io uring学习
看这个就行
https://arthurchiao.art/blog/intro-to-io-uring-zh/
阻塞式I/O与非阻塞式I/O
1. 阻塞式 I/O 的问题
在最原始的模型中,应用程序调用 read() 或 write() 时,如果数据没有准备好(例如,网络包未到达,或磁盘数据未从硬盘读入内存),进程就会被挂起(阻塞),直到操作完成。这在高并发场景下是灾难性的,因为一个线程只能处理一个请求。
2. 非阻塞 I/O + I/O 多路复用 (select/poll/epoll) 的“伪异步”
为了解决阻塞问题,引入了非阻塞 I/O 和 I/O 多路复用机制。
- 工作方式:应用程序将文件描述符(fd)设置为非阻塞模式,然后使用
epoll等系统调用来“监听”一组 fd。当epoll_wait()返回时,它会告诉你哪些 fd 已经“就绪”(ready),即可以进行无阻塞的读写操作。 - 优点:一个线程可以同时管理成千上万个网络连接,极大地提升了并发能力。这也是 Node.js、Nginx、Redis 等高性能服务的基石。
3. 致命缺点:仅限于“就绪通知”,且不支持 Storage I/O
这正是您指出的核心问题:
- “就绪通知”而非“完成通知”:
epoll告诉你一个 socket “可读”,只是意味着内核的接收缓冲区里有数据了。当你去调用read()时,这个read()系统调用本身仍然需要从用户态陷入内核态,并且对于磁盘文件,它仍然可能因为要等待磁盘 I/O 而阻塞。 - 不支持 Storage Files:这是最关键的一点。
epoll的设计初衷是为网络和管道服务的。你无法用epoll来监听一个普通磁盘文件的读写是否“就绪”。对于磁盘 I/O,即使你设置了O_NONBLOCK标志,很多文件系统也会直接忽略它,read()调用依然会阻塞直到数据从磁盘读取完毕。
这就导致了一个非常割裂的局面:
- 对于网络编程,我们有
epoll这样的高性能工具。 - 对于磁盘 I/O,我们只能依赖阻塞调用,或者使用功能残缺、性能不佳的 POSIX AIO (
libaio),而后者通常又要求O_DIRECT(绕过系统缓存),这在很多场景下是不切实际的。
4. io_uring 的革命性突破
io_uring 彻底解决了上述所有问题:
- 真正的异步:它提供的是“完成通知”,而不是“就绪通知”。你提交一个
read请求后,可以去做其他事。当数据真正从磁盘读取完毕并拷贝到你的缓冲区后,内核会主动通知你。 - 统一接口:
io_uring同时支持 Network I/O 和 Storage I/O。你可以用同一套 API 来处理 TCP 连接和读写磁盘文件,极大地简化了编程模型。 - 零拷贝与零系统调用 (可选):通过共享内存环形队列,
io_uring将提交请求和获取结果的开销降到了最低。在某些模式下(如SQPOLL),甚至可以完全避免应用层的系统调用。
总结
io_uring 的出现,不是对 epoll 的简单优化,而是对整个 Linux I/O 模型的一次范式转移。它填补了 epoll 无法处理 Storage I/O 的巨大空白,为构建真正统一、高效的异步系统铺平了道路。
0_DIRECT
O_DIRECT 是 Linux 系统中一个用于文件 I/O 操作的文件打开标志(flag)。当你在调用 open() 系统调用打开一个文件时,可以传入这个标志,例如:
1 | int fd = open("myfile.dat", O_RDONLY | O_DIRECT); |
它的核心作用是:绕过操作系统的页缓存(Page Cache),让应用程序的数据直接在用户空间缓冲区和存储设备(如磁盘)之间传输。
一、 为什么要用 O_DIRECT?—— 解决“双重缓存”问题
在传统的文件 I/O 中,数据流是这样的:
- 应用程序 调用
read()。 - 数据从 磁盘 读取到 内核的页缓存(Page Cache)。
- 数据从 页缓存 拷贝到 应用程序的用户空间缓冲区。
对于像数据库(MySQL, PostgreSQL)、高性能键值存储(RocksDB)这类应用,它们自己实现了非常精密的缓存和预读策略。如果再让操作系统做一层缓存,就形成了“双重缓存”,这会带来两个严重问题:
- 内存浪费:同一份数据在应用层和内核层各存一份,浪费宝贵的内存资源。
- 性能不可控:应用无法精确控制数据何时写入磁盘,因为数据可能先停留在页缓存中。这对于需要严格保证数据一致性和持久性的数据库来说是灾难性的。
O_DIRECT 就是为了解决这个问题而生的。它让数据流变成:
- 应用程序 调用
read()(withO_DIRECT)。 - 数据直接从磁盘读取到用户空间缓冲区 (或反之)。
这样,应用程序就拥有了对 I/O 的完全控制权。
二、 使用 O_DIRECT 的严苛要求
O_DIRECT 虽然强大,但使用起来有非常严格的限制,这也是它“臭名昭著”的原因:
- 内存对齐:用户空间的缓冲区地址必须是块设备逻辑块大小(通常是 512 字节或 4KB)的整数倍。通常需要使用
posix_memalign()来分配内存。 - 长度对齐:
read()/write()的数据长度也必须是块大小的整数倍。 - 偏移量对齐:文件读写的偏移量也必须是块大小的整数倍。
如果违反了以上任何一条,系统调用可能会失败(返回 EINVAL 错误),或者在某些内核版本和文件系统上,内核会“悄悄地”回退到使用页缓存的模式,这就完全违背了使用 O_DIRECT 的初衷。
三、 与你经历的关联:为什么 POSIX AIO 是残缺的?
