraphRAG:探索属性图的构建和复杂的数据检索实践
- 比如query:感冒了吃什么?db:1、感冒了可能会发烧和头痛。2、对乙酰氨基酚是一种退烧和止疼药物。相似度搜索极难查询到第2个结果,而Graph方法可以将对1和2连接在一起,从而在检索到1结点的时候将相邻结点一起检索出来。
- 当你问:“这个数据集的主题是什么?”这类高级别、概括性的问题时,传统的RAG可能就会束手无策。为什么呢?那是因为这本质上是一个聚焦于查询的总结性任务(Query-Focused Summarization,QFS),而不是一个明确的检索任务。
通常来说,具备如下特征的数据和场景更适合使用GraphRAG。
- 第一类是有较多相互关联实体与复杂关系,且结构较明确的数据。比如:
- 人物关系网络数据:社交网络中的用户关系、历史人物关系、家族图谱等。
- 企业级关系数据:公司结构、供应链、客户等之间的关系。
- 医学类数据:疾病、症状、治疗、药物、传播、病例等之间复杂关系。
- 法律法规数据:法律条款之间的引用关系、解释、判例与适用法律条款的关系。
- 推荐系统数据:产品、用户、浏览内容、产品之间的关联、用户之间的关系等。
- 第二类是涉及复杂关系、语义推理和多步逻辑关联的查询,比如:
