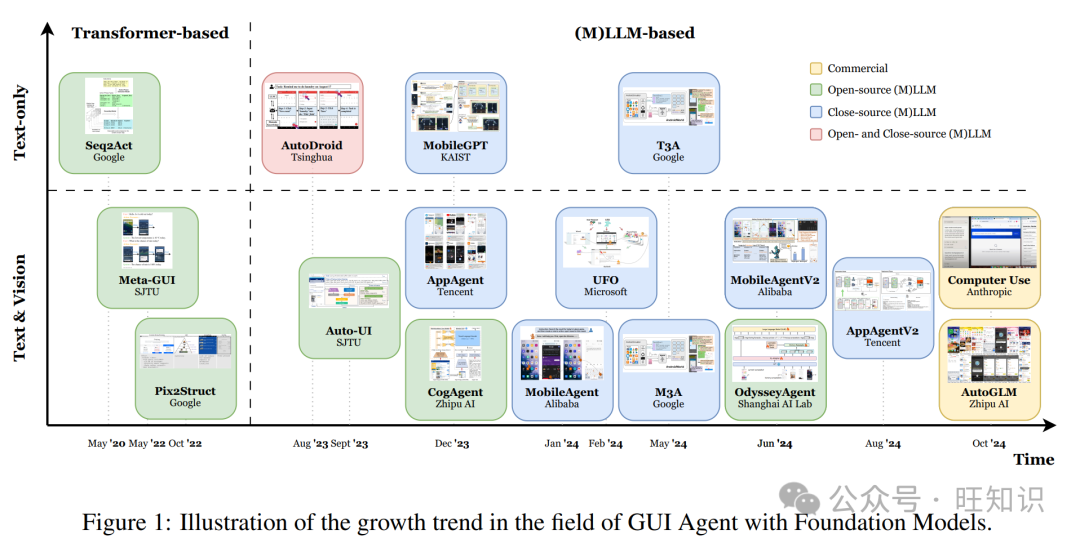
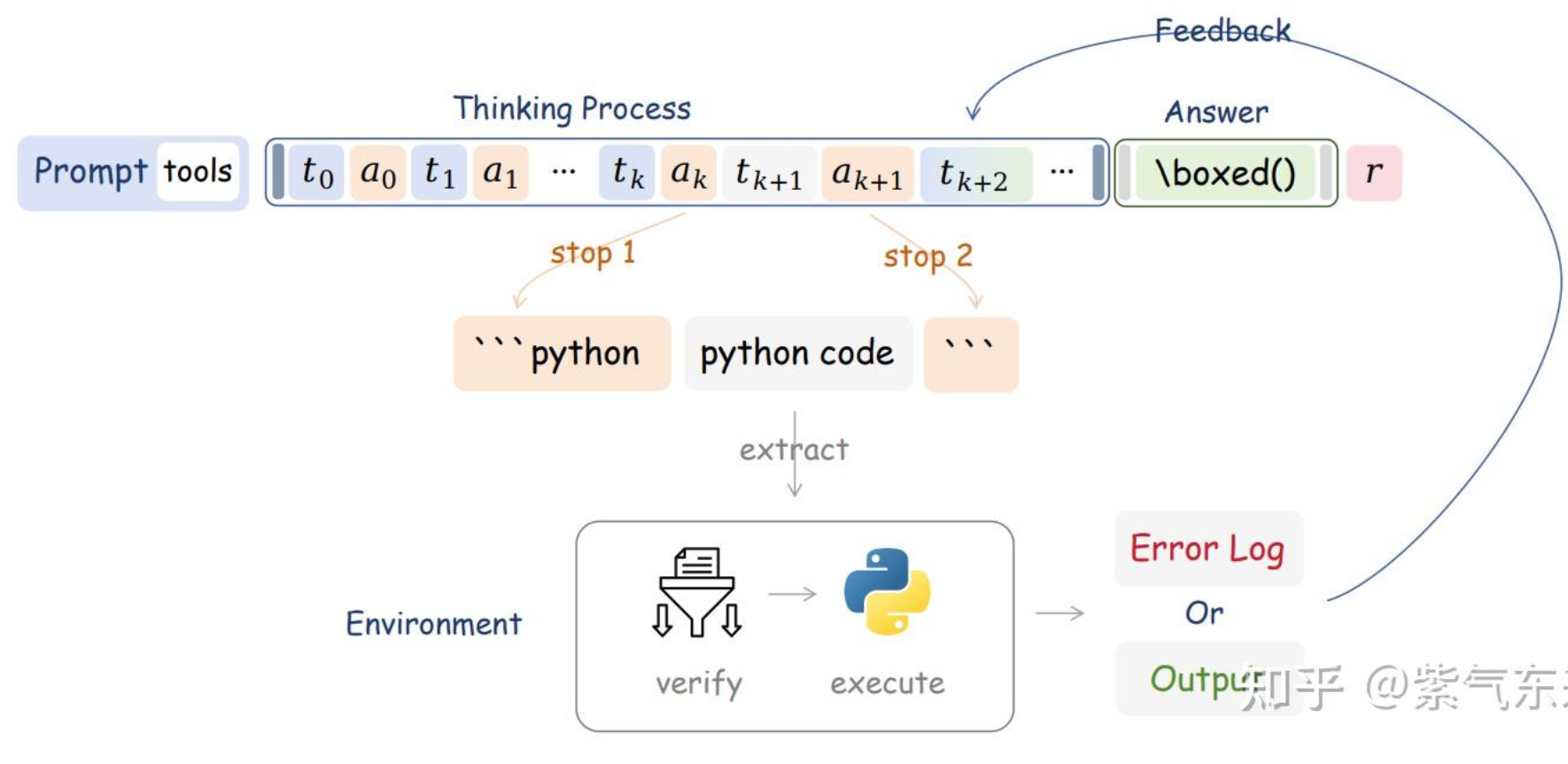