在我们之前的讨论中提到,传统的 epoll 无法处理磁盘 I/O,而 POSIX AIO (libaio) 是 Linux 上另一个异步 I/O 方案。但它有一个致命缺陷:
POSIX AIO 仅对使用了
O_DIRECT标志的文件描述符有效。
这意味着:
- 如果你想用 POSIX AIO 来异步读写一个普通文件(没有
O_DIRECT),它内部会退化成同步调用,性能毫无提升。 - 你被迫使用
O_DIRECT,从而必须面对它那严苛的内存、长度、偏移量对齐要求,大大增加了编程的复杂度和出错概率。
这正是 io_uring 的革命性所在——它不需要 O_DIRECT 就能提供真正的、高效的异步文件 I/O,彻底解放了开发者。
四、 总结
O_DIRECT 是一个强大的工具,它赋予了高性能应用(如数据库)对 I/O 的终极控制权,避免了“双重缓存”的开销。然而,它像一把锋利的双刃剑,使用不当会伤及自身(程序崩溃或性能下降)。
io_uring
io_uring 来自资深内核开发者 Jens Axboe 的想法,他在 Linux I/O stack 领域颇有研究。 从最早的 patch aio: support for IO polling 可以看出,这项工作始于一个很简单的观察:随着设备越来越快, 中断驱动(interrupt-driven)模式效率已经低于轮询模式 (polling for completions) —— 这也是高性能领域最常见的主题之一。
io_uring的基本逻辑与 linux-aio 是类似的:提供两个接口,一个将 I/O 请求提交到内核,一个从内核接收完成事件。- 但随着开发深入,它逐渐变成了一个完全不同的接口:设计者开始从源头思考 如何支持完全异步的操作。
1 与 Linux AIO 的不同
io_uring 与 linux-aio 有着本质的不同:
-
在设计上是真正异步的(truly asynchronous)。只要 设置了合适的 flag,它在系统调用上下文中就只是将请求放入队列, 不会做其他任何额外的事情,保证了应用永远不会阻塞。
-
支持任何类型的 I/O:cached files、direct-access files 甚至 blocking sockets。
由于设计上就是异步的(async-by-design nature),因此无需 poll+read/write 来处理 sockets。 只需提交一个阻塞式读(blocking read),请求完成之后,就会出现在 completion ring。
-
灵活、可扩展:基于
io_uring甚至能重写(re-implement)Linux 的每个系统调用。
2 原理及核心数据结构:SQ/CQ/SQE/CQE
每个 io_uring 实例都有两个环形队列(ring),在内核和应用程序之间共享:
- 提交队列:submission queue (SQ)
- 完成队列:completion queue (CQ)
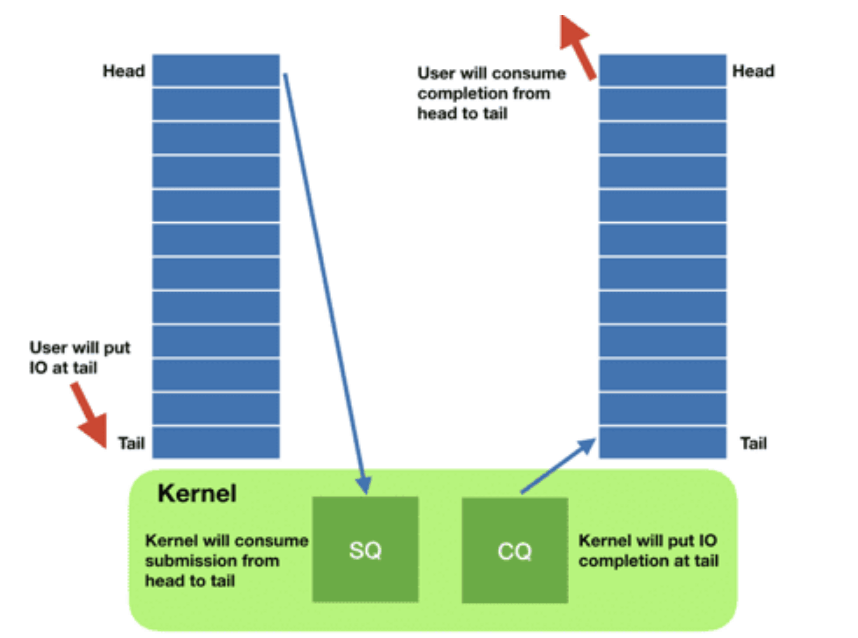
这两个队列:
- 都是单生产者、单消费者,size 是 2 的幂次;
- 提供无锁接口(lock-less access interface),内部使用 内存屏障做同步(coordinated with memory barriers)。
使用方式:
- 请求
- 应用创建 SQ entries (SQE),更新 SQ tail;
- 内核消费 SQE,更新 SQ head。
- 完成
- 内核为完成的一个或多个请求创建 CQ entries (CQE),更新 CQ tail;
