NUMA-Aware Scheduling介绍
NUMA-Aware Scheduling
https://zhuanlan.zhihu.com/p/713060080
一、 什么是 NUMA?
NUMA (Non-Uniform Memory Access,非统一内存访问) 是现代多处理器服务器(尤其是AI服务器)的标准架构。
- 核心思想:将CPU和内存划分为多个“节点”(Node)。每个节点内的CPU访问本节点的内存速度极快(本地内存访问),而访问其他节点的内存则速度较慢(远程内存访问),存在显著的延迟和带宽差异。
- 类比:想象一个办公室有多个小组,每个小组有自己的文件柜(本地内存)。找自己组的文件柜拿资料很快,但去别的组借资料就要走过去,花时间。
在一台配备8块GPU和2个CPU插槽的AI服务器上,通常会形成2个或4个NUMA节点。GPU通常通过PCIe总线直连到某个特定的CPU(NUMA节点)上。
二、 为什么需要 NUMA-Aware Scheduling?
在传统的、非NUMA感知的调度下,操作系统或调度器(如K8s原生调度器)可能会做出灾难性的决策:
- 场景:一个需要大量内存的大模型推理Pod被调度到NUMA Node 0上的CPU核心,但它的内存却被分配到了NUMA Node 1上。
- 后果:该Pod的进程需要频繁地通过“慢速通道”去访问远程内存,导致内存带宽成为瓶颈,CPU和GPU大量时间在等待数据,整体性能可能下降30%甚至更多。这与你追求的“提升集群利用率”和“GPU复用”目标背道而驰。
NUMA-Aware Scheduling 的核心目标就是:让进程(Pod)的计算资源(CPU)和它所需的内存资源,尽可能位于同一个NUMA节点上,从而最大化内存访问速度,消除性能瓶颈。
三、 NUMA-Aware Scheduling 如何工作?
它不是一个单一的功能,而是一套协同工作的策略:
- 拓扑感知:调度器(如 Volcano)必须能够感知到集群中每个节点的NUMA拓扑结构,知道哪些CPU核心、哪些内存块、哪些GPU设备属于哪个NUMA节点。
- 亲和性绑定:
- CPU亲和性:将Pod的进程绑定到特定NUMA节点的CPU核心上。
- 内存分配策略:使用
numactl或内核的mbind()系统调用,强制进程的内存从本地NUMA节点分配。 - 设备亲和性:对于GPU任务,不仅要考虑CPU和内存,还要确保Pod被调度到其GPU所在的NUMA节点上。因为GPU与CPU之间的数据传输(如模型参数加载)也受NUMA影响。
- 调度决策:调度器在为Pod选择节点时,不仅要考虑节点的总资源(CPU、内存、GPU),还要考虑该节点内部的NUMA资源分布。它会优先选择能将Pod的所有资源(CPU、内存、GPU)都“塞进”同一个NUMA节点的方案。
四、 Volcano 与 NUMA-Aware Scheduling
Volcano 作为面向高性能计算的调度器,对 NUMA 有原生的支持。
- 通过插件实现:Volcano 有一个
nodeorder插件,它可以根据节点的拓扑信息(包括NUMA)对节点进行打分排序。在allocateAction 的优选阶段,它会选择NUMA局部性最好的节点。 - 与你的代码阅读关联:你在阅读 Volcano 源码时看到的
nodeOrderFns和BatchNodeOrderFn,正是实现这种“优选”逻辑的钩子。NUMA感知是这些打分函数中一个非常重要的考量维度。
五、 总结
NUMA-Aware Scheduling 不是锦上添花,而是AI时代高性能计算的刚需。 它是在硬件层面为你的“GPU超卖”、“带宽限制”等上层优化保驾护航的基石。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Roger-Lv's space!
相关推荐

2025-09-17
k8s helm
K8s Helm 一、 Helm 是什么? Helm 是 Kubernetes 的包管理器。 你可以把它类比为: Linux 世界的 yum 或 apt-get:用来安装、升级、配置和管理软件包。 Node.js 世界的 npm:用来管理项目依赖。 Python 世界的 pip:用来安装和管理库。 只不过,Helm 管理的“包”是 Kubernetes 应用。这个“包”在 Helm 中被称为 Chart。 二、 为什么需要 Helm?—— 解决 K8s 原生部署的痛点 想象一下,你在实习时,需要部署一个包含以下组件的复杂 AI 推理服务: 1 个前端 Web 服务 Deployment 1 个后端 API 服务 Deployment 1 个 Redis 缓存 Deployment + Service 1 个 PostgreSQL 数据库 StatefulSet + Service 1 个 Ingress 资源用于对外暴露服务 10 个 ConfigMap 和 Secret 用于配置管理和密钥注入 1 个 HorizontalPodAutoscaler (HPA) 用于自动...