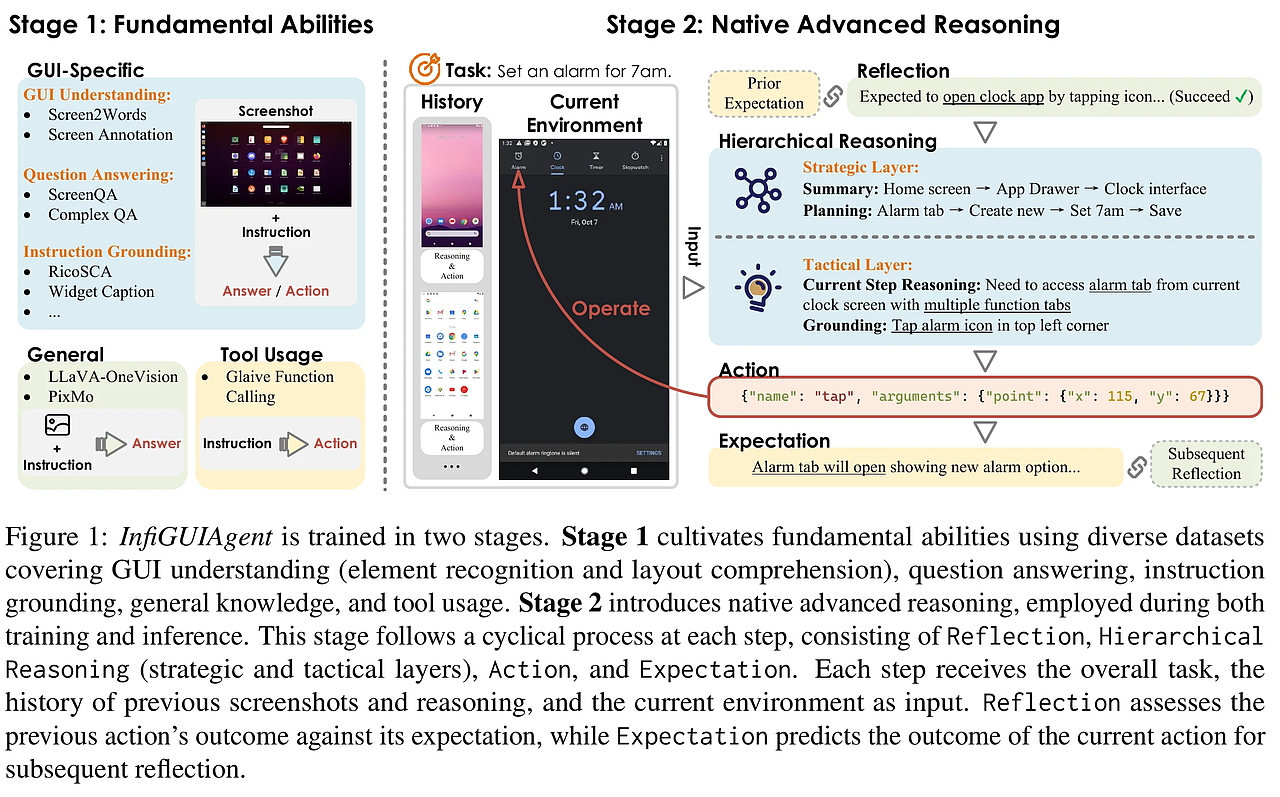
Agent中multi-hop reasoning的跳数如何控制?如何避免无限循环?