- 应用消费 CQE,更新 CQ head。
- 完成事件(completion events)可能以任意顺序到达,到总是与特定的 SQE 相关联的。
- 消费 CQE 过程无需切换到内核态。
3 带来的好处
io_uring 这种请求方式还有一个好处是:原来需要多次系统调用(读或写),现在变成批处理一次提交。
还记得 Meltdown 漏洞吗?当时我还写了一篇文章 解释为什么我们的 Scylla NoSQL 数据库受影响很小:aio 已经将我们的 I/O 系统调用批处理化了。
io_uring 将这种批处理能力带给了 storage I/O 系统调用之外的 其他一些系统调用,包括:
readwritesendrecvacceptopenatstat- 专用的一些系统调用,例如
fallocate
此外,io_uring 使异步 I/O 的使用场景也不再仅限于数据库应用,普通的 非数据库应用也能用。这一点值得重复一遍:
虽然
io_uring与aio有一些相似之处,但它的扩展性和架构是革命性的: 它将异步操作的强大能力带给了所有应用(及其开发者),而 不再仅限于是数据库应用这一细分领域。
我们的 CTO Avi Kivity 在 the Core C++ 2019 event 上 有一次关于 async 的分享。 核心点包括:从延迟上来说,
- 现代多核、多 CPU 设备,其内部本身就是一个基础网络;
- CPU 之间是另一个网络;
- CPU 和磁盘 I/O 之间又是一个网络。
因此网络编程采用异步是明智的,而现在开发自己的应用也应该考虑异步。 这从根本上改变了 Linux 应用的设计方式:
- 之前都是一段顺序代码流,需要系统调用时才执行系统调用,
- 现在需要思考一个文件是否 ready,因而自然地引入 event-loop,不断通过共享 buffer 提交请求和接收结果。
4 三种工作模式
io_uring 实例可工作在三种模式:
-
中断驱动模式(interrupt driven)
默认模式。可通过 io_uring_enter() 提交 I/O 请求,然后直接检查 CQ 状态判断是否完成。
-
轮询模式(polled)
Busy-waiting for an I/O completion,而不是通过异步 IRQ(Interrupt Request)接收通知。
这种模式需要文件系统(如果有)和块设备(block device)支持轮询功能。 相比中断驱动方式,这种方式延迟更低(连系统调用都省了), 但可能会消耗更多 CPU 资源。
目前,只有指定了 O_DIRECT flag 打开的文件描述符,才能使用这种模式。当一个读 或写请求提交给轮询上下文(polled context)之后,应用(application)必须调用
io_uring_enter()来轮询 CQ 队列,判断请求是否已经完成。对一个 io_uring 实例来说,不支持混合使用轮询和非轮询模式。
-
内核轮询模式(kernel polled)
这种模式中,会 创建一个内核线程(kernel thread)来执行 SQ 的轮询工作。
使用这种模式的 io_uring 实例, 应用无需切到到内核态 就能触发(issue)I/O 操作。 通过 SQ 来提交 SQE,以及监控 CQ 的完成状态,应用无需任何系统调用,就能提交和收割 I/O(submit and reap I/Os)。
如果内核线程的空闲时间超过了用户的配置值,它会通知应用,然后进入 idle 状态。 这种情况下,应用必须调用
io_uring_enter()来唤醒内核线程。如果 I/O 一直很繁忙,内核线性是不会 sleep 的。