- 多跳关系查询:在华东区所有的门店中,哪个导购的消费者客单价最高?
- 知识推理查询:根据患者的症状和病史,推断可能的疾病并提供治疗方案。
- 聚合统计查询:在《三国演义》中,出场次数最多的人是谁?
- 时序关联查询:过去一年都有哪些AI大模型的投资与并购事件?
- 跨多文档查询:在《三体3》中,有哪些人物在《三体1》中出现?
本文将探索属性图及其在提升数据表示和检索中的作用,同时借鉴 Ravi Theja(LlamaIndex AI 工程师和布道师)关于属性图的系列内容。通过这篇文章,我们将对如何使用 LlamaIndex 实现 GraphRAG 有一个清晰的理解,并附上一份实践指南,助您入门。
- **作者介绍:**Divyanshu Dixit,Divisin.ai 联合创始人
- 原文链接:https://div.beehiiv.com/p/knowledge-graphs-graphrag-advanced-intelligent-data-retrieval
以下为译文:
01 进化:从知识图谱到属性图谱
首先,让我们回顾下知识图谱(KG)的概念。知识图谱使用主体、对象和谓语的三元组结构来定义关系,就像一个基础的家谱。它展示了人与人之间的关系,但没有个人的详细信息。
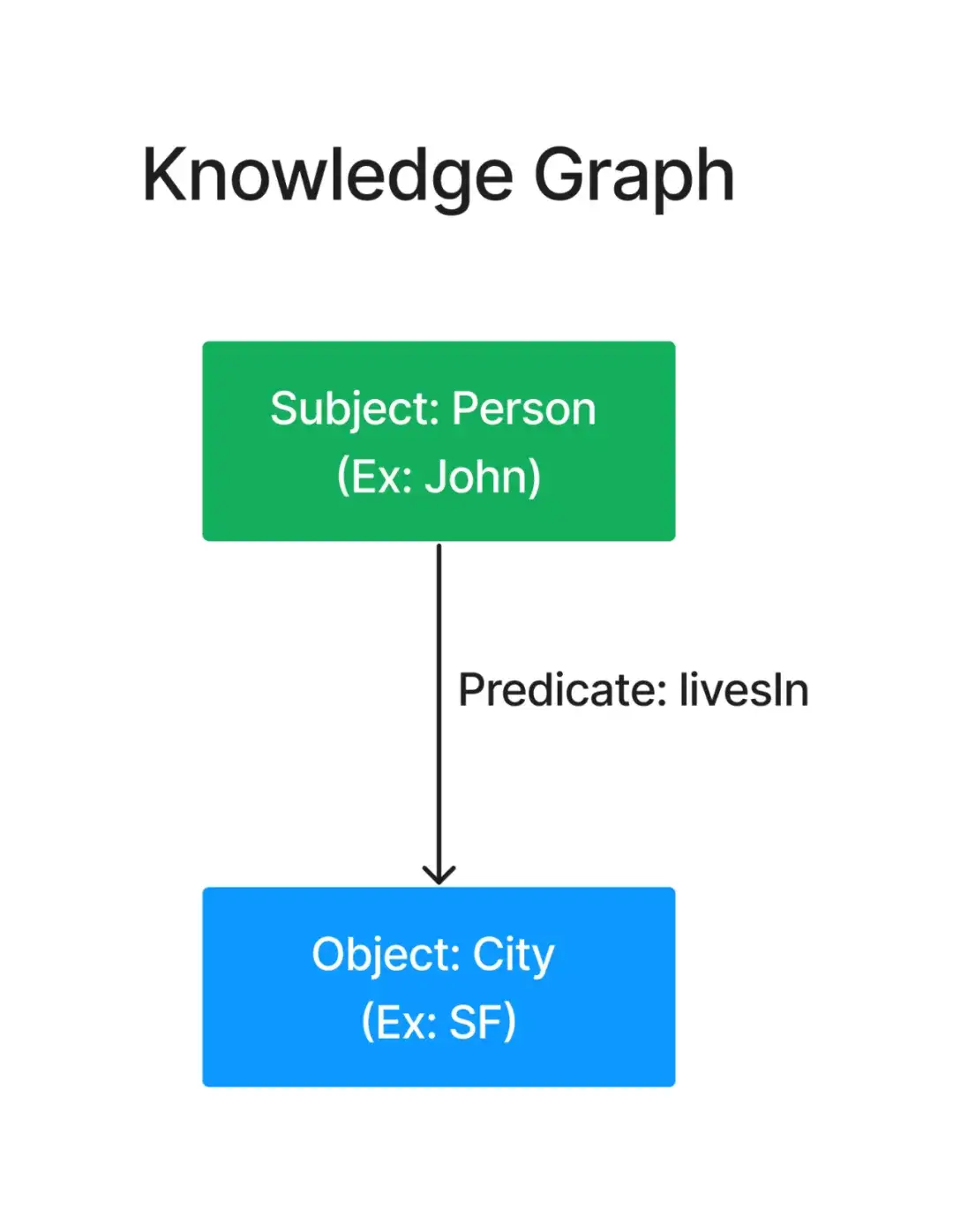
来源:LlamaIndex
每个节点(绿色和蓝色)有“标签”,承载了诸如类别的特定信息。它们就像家庭聚会的姓名标签,告诉你约翰是个人,旧金山是一个城市。谓语(边)定义了这些节点之间的关系(和方向)。
进入属性图(PG):PG 结构不仅包含主体、客体和谓语,还包含了每个实体附加的属性,比如名称/属性值对等。就像是从一个只包含姓名标签的基础家谱,升级为带有每个家庭成员的详细资料的详细版家谱。
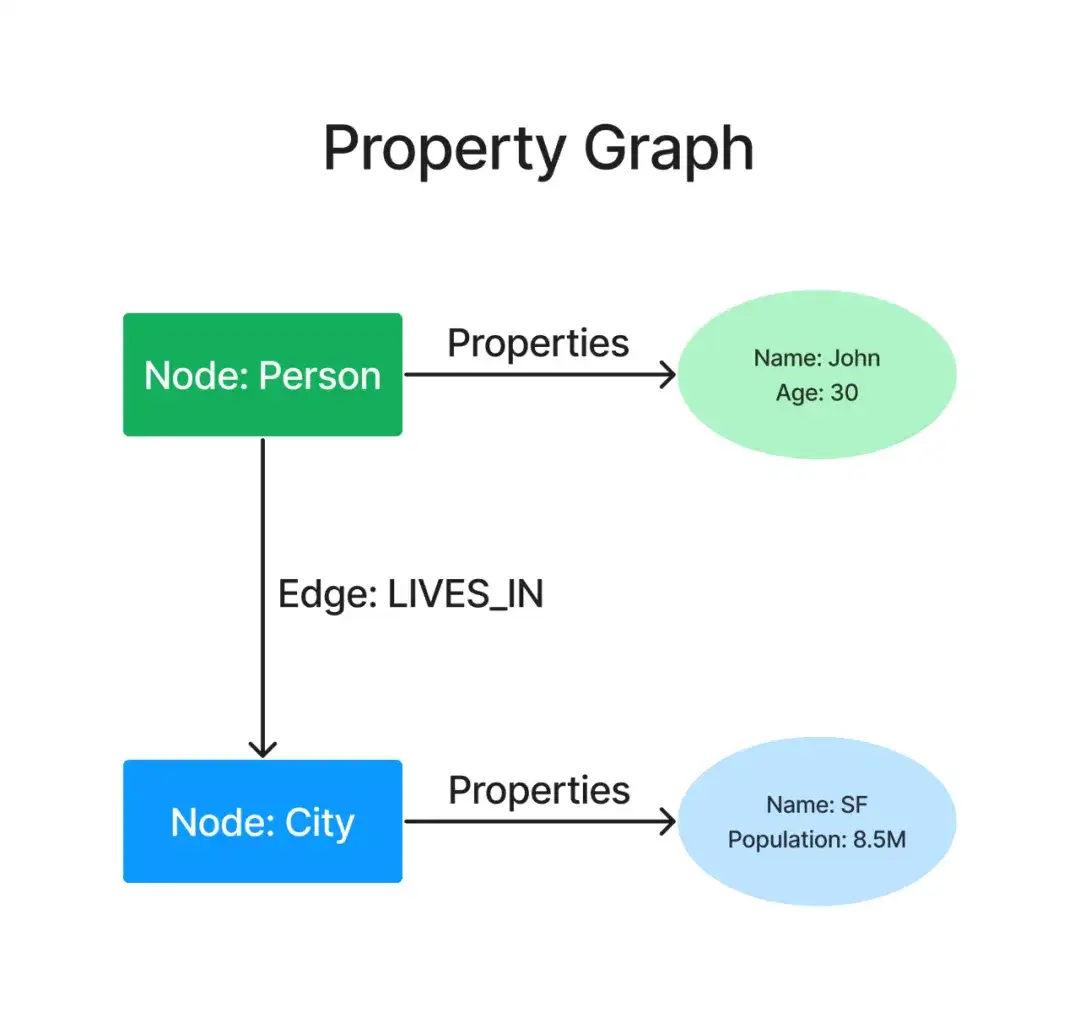
来源:LlamaIndex
在这个详细版家谱中,约翰不仅仅是一个人,还记录了他今年 30 岁的年龄信息。旧金山也不仅仅是一个城市,是一座人口有 850 万的城市。有趣的是,甚至是谓语也可以有自己的属性,让实体之间的联系都有了细节。比如,约翰与旧金山是什么关系?我们可以添加“约翰从 2006 年就住在旧金山”的信息。这就像是在家谱上添加便签,详细描述所有细节。
OpenSPG 是一个语义增强的可编程知识图谱,GitHub地址如下,欢迎大家Star关注~
