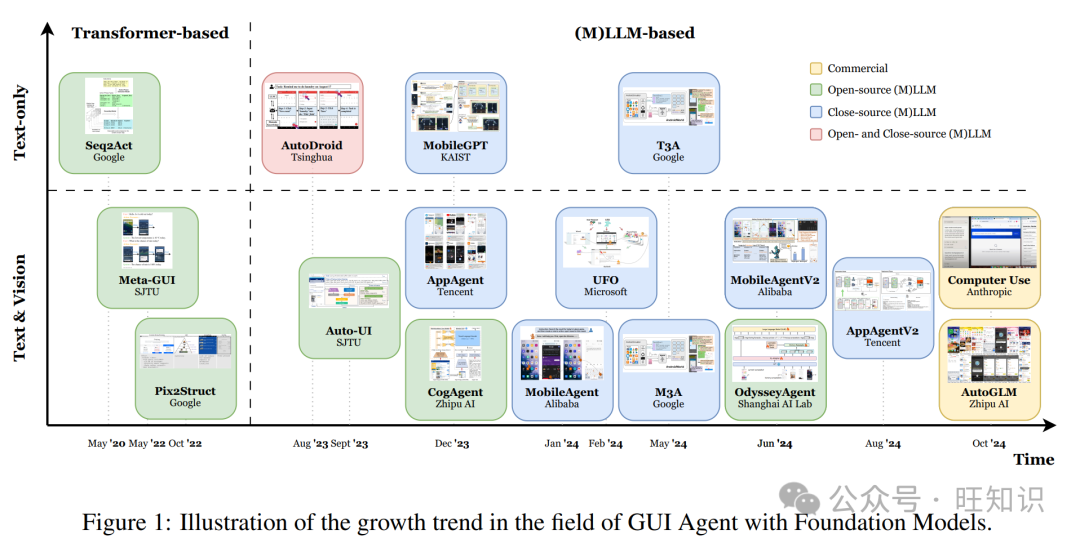
ICML'25 卡内基梅隆大学让Agent从“复读机”变“探索家”
ICML’25 卡内基梅隆大学让Agent从“复读机”变“探索家”
一、先聊个痛点:LLM的“探索无能症”
在说PAPRIKA之前,得先搞懂一个核心问题:为什么现在的AI这么“被动”?
我们平时用ChatGPT、文心一言,大多是“你问我答”的单轮交互——你问“北京天气”,它答“25度”;你问“怎么做番茄炒蛋”,它给步骤。但生活里很多事需要“多轮探索”:比如你丢了快递,得先问快递员“有没有派件记录”,再根据记录查“是不是送错小区”,再针对性找物业——这是一个“行动→看反馈→调整行动”的循环。
LLM在这种循环里特别笨拙,主要因为两个坎:
- 真实交互数据太少,还危险要教AI“探索”,得让它在真实环境里试错——比如让AI真的帮人修家电,修坏了就得赔钱;让AI玩真实游戏,输多了用户就跑了。而且真实场景的交互数据特别乱,比如用户可能说“冰箱响得像拖拉机”,AI很难从中提取关键信息。
- 传统训练是“死记硬背”,不会迁移。之前有研究给AI练“多臂老虎机”(类似选哪个按钮中奖率高),练得再好,换个“猜单词”任务,AI又变回原样。就像学生只会背数学题,换个物理题就懵了——它没学会“通用的探索方法”。
我团队之前也试过给LLM做交互训练,结果要么是AI只会按固定流程走(比如客服只会念话术),要么是探索起来毫无章法(比如玩20问时东问一个西问一个)。直到看到PAPRIKA,才发现原来问题出在“训练思路”上——我们不该教AI“做具体任务”,该教它“怎么学做任务”。
二、PAPRIKA的核心思路:给AI搭个“探索训练营”
PAPRIKA的名字很有意思,源自动画《红辣椒》(Paprika)——里面的梦境侦探能在不同梦境里解谜,就像这个方法训练的AI能在不同任务里探索。它的核心逻辑特别简单:先让AI在一堆“模拟游戏”里练手,总结出通用的探索策略,再让它用这些策略应对新任务。
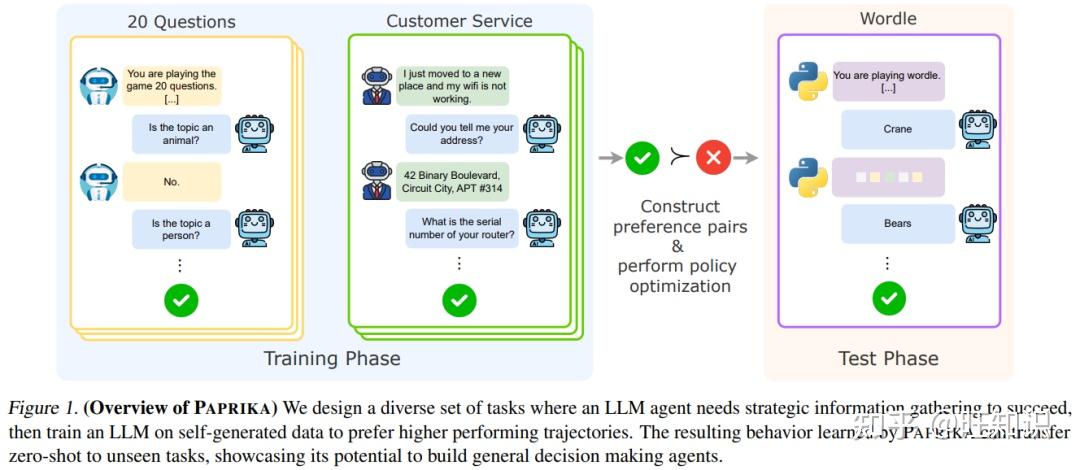
你可以把这个过程想象成“给AI办了个探索训练营”,整个流程分四步,每一步都有巧思:
1. 第一步:设计“多样化的闯关游戏”(任务设计)
要练出通用能力,不能只练一个游戏。PAPRIKA团队设计了10种完全不同的“交互任务”,覆盖了日常探索的各种场景,比如:
- • 20问/猜城市:像玩“你画我猜”,AI要通过提问缩小范围(比如“在北半球吗?”“以美食闻名吗?”);
- • Wordle/Mastermind:猜单词或密码,AI要根据反馈调整(比如猜“apple”后,知道“p在第二位”,下次就围绕这个信息猜);
- • 客服模拟:AI当客服,帮用户修冰箱、修WiFi,得根据用户的回答找问题根源;