Agent中multi-hop reasoning的跳数如何控制?如何避免无限循环?
在 Agent 系统中,multi-hop reasoning(多跳推理) 是指 Agent 通过多次调用工具、反思中间结果、逐步逼近最终答案的推理过程。例如:
用户问:“马斯克创办的公司中,哪家市值最高?”
→ 第一跳:查“马斯克创办了哪些公司?” → 得到 SpaceX、Tesla、xAI、Neuralink 等
→ 第二跳:查“Tesla 当前市值?”、“SpaceX 估值?” → 比较得出 Tesla 市值最高
→ 返回答案
这类推理能力是 Agent 智能性的体现,但若不加以控制,可能导致:
- 无限循环(如反复调用同一工具,无进展)
- 效率低下(跳数过多,响应慢)
- 资源浪费(API 调用超限、Token 耗尽)
- 错误累积(中间步骤出错导致最终答案错误)
一、如何控制跳数?
1. ✅ 设置最大跳数(Max Hop Limit)
最直接有效的方法:
1 | MAX_HOPS = 5 # 或根据任务复杂度调整,如 3~8 |
📌 实践建议:
- 简单任务(单工具调用):max_hops=2~3
- 复杂分析/多源比对:max_hops=5~8
- 开放式探索(如研究助手):可放宽,但需配合其他机制
2. ✅ 设置 Token / 时间 / 成本预算
跳数不是唯一指标,也可从资源角度控制:
- Token 预算:累计输入+输出 token 达到阈值则终止
- 时间预算:总推理时间 > 30s 则超时
- API 调用次数/费用预算:如最多调用 5 次外部 API
适用于生产环境,避免因模型“钻牛角尖”耗尽资源。
3. ✅ 基于“进展检测”的动态跳数控制(Progress-based Early Stopping)
不是固定跳数,而是判断“是否还在取得有效进展”:
- 如果连续 2 跳没有获得新信息(如重复调用相同参数的工具)
- 或中间答案与上一步高度相似(语义相似度 > 90%)
- 或反思后决定“当前路径无效”
→ 则提前终止或回溯。
📌 实现方式:
1 | last_observation = None |
二、如何避免无限循环?
无限循环通常由以下原因导致:
- 工具调用无状态变化(如反复查同一个无变化的数据)
- 反思模块失效(无法识别重复行为)
- 目标不明确或任务不可解
1. ✅ 历史动作去重(Action Deduplication)
记录已执行的动作(工具名 + 参数),禁止重复执行:
1 | executed_actions = set() |
可配合“参数模糊匹配”(如忽略大小写、空格)提高鲁棒性。
2. ✅ 状态空间检测(State Hashing)
对每一步的“环境状态”生成指纹(如 observation 的 hash 或 embedding),若状态重复出现,则判定为循环:
1 | visited_states = set() |
更高级:用语义向量计算余弦相似度,容忍微小差异。
3. ✅ 引入“反思与回溯”机制(Reflection + Backtrack)
让 Agent 自己判断是否陷入循环:
- 在每步后加入自我提问:“我是否在重复之前的行为?”
- “当前路径是否有助于解决问题?”
- 如果判断“无效”,则回滚一步,尝试其他路径(需支持状态回退)
📌 示例 Prompt:
“你已调用 get_stock_price(‘AAPL’) 三次,结果相同。是否应尝试其他工具或改变策略?请决定下一步。”
4. ✅ 设置“循环检测器”(Cycle Detector)
在控制层维护一个动作序列窗口(如最近 3 步),检测是否出现循环模式:
1 | # 检测 [A, B, A, B] 或 [A, A, A] 类型的循环 |
5. ✅ 引入“外部监督信号”或“验证器”
- 在关键步骤插入验证(如:当前中间答案是否更接近目标?)
