Nano-vllm 项目学习
Nano-vllm 项目学习
项目地址:https://github.com/GeeeekExplorer/nano-vllm
vllm介绍:https://zhuanlan.zhihu.com/p/693279132
paged attention:https://zhuanlan.zhihu.com/p/691038809
nano vllm: https://zhuanlan.zhihu.com/p/1923689524778766954
-
请求(request)可理解为操作系统中的一个进程
-
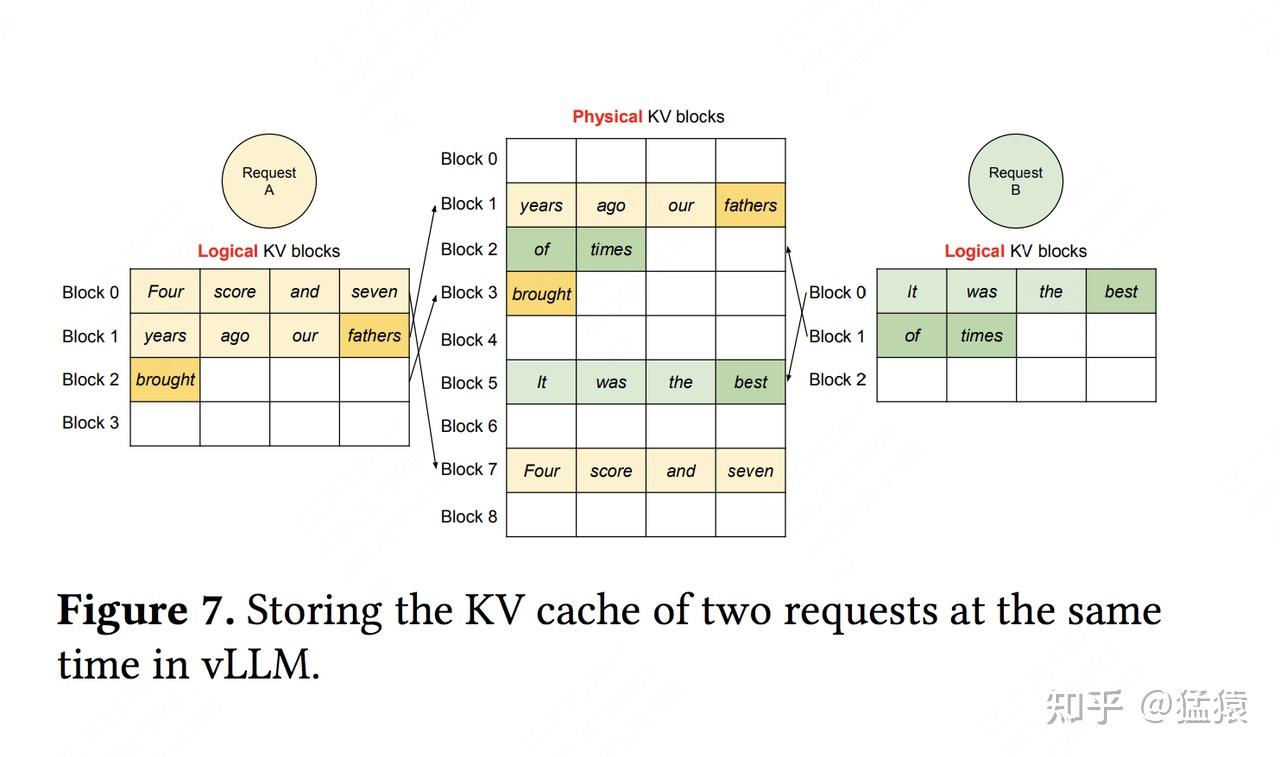
逻辑内存(logical KV blocks)可理解为操作系统中的虚拟内存,每个block类比于虚拟内存中的一个page。每个block的大小是固定的,在vLLM中默认大小为16,即可装16个token的K/V值
-
块表(block table)可理解为操作系统中的虚拟内存到物理内存的映射表
-
物理内存(physical KV blocks)可理解为操作系统中的物理内存,物理块在gpu显存上,每个block类比于虚拟内存中的一个page
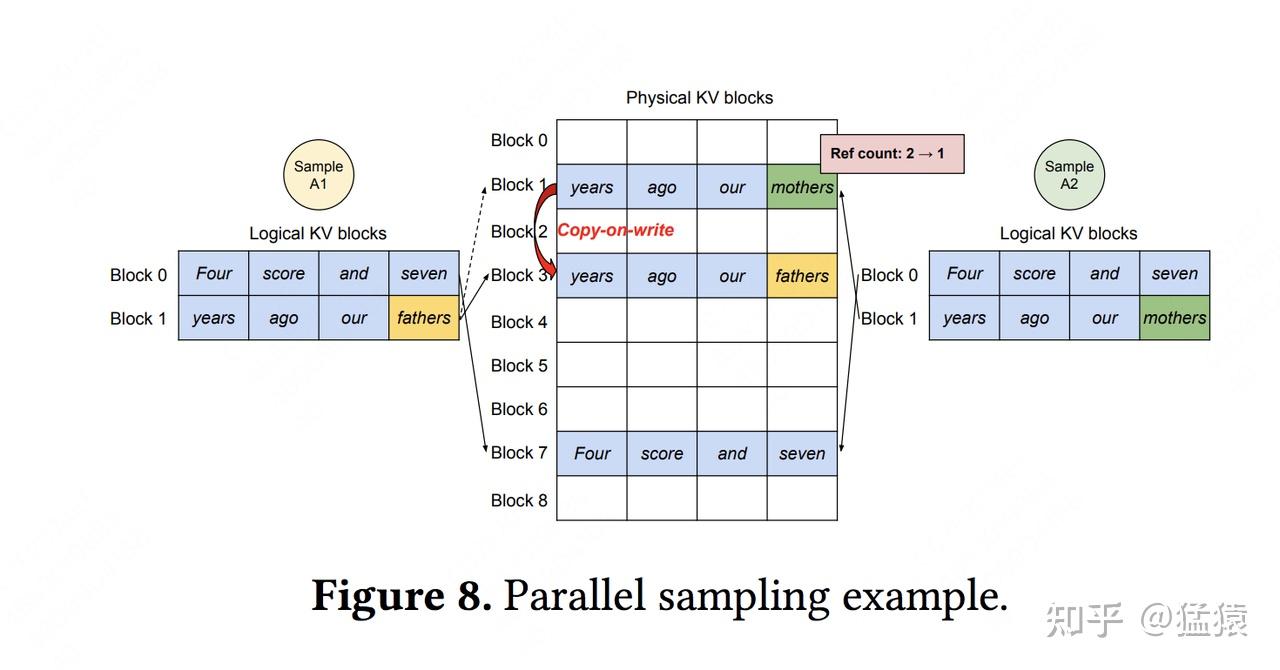
 vLLM节省KV cache显存的核心思想是,对于相同数据对应的KV cache,能复用则尽量复用;无法复用时,再考虑开辟新的物理空间。
vLLM节省KV cache显存的核心思想是,对于相同数据对应的KV cache,能复用则尽量复用;无法复用时,再考虑开辟新的物理空间。vLLM对请求的调度处理流程:
- 当一堆请求来到vLLM服务器上时,按照**First-Come-First-Serve(FCFS)**原则,优先处理那些最早到来的请求。
