Memory OS of AI Agent
Memory OS of AI Agent
初读-1
北邮和腾讯nlpAI
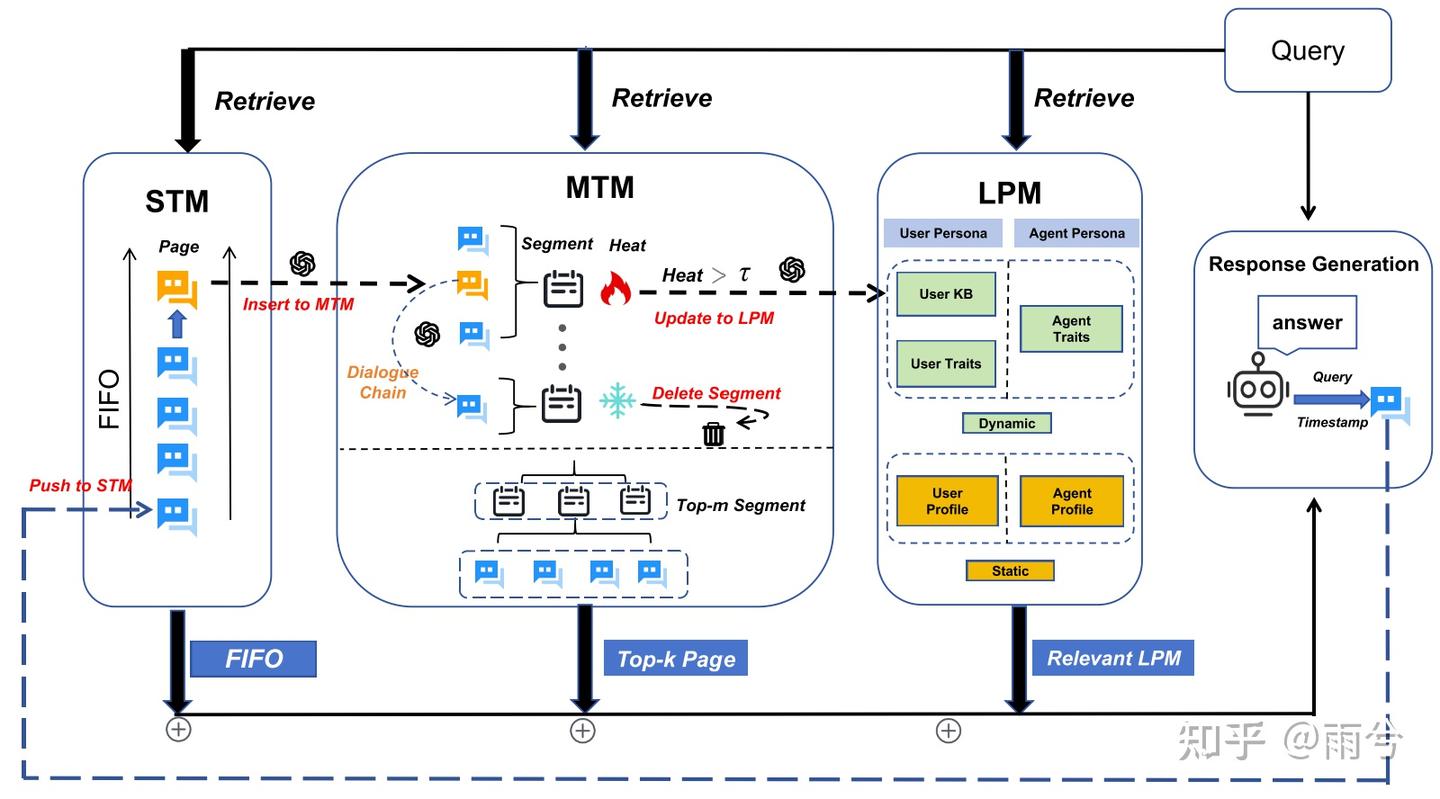
受传统操作系统内存管理机制的启发,MemoryOS 构建了一套分层存储体系,由四个核心模块组成:记忆存储、更新、检索与生成。
该体系架构包括三个层级的记忆单元:短期记忆(STM)、中期记忆(MTM) 和 长期个性记忆(LPM)
MemoryOS 支持关键的动态迁移操作:
短期向中期的更新遵循基于对话链的 FIFO 策略,而中期向长期的迁移则采用分段分页的组织方式,以提升记忆的可维护性和检索效率。
分4个模块:
- memory storage:将信息组织成短期、中期和长期存储单元
- memory updating:通过基于对话链和基于热度的机制的分段分页体系结构动态刷新
- memory retrieval:利用语义分段来查询这些层
- response generation:将检索到的内存信息集成起来,以生成一致的个性化响应
现有技术分类:
1.knowledge-organization:
这类方法关注的是如何组织和保留模型的中间推理状态。更关注记忆的“结构”和“语义关系”,让模型能追踪自己是怎么想的,而不是单次调用哪句话。它不是简单地压缩历史对话,而是试图构建一种可持续更新的推理轨迹或知识网络。
- TiM:用链式结构保存模型的思维过程(chain-of-thought),持续更新,保持逻辑一致性。
- A-Mem:把记忆组织成跨 session 的笔记网络,强调长期语义关联。
- Grounded Memory:融合视觉、语言和知识图谱,把感知和知识结构一起建模,用于更具语境感知的推理。
2.retrieval mechanism-oriented:
这类方法强调的是“外部记忆怎么查、查什么”,通常基于向量数据库或自然语言片段来构建memory pool。虽然都引入了检索机制,但大多缺少更高层的组织调度,记忆结构碎片化、不易管理。
- MemoryBank:存储对话、事件和用户特征,按“遗忘曲线”定期更新,避免累积过时信息。
- AI-town:直接保留自然语言记忆,引入“反思环节”来过滤重要信息。
- EmotionalRAG:除了语义相似度,还结合 agent 当前的情绪状态做 hybrid 检索。
3.architecture-driven frameworks:
这类方法是从 agent 的底层结构动手,对执行流程做改造,让“记忆管理”成为架构内建功能。相比前两类,这些方法更注重“谁来调用记忆、怎么调用”,但通常实现复杂,调试成本高。
- MemGPT:模仿操作系统结构,显式区分读/写调用,设计 memory stack 和控制接口。
- SCM(Self-Controlled Memory):引入双缓冲区和 memory controller,控制 selective recall。