- 使用小模型或规则判断“是否值得继续”
- 人工规则兜底:如“同一工具在一分钟内最多调用 3 次”
三、进阶技巧:结合规划(Planning)减少无效跳数
在开始推理前,让 Agent 先制定计划(Plan then Execute):
用户问题 → 生成推理计划(如:“先查公司列表,再查各公司市值,最后比较”)→ 按计划执行,跳数自然受限
计划本身可限制步骤数:
1 | { |
→ 实际执行时若超出计划步数,可报警或终止。
四、监控与可观测性(Observability)
在生产系统中,建议记录:
- 每次推理的跳数、耗时、token 消耗
- 循环/停滞事件日志
- 工具调用序列
用于后续:
- 自动调整 max_hops 策略
- 优化提示词或工具设计
- 构建“推理效率排行榜”
✅ 最佳实践总结
| 控制目标 | 推荐方法 |
|---|---|
| 控制跳数上限 | 设置 max_hops(3~8) |
| 避免重复调用 | 动作签名去重 + 状态哈希 |
| 避免无效循环 | 进展检测 + 循环模式识别 + 反思机制 |
| 提升效率 | 规划先行 + 预算控制(token/time/cost) |
| 生产级鲁棒性 | 多层防御 + 日志监控 + 自动熔断 |
🎯 一句话总结:
通过“硬性跳数限制 + 动态进展判断 + 历史动作/状态去重 + 反思回溯机制”四层防御,可有效控制 multi-hop reasoning 的跳数并避免无限循环,让 Agent 既聪明又可控。
合理设计这些机制,是构建高可靠、高效率生产级 Agent 的关键所在。
✅ 是的,在 LangGraph 中,完全可以在 State 中记录跳数、历史动作、状态哈希、循环检测标记等信息 —— 这正是 LangGraph 的核心设计理念之一:通过“状态管理”实现可控、可观测、可回溯的多跳推理流程。
🌟 为什么 LangGraph 适合做这件事?
LangGraph 是基于 状态机(State Machine) 和 图计算(Graph-based Execution) 的 Agent 框架,其核心思想是:
“把 Agent 的每一步推理,建模为对共享状态(State)的读写操作,通过节点(Node)和边(Edge)控制流转。”
因此,你可以在 State 中:
- 记录当前跳数
- 存储历史工具调用序列
- 缓存中间结果/观察(Observation)
- 标记是否陷入循环
- 存储预算(token/time/cost)
- 甚至保存“反思结论”或“计划草稿”
🧱 一、如何在 State 中定义这些控制字段?
首先,定义一个包含控制信息的 State 类(使用 Pydantic 或 TypedDict):
1 | from typing import List, Optional, TypedDict, Any |
或者使用 Pydantic(推荐,类型更安全):
1 | class ActionRecord(BaseModel): |
🔄 二、在 Node 中更新和检查状态
每个节点(如 reason, call_tool, reflect)都可以读写 State:
示例:工具调用节点(记录动作 + 跳数 + 去重)
1 | def call_tool_node(state: AgentState) -> AgentState: |
🚦 三、在 Edge 中控制流程跳转(是否终止/循环)
LangGraph 的 edges(条件边)可以根据 State 决定下一步去哪:
1 | def should_continue(state: AgentState) -> str: |
然后在图中定义边:
1 | from langgraph.graph import StateGraph |
📊 四、进阶:在 State 中加入“规划”与“预算”
你还可以在 State 中加入:
1 | class AgentState(BaseModel): |
然后在节点中检查:
1 | if state.total_tokens > state.token_budget: |
✅ 五、优势总结
在 LangGraph 的 State 中记录控制信息,带来以下好处:
| 功能 | 实现方式 | 优势 |
|---|---|---|
| 跳数控制 | state.hop_count + 条件边 |
简单可靠,硬性兜底 |
| 循环检测 | action_history + 签名去重 |
避免无效重复 |
| 进展停滞检测 | 对比 current_observation 相似度 |
避免“原地打转” |
| 资源预算控制 | total_tokens, start_time |
防止成本爆炸 |
| 可观测性 & 调试 | 完整记录每一步状态 | 便于日志、重放、分析、优化 |
| 支持回溯/重试 | 保存历史状态快照 | 可实现“撤销”或“分支探索” |
🎯 最佳实践建议
- State 设计要“面向控制”:除了中间结果,一定要包含控制字段(hop_count, history, budget, flags)。
- 节点职责单一:一个节点只做一件事(如只调用工具,或只做反思),状态变更清晰。
- 边做决策:流程控制逻辑(是否终止/循环/继续)放在
conditional_edges中,与业务逻辑解耦。 - 日志友好:State 可序列化,便于记录完整推理轨迹,用于调试或审计。
- 预留扩展字段:如
metadata: dict,方便后期加监控、AB测试、用户会话等。
💡 示例:完整 State + 控制流程伪代码
1 | # 初始化 |
✅ 结论
LangGraph 的 State 机制,天然适合实现 multi-hop reasoning 的跳数控制与循环避免 —— 你不仅“可以”在 State 中记录这些信息,而且“应该”这么做,这是构建生产级可控 Agent 的最佳实践。
合理利用 State + 条件边 + 历史记录,你可以让 Agent 既具备强大的多步推理能力,又不会“跑飞”或“死循环”,真正做到聪明且可控。
如需,我还可以提供一个完整可运行的 LangGraph 多跳控制示例代码 👍