- • 扫雷/战舰:在网格里找目标,得平衡“探索新区域”和“聚焦已知线索”(比如扫雷时,先点空白处,再根据数字推地雷位置)。
这些任务就像训练营的“不同器械”:20问练“如何提有效问题”,Wordle练“如何利用反馈调整”,客服练“如何诊断问题”。关键是,每个任务都满足一个条件——需要“探索+利用”结合,不能瞎试,也不能死等。
2. 第二步:让AI“自己录训练视频”(数据生成)
有了游戏,下一步就是让AI自己玩,录下“游戏过程”(也就是交互轨迹),再从中挑“好的”和“差的”当教材。
这里有个关键技巧:用“高多样性采样”让AI多试不同玩法。比如玩20问时,不让AI只问“是动物吗”,而是鼓励它试“是人造的吗?”“需要用电吗?”等不同角度的问题。团队用了一种叫“Min-p采样”的方法,简单说就是“不允许AI总选最熟悉的答案,得偶尔尝试新选项”——像老师让学生做题时,别总做拿手的选择题,也试试应用题。
录完视频后,再给每个任务的轨迹打分:比如20问里,“8步猜中”的是“好轨迹”,“15步没猜中”的是“差轨迹”;客服任务里,“3轮找到问题”的是“好轨迹”,“10轮还在绕圈子”的是“差轨迹”。最后把“好轨迹+差轨迹”配对,就像老师把“满分卷”和“错题卷”放一起,让学生对比。
3. 第三步:让AI“学会分辨好坏”(模型优化)
有了“好差对比卷”,怎么教AI学?PAPRIKA用了两种方法结合,避免AI走极端:
- • **第一种:模仿好的做法(SFT)**先让AI“抄满分卷”——比如把“8步猜中20问”的轨迹给AI看,让它模仿“先问大类(是物品吗?),再问细节(需要用电吗?)”的思路。这就像学生先背范文,熟悉正确的结构。
- • **第二种:理解为什么好(DPO+RPO)**只抄范文不够,得让AI知道“为什么这个做法比那个好”。比如对比“8步猜中”和“15步没猜中”的轨迹,告诉AI:“你看,先问‘是人造的吗’能快速排除一半选项,比一直问‘是红色的吗’高效多了”。
这里用到的“DPO(直接偏好优化)”,可以比喻成“老师批改作业时,不直接改答案,而是告诉学生‘A思路比B思路好’”;而“RPO”就是把“抄范文”和“听讲解”结合起来——避免AI只抄不理解,也避免AI只懂道理不会实操。
我觉得这个设计特别巧妙:之前我们团队只用过SFT,结果AI只会“照葫芦画瓢”,换个任务就不会了;而PAPRIKA加了DPO,相当于让AI“悟出门道”,比如从“20问的高效提问”迁移到“客服的高效问诊”。
4. 第四步:“先易后难”补课(课程学习)
训练时还有个大问题:不同任务难度不一样。比如AI一开始玩“20问(简单 topic)”能很快上手,但玩“扫雷(复杂网格)”只会瞎点,录出来的轨迹全是差的,根本没法学。
PAPRIKA的解决办法是“课程学习”——就像老师给学生安排补课计划,先练简单的,再练难的。具体怎么做?