2025-09-17
k8s 探针
k8s 探针 三类探针的作用域 1. 存活探针(Liveness Probe) 作用:判断Pod是否存活 影响:失败时重启Pod 范围:仅影响Pod生命周期 2. 就绪探针(Readiness Probe) 作用:判断Pod是否准备好接收流量 影响:控制Pod是否加入Service的Endpoint 范围:影响Service流量分发 3. 启动探针(Startup Probe) 作用:判断应用是否启动完成 影响:在启动期间禁用其他探针 范围:仅影响Pod启动过程 与Service的关系详解 就绪探针与Service的关联 12345678910apiVersion: v1kind: Servicemetadata: name: my-servicespec: selector: app: my-app # 选择标签匹配的Pod ports: - port: 80 targetPort: 8080 123456789101112131415apiVersion: v1kind: Podmetadata: labels: app: my-ap...

2024-07-19
Linux系统中卸载anaconda
Linux系统中卸载anaconda 要在Linux系统中卸载Anaconda,你需要执行一系列的命令。这里是一个通用的步骤指南: 找到Anaconda安装脚本: 在安装Anaconda时,它会在你的主目录中创建一个名为anaconda3的文件夹(默认情况下,如果你在安装时选择了不同的名称或位置,请确保使用正确的路径)。 运行Anaconda卸载程序: Anaconda提供了一个卸载程序anaconda-clean,可以帮助你删除Anaconda的配置文件。在终端中运行以下命令: 12conda install anaconda-cleananaconda-clean --yes 这个命令将删除Anaconda的配置文件,并且可以选择创建一个备份。使用–yes选项可以避免在删除每个项目时都要求确认。 删除Anaconda安装目录: 接下来,你需要手动删除Anaconda的安装目录。如果你的安装目录是默认的~/anaconda3,你可以使用以下命令: 1rm -rf ~/anaconda3 如果你的安装目录不是默认的,请确保使用正确的路径。 编辑.bashrc或其他...
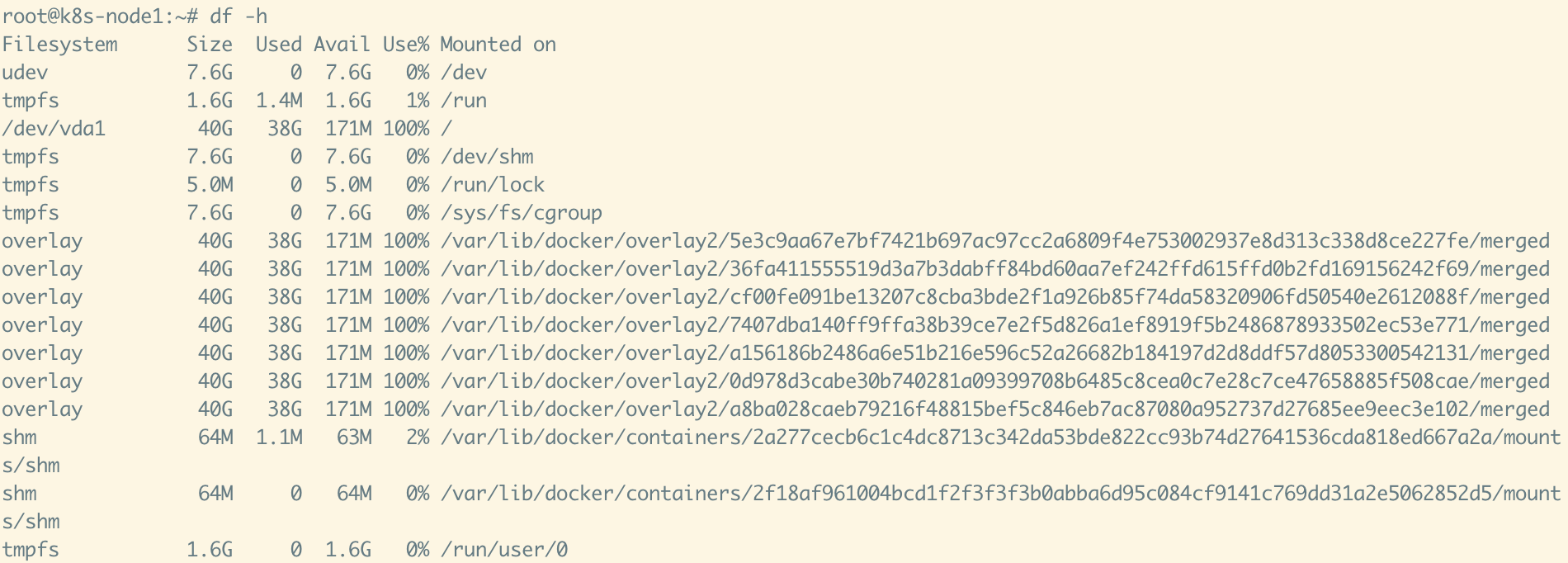
2025-09-01
Linux 云服务器根分区扩容流程(ext4 示例)
Linux 云服务器根分区扩容流程(ext4 示例) 1. 云厂商控制台扩容磁盘 登录云服务商(AWS、阿里云、腾讯云等) 找到对应实例的 系统盘 / 数据盘 修改磁盘大小,例如从 40G → 80G 这一步完成后,虚拟磁盘 /dev/vda 就会变大,但分区和文件系统不会自动变大 2. 确认磁盘和分区情况 12lsblkdf -h lsblk 会显示磁盘和分区大小 df -h 会显示文件系统挂载的空间大小 例子: 12vda 80G└─vda1 40G / 👉 说明磁盘是 80G,但分区还只有 40G 3. 