- 当gpu资源不足时,为了让先来的请求能尽快做完推理,vLLM会对那些后到来的请求执行“抢占”,即暂时终止它们的执行。
- 一旦vLLM决定执行抢占操作,它会暂停处理新到来的请求。在此期间,它会将被抢占的请求相关的KV block全部交换(swap)至cpu上。等交换完成后,vLLM才会继续处理新到来的请求。
- 部分情况下,对于一些seq,vllm会抛弃它的kv cache,将它重新放入等待队列中,后续重新做prefill(recomputation)
 vLLM节省KV cache显存的核心思想是,对于相同数据对应的KV cache,能复用则尽量复用;无法复用时,再考虑开辟新的物理空间。
vLLM节省KV cache显存的核心思想是,对于相同数据对应的KV cache,能复用则尽量复用;无法复用时,再考虑开辟新的物理空间。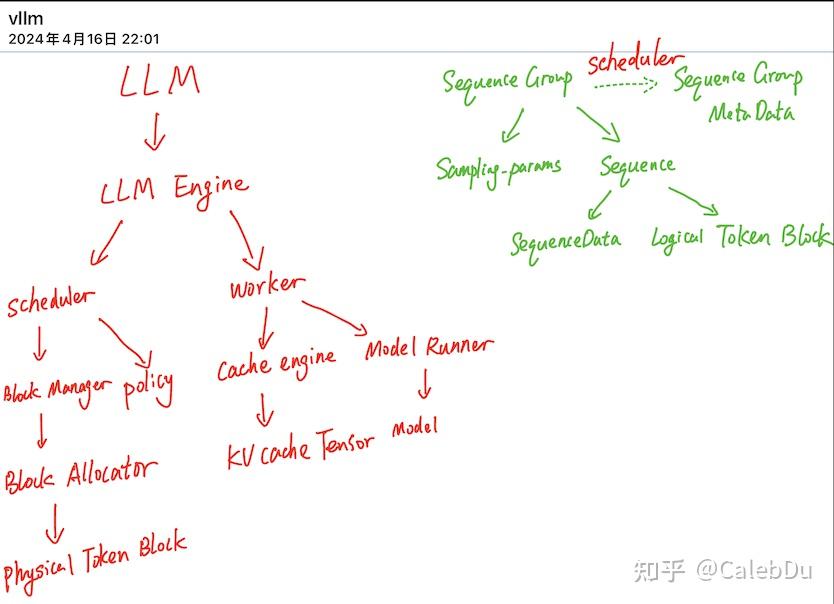
可以看这个公众号的这篇:
https://mp.weixin.qq.com/s/KxRWSAjw8r_9GkVP-skbZg

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Roger-Lv's space!
相关推荐

2024-08-06
医疗垂直领域大模型WiNGPT2的部署和性能对比
医疗垂直领域大模型WiNGPT2的部署和性能对比 WiNGPT2部署和运行 123456git clone https://github.com/winninghealth/WiNGPT2.gitcd WiNGPT2mkdir winninghealthcd winninghealthgit clone https://hf-mirror.com/winninghealth/WiNGPT2-7B-Chatcd .. 若没有以下这三个库,则安装gradio、tiktoken、pip install einops flash_attn 123pip install gradiopip install tiktokenpip install einops flash_attn 选一个目录作为cache(前提是这个目录已经存在且有权限读写) 12# 遇到报错 [Errno 13] Permission denied: '/data/.cache/huggingface/modules/transformers_modules/WiNGPT2-7B-Chat'expor...
2024-08-07
法律垂类大模型DISC-LawGPT的部署运行和对比
法律垂类大模型DISC-LawGPT的部署运行和对比 部署和运行 123456789101112131415# 部署git clone https://github.com/FudanDISC/DISC-LawLLM.gitcd DISC-LawLLMpip install -r requirements.txtmkdir ShengbinYuecd ShengbinYuegit clone https://hf-mirror.com/ShengbinYue/DISC-LawLLMcd ..mkdir cache# 遇到报错 [Errno 13] Permission denied: '/data/.cache/huggingface/modules/transformers_modules/DISC-LawLLM'export HF_HOME="~/verticalLLM/lzjr/DISC-LawLLM/cache" # 如果遇到CUDA error: out of memory 用 watch -n 0.5 nvidia-smi查看显...