团队先给每个任务算“学习潜力”:比如一个任务,如果AI玩的时候,“好轨迹和差轨迹差距大”(比如有的能8步猜中,有的20步没猜中),说明这个任务“有东西可学”,优先练;如果AI玩的时候,全是差轨迹(比如扫雷全踩雷),说明太难了,先放一放。
举个例子,20问里“猜苹果”这种简单topic,AI能出好轨迹,也能出差轨迹,学习潜力高,先练;而“猜量子力学概念”这种难topic,AI全是差轨迹,先不练。等AI练会了简单的,再逐步挑战难的——这样既不浪费数据,也不让AI因为总失败而“放弃”。
三、PAPRIKA的硬实力:三个“反常识”的突破
看完流程,你可能会问:这方法真的有用吗?论文里的实验结果,有三个点让我特别惊讶:
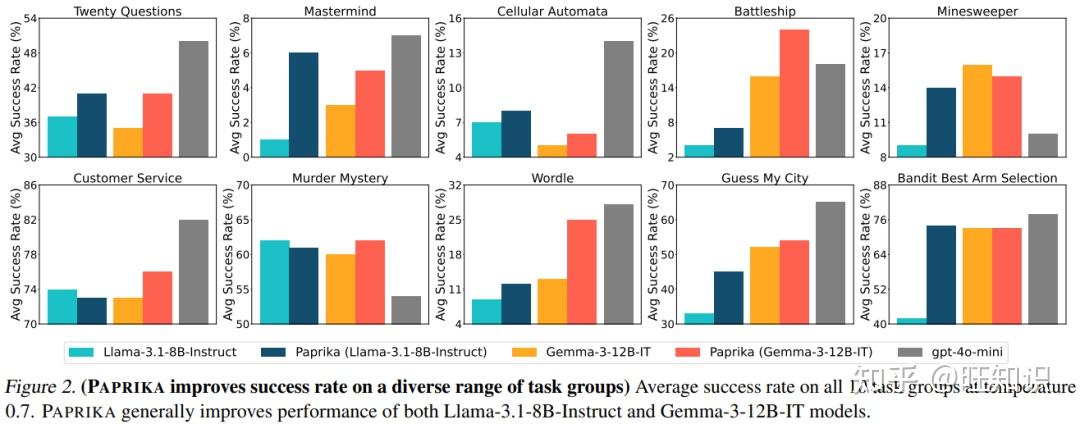
1. 学会的能力能“跨任务迁移”——会玩20问,也会修客服
最核心的突破是“零样本迁移”:AI在10个任务里练完后,遇到完全没练过的新任务,也能表现得很好。
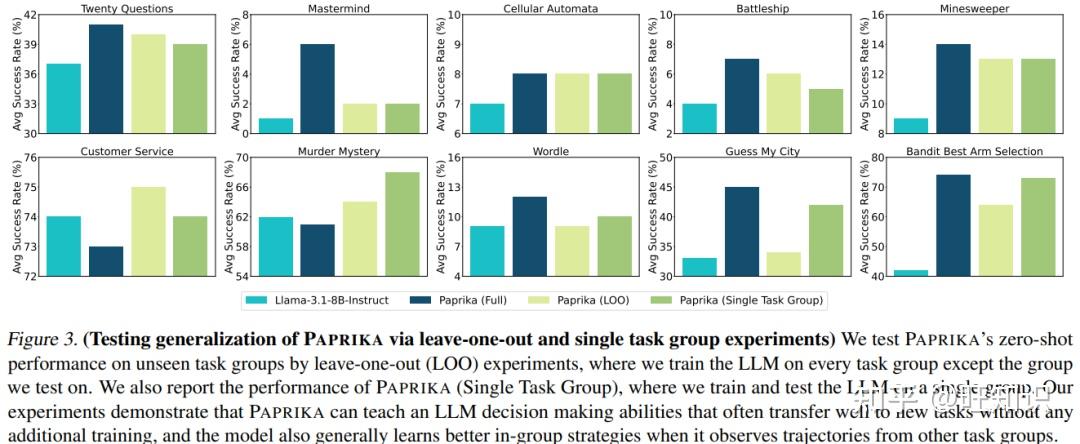
比如团队做了个“留一法”实验:故意不练“多臂老虎机”(选按钮中奖),只练其他9个任务。结果AI面对“老虎机”时,居然能自己学会“先试每个按钮几次(探索),再聚焦中奖率高的(利用)”——要知道,之前的LLM面对这个任务,只会一直选同一个按钮,或者瞎选。
这就像一个人学会了“如何高效提问”(从20问),再去做“采访”(新任务),也能快速找到关键问题——PAPRIKA真正教会了AI“通用的探索逻辑”,而不是“某个任务的操作步骤”。
2. 不用海量数据,效率还很高
传统的RL训练需要几十万甚至几百万条轨迹,而PAPRIKA只用了约2.25万条轨迹(1.7万条SFT数据+0.5万条DPO配对),就让Llama-3.1-8B模型的成功率提升了47%。
为什么这么高效?因为“课程学习”和“好差对比”选对了数据。就像学生补课,不是刷1000道题,而是针对性地分析100道“好题+错题”,效率自然高。
3. 练完探索能力,不丢基础能力
很多人担心:给AI练太多“游戏”,会不会让它连“聊天、写文案”这些基础活都不会了?论文里的实验打消了这个顾虑——PAPRIKA微调后的模型,在MT-Bench、AlpacaEval等通用 benchmarks 上,性能没降反而略有提升。