https://github.com/OpenSPG/openspg
02 如何构建属性图谱
那么,如何将我们的基础家谱升级为这个信息翔实的网络呢?仅需要两步:PG 构建和查询。下面让我们逐步讲解:
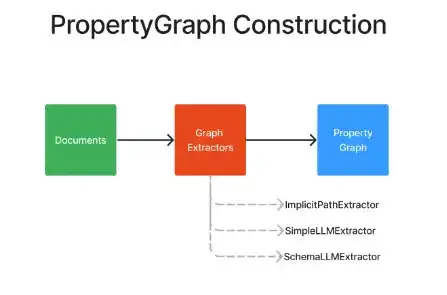
来源:LlamaIndex
2.1 第一步:图谱提取(构建阶段)
有三种方法:
1. ImplicitPathExtractor:
这就像整理书架,你不需要阅读每一本书,只是按顺序排列。在下面的图中,大文本 E 被分为小块的文本 A,B 和 C。这三个部分之间的关系定义为 A 在 B 之前,B 又在 C 之前,它们都属于源文本 E。所以,ImplicitPathExtractor 将原始文档分割成一个有序的块(节点)列表,以及它们之间的节点关系,作为词汇图。而且这个过程不需要 LLM 的参与。
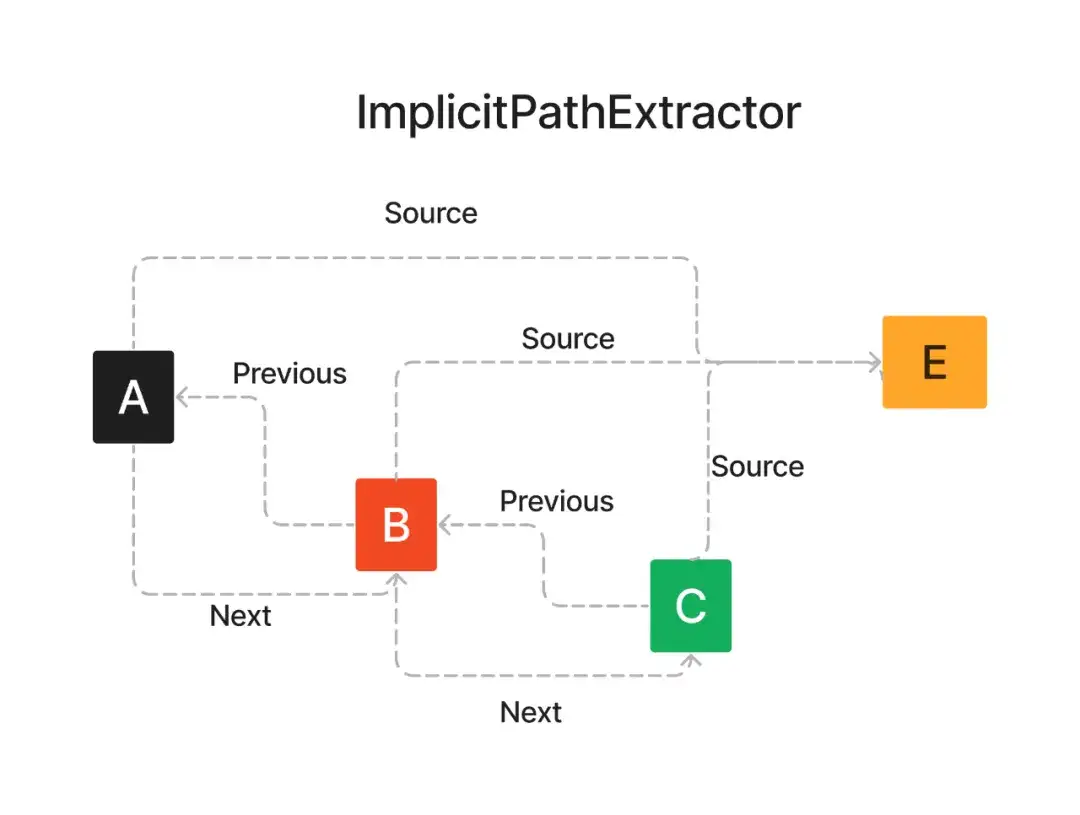
2. SimpleLLMExtractor:
使用一个 LLM 从文本片段中提取实体和关系,这就像是,你有一个非常聪明的朋友阅读一本书,然后告诉你书中所有的人物及其关系。在下面的例子中,我们使用 LLM 从文本片段中抽取出 4 个实体(太阳、猫、窗户和垫子),以及它们之间的关系。