安装扩容工具 (Ubuntu/Debian) 12sudo apt updatesudo apt install -y cloud-guest-utils (CentOS/RHEL) 1sudo yum install -y cloud-utils-growpart 4. 扩展分区 1sudo growpart /dev/vda 1 /dev/vda → 磁盘名 1 → 分区号(即 /dev/vda1) 执行后再看: 1lsblk 应该变成: ...
2025-09-15
如何通过Pod进入到宿主机?
如何通过Pod进入到宿主机? nsenter -a -t 1 bash 命令的作用是让你在一个新的 shell 会话中,进入 PID 为 1 的进程所在的全部命名空间(Namespace)。 通过这种方式,可以从pod中进入到宿主机(全部的namespace都跟宿主机一样) breakdown 如下: nsenter: 这是一个 Linux 命令行工具,用于将当前进程“进入”到指定进程的一个或多个命名空间中。 -t 1: 这个选项指定了目标进程的 PID (Process ID)。在这里,1 是 Linux 系统中第一个启动的进程(通常是 init 或 systemd)的 PID。所有其他进程都是由它或它的子进程派生出来的。 -a: 这个选项是 “all namespaces” 的缩写。它告诉 nsenter 将当前进程加入到目标进程(PID 1)所属于的所有类型的命名空间中,包括但不限于: Mount (mnt) UTS (主机名和域名) IPC (进程间通信) Network PID (进程 ID) User ID Cgroup bash: 这是要在新加入的命名空间环...
2025-09-15
k8s informer通俗易懂详解
Kubernetes Informer 机制详解 核心概念 Informer 是 Kubernetes 中用于监听和缓存资源对象的核心机制,它通过 ListAndWatch 机制实现高效的资源监控。 核心组件及作用 1. Reflector(反射器) 作用:负责从 Kubernetes API Server 获取资源对象 功能: List:获取资源的全量数据 Watch:监听资源的增量变化 将数据放入 Delta FIFO 队列 2. Delta FIFO Queue(增量队列) 作用:存储资源对象的变化(增删改) 特点: 保持操作顺序 存储对象的增量变化(Delta) 线程安全 3. Informer(通知器) 作用:从 Delta FIFO 队列中取出对象并处理 功能: 调用 Indexer 更新本地缓存 触发注册的事件处理器 4. Indexer(索引器) 作用:本地缓存,提供快速查询 功能: 存储资源对象的本地副本 提供基于索引的快速查找 线程安全的读写操作 5. Resource Event Handlers(资源事件处理器) ...
评论