我的问题&解答-2
1.MemoryOS和传统操作系统中的存储管理有何不同?
| 对比维度 | MemoryOS(服务 LLM) | 传统操作系统(服务程序) |
|---|---|---|
| 目标 | 让模型记得“有用内容” | 管理内存空间防止崩溃 |
| 管理内容 | 语义记忆(对话、知识、历史) | 地址、页面、缓存等数据块 |
| ⚙️ 调度方式 | 按语义相关性动态调用(可学习) | 按时间/频率规则调度(固定) |
| 写入机制 | 模型任务驱动写入 | 程序运行自动分配 |
| ️ 淘汰策略 | 忘掉“无用”信息(可训练) | 淘汰旧页面(如LRU) |
| 持久性 | 支持跨会话长期记忆 | 重启即失效(除磁盘) |
MemoryOS 是“为模型设计的大脑”,不是“为程序设计的内存”。前者关注“记住什么最有用”,后者关注“怎么存才高效安全”。
2.记忆分为哪些粒度进行存储?
三层存储机制:STM用于及时对话,MTM用于重复主题摘要,长期个人记忆LPM用于用户或agent偏好
STM:保存「当前或最近一段时间对话」的内存区域
Qₖ:用户提出的问题 Rₖ:模型的回答 Tₖ:时间戳(记录这一轮对话时间)
每一轮对话被记录为一个对话页:pageₖ = { Qₖ, Rₖ, Tₖ }
为了捕捉上下文,还会形成一个对话链(pagechainₖ),结构为:pagechainₖ = { Qₖ, Rₖ, Tₖ, metachainₖ }
其中 metachainₖ 是 LLM 自动生成的对当前对话链的语义摘要。
MTM:将短期对话记忆按主题聚合
采用类操作系统的分段分页架构,每个段表示一个主题,段内包含多个对话页
段构建:通过相似度评分 Fscore 判断对话页是否属于某个段
元摘要:LLM 总结每个段的语义内容,生成 metasegment
Fscore超过阈值就认为是一个段
LPM:在长时间交互中持续记住用户和自身的重要个性信息
1️⃣ User Persona
存储与用户有关的长期信息,包括静态属性、知识和动态特征。
静态属性:固定不变的信息,如:姓名、性别、出生年份等
用户知识库:动态更新的事实类信息;来自对话抽取,可被查询、引用或用于推理。
用户特征:记录用户的兴趣、习惯、偏好等长期演化特征。
2️⃣ Agent Persona
存储 AI 自己的“设定”和行为特征,让其在长时间使用中保持行为一致。
3.存储的位置?
STM 存在 prompt 中、MTM 存在 RAM/向量缓存中、LTM 存在数据库中 —— MemoryOS 按使用频率和重要性分层存储,结合语义检索与调度策略动态管理三类记忆。
4.什么时候加入新记忆?
- 每次实时对话,会直接更新短期记忆
pageₖ = { Qₖ, Rₖ, Tₖ } - 短期记忆满了之后,根据FIFO更新中期记忆
- 中期记忆中的segment达到一定热度值,则触发长期记忆的加入。
5.一条记忆的生命周期可能是什么样的?