这里的 LLM 可以是像 Llama3 这样的开源版本,因为我们不需要调用原生函数。请注意,所有节点都使用相同的节点标签,每个文本片段都通过“提及”关系与其它实体相关联,这些实体之间还可以有进一步的关系。
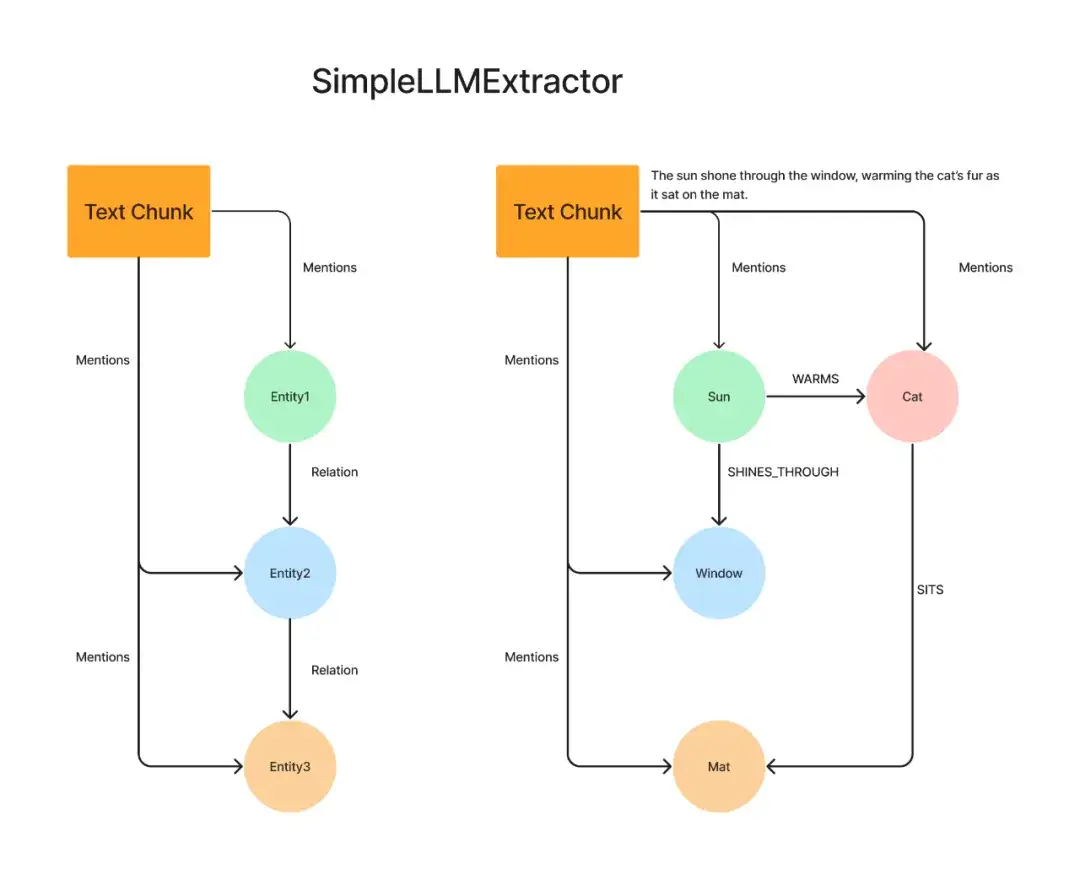
来源:LlamaIndex
3.SchemaLLMPathExtractor:
SchemaLLMPathExtractor 和 SimpleLLMExtractor 类似,但它使用预定义的 Schema,可以提前定义待提取的实体、节点标签和关系。这就像是给你的“聪明朋友”提供了一份在书中查找特定内容的问题清单,比如“告诉我这本书中的主角、反派和背景设定”等问题。还是以之前的文本片段为例,如果把问题限定在“垫子”这个实体及其关系中,属性图将被截断,如下所示。还有一点不同在于,SchemaLLMPathExtractor 最适合配合 LLM 使用,支持函数调用,且节点可以有不同的节点标签。
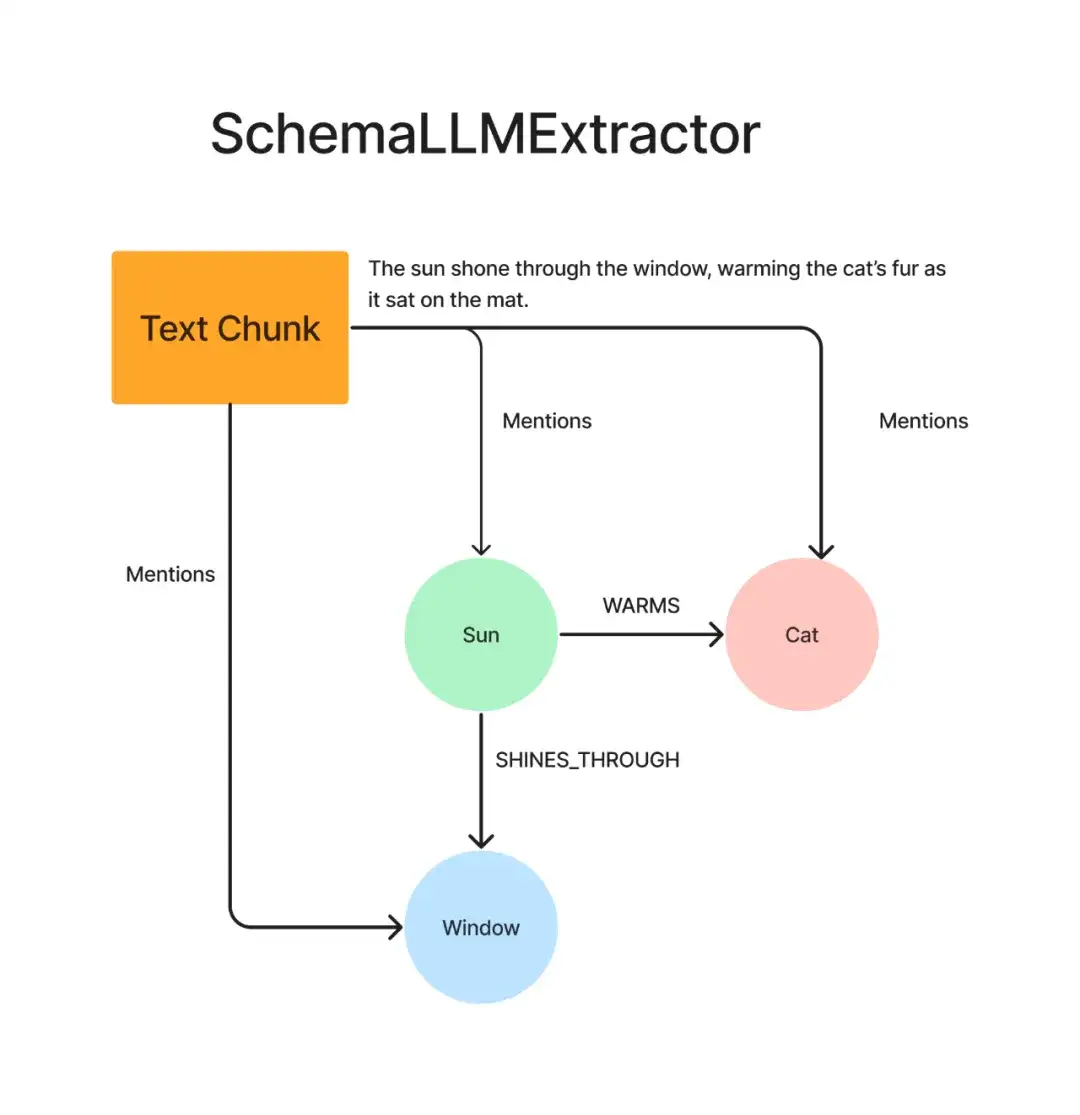
来源:LlamaIndex
2.2 幕后英雄:实体消歧