2025-08-18
Camel框架
NeurIPS 2023|AI Agents先行者CAMEL:第一个基于大模型的多智能体框架 转自:https://zhuanlan.zhihu.com/p/671093582 AI Agents是当下大模型领域备受关注的话题,用户可以引入多个扮演不同角色的LLM Agents参与到实际的任务中,Agents之间会进行竞争和协作等多种形式的动态交互,进而产生惊人的群体智能效果。本文介绍了来自KAUST研究团队的大模型心智交互CAMEL框架(“骆驼”),CAMEL框架是最早基于ChatGPT的autonomous agents知名项目,目前已被顶级人工智能会议NeurIPS 2023录用。 1777dbe9073c4bcd8ab59365481bcafc.png 论文题目: CAMEL: Communicative Agents for “Mind” Exploration of Large Scale Language Model Society 论文链接: https://ghli.org/camel.pdf 代码链接: https://github.com/camel-a...
2025-08-17
多Agent
多Agent https://www.zhihu.com/question/642650878/answer/1896282773486011813 https://zhuanlan.zhihu.com/p/1908922657027621854 多Agent系统,任务:https://zhuanlan.zhihu.com/p/1909200989090722209 AutoAgents是一个创新的框架,根据不同任务自适应地生成和协调多个专用代理来构建AI团队。AutoAgents通过动态生成多个所需代理并基于生成的专家代理为当前任务规划解决方案,将任务与角色之间的关系相结合。多个专门的代理相互协作以高效地完成任务。该框架还融入了观察者角色,反映指定计划和代理响应,并对其进行改进。该论文在各种基准测试上的实验证明,AutoAgents生成的解决方案比现有的多代理方法更连贯准确,为处理复杂任务提供了新的视角。 地址:https://http://arxiv.org/pdf/2309.17288 代码:https://http://github.com/LinkSoul-AI/Aut...
2025-08-15
ray accelerate trainer lightning pytorch
ray、accelerate、trainer、lightning、pytorch 转自:https://www.zhihu.com/question/1926849595331318550/answer/1928049512619968205 作者:CodeCrafter 链接:https://www.zhihu.com/question/1926849595331318550/answer/1939450608894608104 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 2025 年,纯 PyTorch 是基本功,你必须得会,而且要熟。 它是你的内力,是你理解一切上层框架的基础。 Hugging Face Trainer 是特定领域(尤其是 NLP)的“版本答案”。 如果你就是做微调、做推理,用它,省心省力,快速出活儿。 Lightning 和 Accelerate 是“效率增强器”。 帮你把 PyTorch 代码写得更规范、更工程化,让你从繁琐的样板代码里解放出来,专注于模型本身。 Ray… 这家伙是个“大杀器”,跟前面几个不是一个维度...
2025-08-15
xpu_timer
xpu_timer 转自:https://cloud.tencent.com/developer/article/2418684 背景 随着大型模型的参数量从十亿量级跃升至万亿级别,其训练规模的急剧扩张不仅引发了集群成本的显著上涨,还对系统稳定性构成了挑战,尤其是机器故障的频发成为不可忽视的问题。对于大规模分布式训练任务而言,可观测性能力成为了排查故障、优化性能的关键所在。所以从事大型模型训练领域的技术人,都会不可避免地面临以下挑战: 训练过程中,性能可能会因网络、计算瓶颈等多种因素而不稳定,出现波动甚至衰退; 分布式训练是多个节点协同工作的,任一节点发生故障(无论是软件、硬件、网卡或 GPU 问题),整个训练流程均需暂停,严重影响训练效率,而且浪费宝贵的 GPU 资源。 但在实际的大模型训练过程中,这些问题是很难排查的,主要原因如下: 训练过程为同步操作,很难通过整体性能指标来排除此时哪些机器出现问题,一个机器慢可以拖慢整体训练速度; 训练性能变慢往往不是训练逻辑/框架的问题,通常为环境导致,如果没有训练相关的监控数据,打印 timeline 实际上也没有任何作用,并且同...
评论