- 将其加到 STM 队列尾部;
- 如果超出容量上限,就把最早的页“弹出”,并送入 MTM,参与主题聚合与段构建;
- 在 MTM 中,多条语义相关的对话会被聚成一段(segment),形成更稳定的“中期记忆”;
- 系统会周期性检查这些段落,如果某段信息频繁出现或具长期价值,就写入 LTM;
- 写入后,该记忆会存入数据库,以分段结构长期保存,供后续任务跨 session 检索;
- 若某些记忆长期未被引用,也可能被系统自动降权或淘汰。
6.记忆如何更新?
STM → MTM 更新采用 FIFO 策略:
STM 是一个固定长度的对话队列,新的对话页加入时,最旧的对话页会自动迁移到 MTM,进入更高层级的主题结构管理。
这确保了 MemoryOS 在保留短期上下文的同时,不会丢弃有价值的信息,而是按需递进式归档到中长期记忆中。
MTM → LPM:根据段的热度值,把高热段升级为长期记忆(LPM),低热段则被删除。
Nvisit:被检索过几次(常用)Linteraction:段里包含多少页(内容丰富)Rrecency:最近有没有访问(越新越热)
其中
Rrecency = exp(–Δt / µ),时间越久热度越低。
当MTM 段太多时:热度低的段被删掉;热度高的段保存进 LPM,成为你个性记忆的一部分。
只留下「经常访问 + 内容多 + 最近用过」的主题段
LPM → new LPM:当 MTM 中的段被转移到 LPM 后,更新User Traits、User KB和Agent Traits
- 热段转入 LPM:
- Heat > τ(5)时触发;
- 对应的对话内容视为“有价值的个性信息”。
- 更新用户画像 User Traits:
使用 90 维个性向量,分为三类:
- 基本需求与人格(如外向、谨慎)
- AI 交互偏好(如是否希望 AI 主动建议)
- 内容兴趣标签(如喜欢动漫、美妆、科技)
LLM 从对话段中自动提取这些特征,更新个性画像。
- 更新用户知识库(User KB)和助手特征(Agent Traits):
提取用户事实(如地址、职业) → 存入 User KB 提取关于 AI 的设定、互动偏好 → 存入 Agent Traits
User KB和Agent Traits都是固定长度队列(100 条),用 FIFO 策略 维持
清除冗余:段转存后,Linteraction(交互页数)重置为 0;导致 Heat 下降,防止重复入库,促进信息演化。
7.严格按照层级更新吗?实时2STM,STM2MTM,MTM2LPM?
是的,MemoryOS 默认采用 STM → MTM → LPM 的层级记忆更新机制,信息需逐层迁移、筛选和聚合后,才会进入长期记忆。理论上可以人为或系统触发某些高价值信息直接进入 LPM
8.用户query的时候如何对memoryOS进行检索?
分别从STM,MTM,LRM中检索
STM:检索所有对话页面
MTM:两阶段检索,先选出最匹配段,计算 query 与各segments的语义相关性;然后在该段内选择与query最匹配的dialogue page
LPM:User KB和Assistant Traits分别检索与查询向量具有最高语义相关性的前10个条目作为背景知识
9.如何使用检索到的记忆?
直接将检索到的记忆和query拼接起来喂给大模型
10.如何确保检索到的记忆是有用的?
这其实不是这篇文章的重点。我更关心的是:检索到的记忆是否真正对答案——尤其是“好”答案——产生了贡献?这背后似乎涉及某种因果关系。我们关心的不是“有没有被检索到”,而是“有没有对答案产生正向影响”。而这一过程,本文目前既没有建模,也没有评估。
文章提到使用“向量相似度 + reranker”来提升检索质量,但并没有进一步说明如何判断记忆是否真的对生成有帮助。它也没有记录哪些记忆被实际引用进答案,更没有用这些引用行为来训练检索器。
比如我想知道:
- 你进了答案,但答案有没有因此变好?
- 如果不用你,会不会更简洁、逻辑更清楚?
要真正回答这些问题,可能需要引入回答对比、记忆替换或记忆消融实验,才能更清楚地判断一条记忆的“贡献值”到底是正向还是负向。
我之前读的那篇 RMM 方法倒是用了强化学习来训练检索器,在一定程度上体现了这个思路。说到底,这涉及的是“检索的记忆是否提升了最终输出”的因果链路建模;而目前多数方法仍只是把“被引用”作为一种近似监督信号,离真正的显式建模还有不小差距。
11.什么时候决定将MTM转移到LPM?
Segments with heat exceeding a threshold τ (i.e., 5) are transferred to LPM.
根据segments的热度值,意思当这段记忆被频繁使用,那么它可能很重要,需要长久保存