这就像运动员练专项(比如跑步),不会影响日常走路,反而会让身体协调性更好——PAPRIKA训练的“探索能力”,其实是对LLM“逻辑思考”的强化,反而能帮它更好地应对其他任务。
四、未来能用来干嘛?这些场景马上能落地
看完论文,我第一个想到的就是那些“需要AI主动做事”的场景,比如:
- • **智能客服:从“念话术”到“真诊断”**现在的客服AI,大多是“按关键词回复”,比如你说“WiFi断了”,它只会让你“重启路由器”。如果用PAPRIKA训练,AI能学会“先问‘是光猫闪红灯吗?’(排查线路),再问‘连的是5G还是2.4G?’(排查频段)”——真正像人工客服一样一步步找问题。
- • **游戏AI:从“笨比队友”到“神队友”**现在很多游戏的AI队友,要么只会跟在你后面,要么瞎冲送人头。用PAPRIKA训练后,AI能学会“先探路(探索),再帮你守关键点(利用)”,比如玩CSGO时,AI会先查角落(探索),再根据枪声位置守包(利用)。
- • **辅助决策:帮你“捋清思路”**比如你想选理财产品,AI能帮你“主动提问”:“你能接受多大风险?”“投资期限是1年还是5年?”“更看重收益还是流动性?”——而不是只给你一堆产品介绍,让你自己挑。
五、还有哪些坑要填?研究员的冷静思考
当然,PAPRIKA不是完美的,还有几个需要解决的问题:
-
- **依赖“好的基础模型”**如果基础模型本身很笨(比如连“是/否”都分不清),PAPRIKA也救不了。就像差生连加减都不会,再补微积分也没用——未来可能需要结合“基础能力更强的LLM”来做训练。
-
- **数据生成还是“有点贵”**虽然比传统RL高效,但模拟10个任务的轨迹,还是需要不少计算资源(论文里说API成本约2万美元)。未来可能需要让AI“自己生成新任务”,而不是人工设计,进一步降低成本。
-
- 复杂真实场景还需验证论文里的任务都是“模拟的”(比如客服是LLM扮演的用户),真实世界里的用户可能更“不按常理出牌”(比如说话带方言、逻辑混乱)。下一步需要在真实场景里测试,看看AI能不能应对这些“意外情况”。
结尾:让AI从“会回答”到“会解决问题”
PAPRIKA最让我兴奋的,不是它让AI玩会了20问或扫雷,而是它指出了一个方向:未来的AI,不该只是“问答机器”,而该是“能主动解决问题的伙伴”。
想象一下,以后你家的智能助手,能主动帮你排查家电故障,能陪你玩策略游戏,甚至能帮你梳理工作思路——这一切的基础,就是“主动探索”的能力。