创建属性图后,下一个步骤应该是检索,其实中间还有一个经常被忽视的重要步骤,就是“实体消歧”。这一步骤类似于 ETL (Extract-Transform-Load) 流程中的数据清洗,通过文本嵌入相似度和词汇距离来移除潜在的重复项。再拿家谱的例子来说,这个步骤可以确保你不会混淆家谱中两个同名的人。比如,约翰叔叔和堂兄弟约翰是同一个人吗?这个步骤有助于澄清这一点。

来源:Neo4j
2.3 第二步:图检索器(查询阶段)
现在我们已经建好了这个详细的家谱,如何在里面查找信息呢?我们有四种工具:
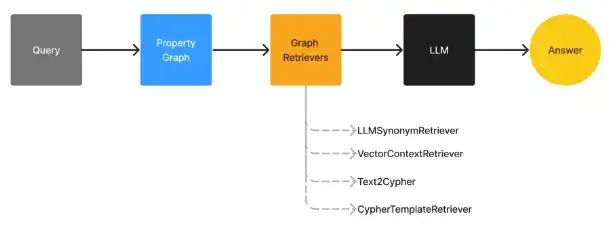
来源:LlamaIndex
1.LLMSynonymRetriever:
顾名思义,它根据用户的查询生成同义词和关键词,以找到最近的节点及其邻居。唯一的缺点是,它使用关键词搜索,不太可靠。这就像是向你的姨妈询问家族历史,她可能会跑题,但你也会得到一些有趣的相关信息。
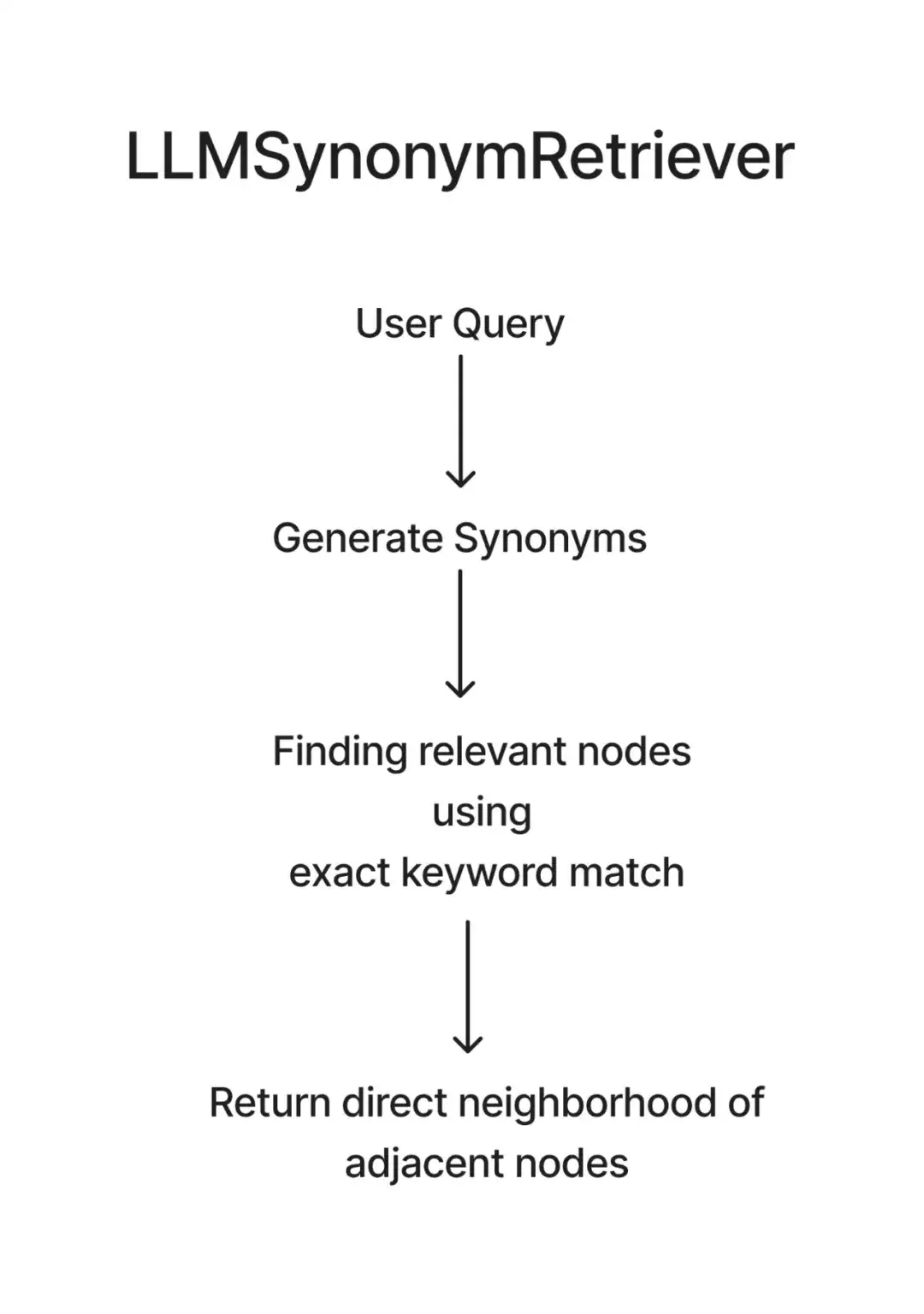
2.VectorContextRetriever:
这个检索器使用嵌入和余弦相似性,进行向量相似性搜索,以检索相关的节点。它可以直接用于图数据库,或者是图和向量数据库的组合。值得注意的是,它不适合需要聚合响应的全局查询,更像是用于你的家谱的搜索引擎。适合特定问题,但不适用于“告诉我关于家族的历史”的查询。
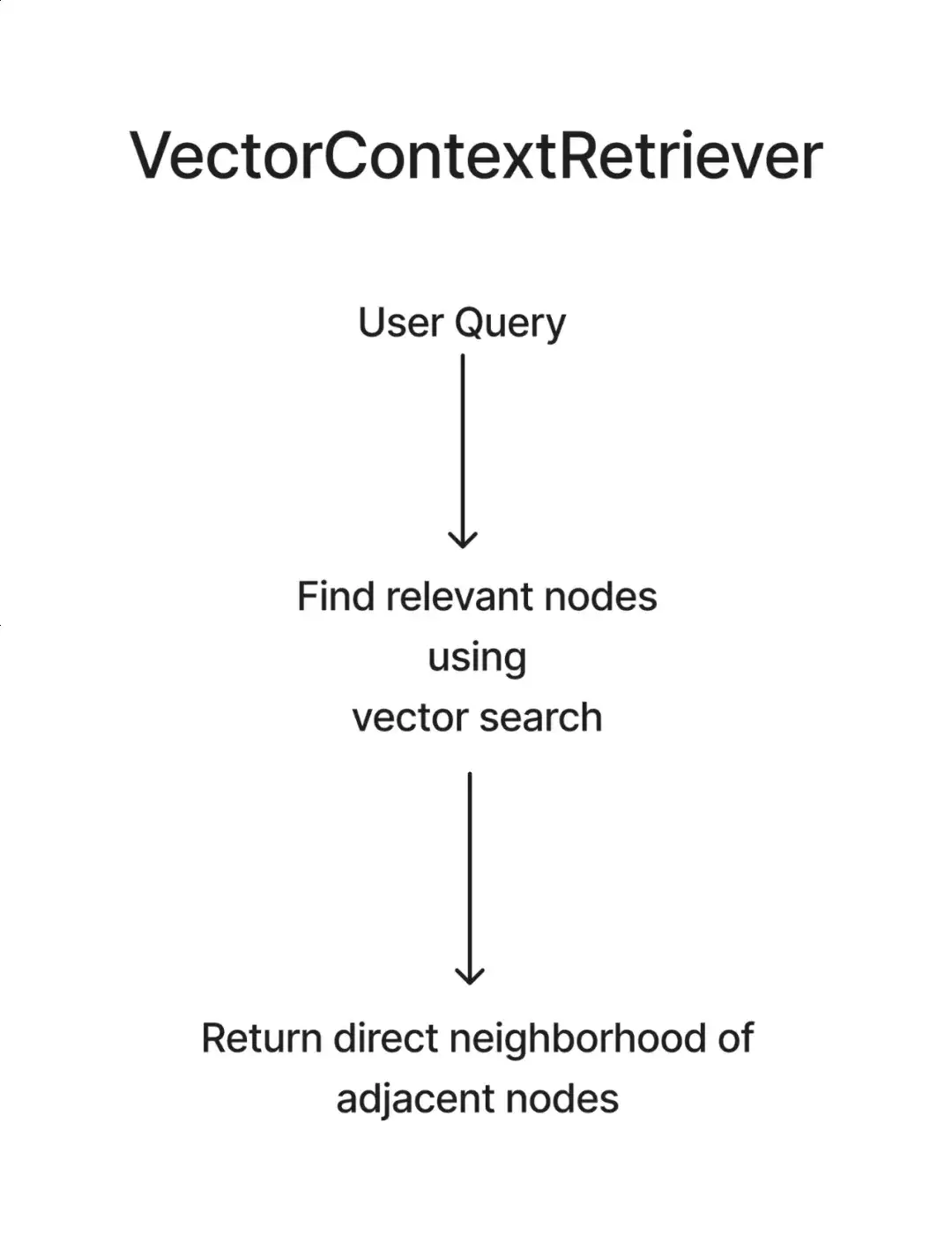
来源:LlamaIndex
3.Text2Cypher:
这里使用 LLM 根据用户查询生成 Cypher 语句,然后从图数据库中获取数据。Text2Cypher 适用于需要聚合的全局查询。这就像是有一个翻译,他可以把你的问题转化为你的家谱能理解的语言。当然 LLM 生成的 Cypher 语句并不总是准确,但我们正在以准确度换取灵活性,所以在这里建议使用微调的本地模型。
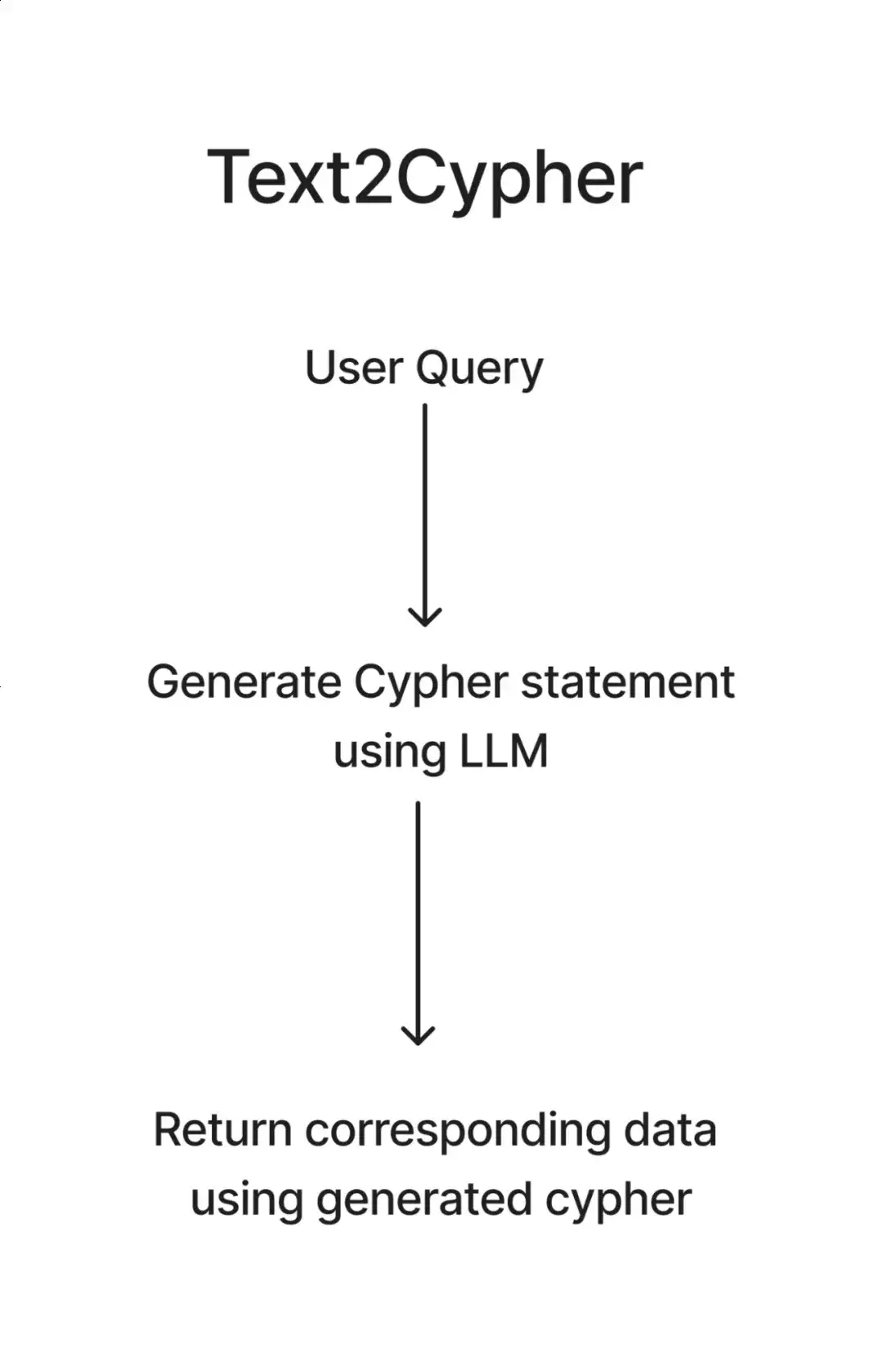
来源:LlamaIndex
4.CypherTemplateRetriever:
在此,我们可以使用带有特定参数的 Cypher 模板。对于用户查询,我们会使用 LLM 来填充这些参数,以创建用于检索的 Cypher 查询。这在很大程度上解决了 LLM 生成错误 Cypher 语句的问题,就像预先写好问题的框架,你只需要填空就好了,降低了提出家谱无法理解的问题的可能性。
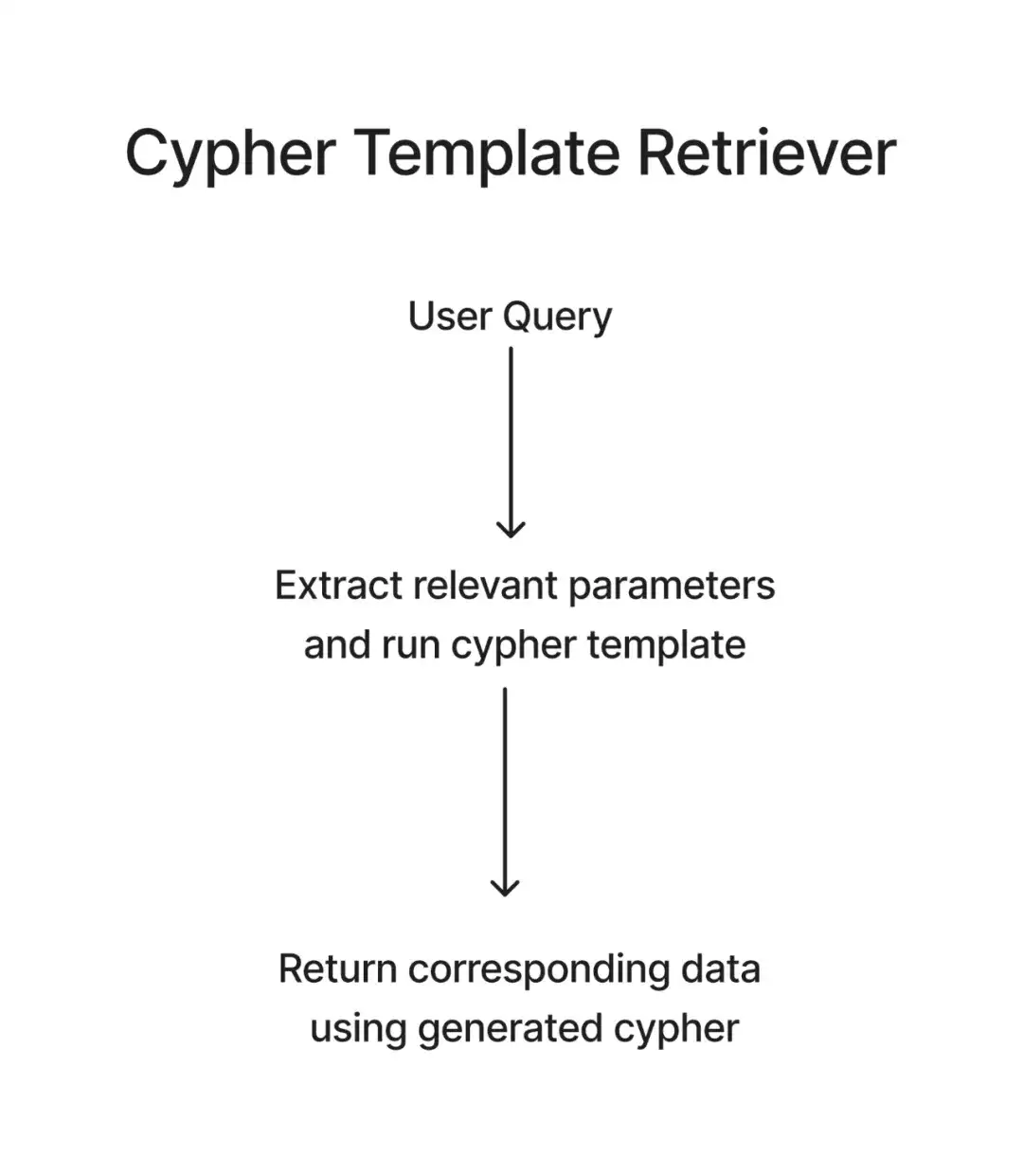
来源:LlamaIndex
03 整合:GraphRAG 开始工作
实际上,GraphRAG 就好比把你家详细的家谱,交给一个超级智能的家族历史学家。传统的 RAG(检索增强生成)系统经常在回答宽泛主题的问题上遇到困难。这是因为这类问题需要对整个数据集有全面的理解,而不仅仅是检索特定信息。
所以,GraphRAG 在以下场景中表现出色:
- 在大型数据集中识别核心主题
- 理解不同主题之间的关联
- 全面了解复杂的信息架构
感谢 Ravi Theja,我们现在有了使用 LlamaIndex 实现 GraphRAG 的教程。
教程链接:https://github.com/run-llama/llama_index/blob/main/docs/docs/examples/cookbooks/GraphRAG_v1.ipynb
从知识图谱到属性图谱,再到 GraphRAG 的发展,标志着我们对数据的理解和交互方式发生了重大转变。GraphRAG 在揭示隐藏模式和回答开放性问题方面展现出潜力,但也只是我们工具箱中的众多工具之一,其真正的价值要通过实际应用和持续研究来确定。




