Web Agent综述
WebAgents综述:大模型赋能AI Agent,实现下一代Web自动化
这篇文章是香港理工大学研究人员发表的首篇关于WebAgents的系统性综述,全面梳理了基于大模型的Web自动化智能体研究进展。
核心内容
背景与意义
- 互联网已深度重塑生活,但网络活动存在大量重复低效的"数字苦力"(如反复填写个人信息、手动比对商品参数)
- WebAgents能够根据用户自然语言指令自动完成复杂Web任务,实现网络活动的自动化与智能化
- 例如ChatGPT Agent能独立规划执行任务,无需用户持续监督
WebAgents架构
文章将WebAgents工作流程分为三个关键环节:
-
感知:观察环境
- 基于文本(利用HTML等)
- 基于视觉(利用截图)
- 多模态(结合文本与视觉信息)
-
规划与推理:分析环境并决策
- 任务规划(显式/隐式分解任务)
- 动作推理(反应式/策略性推理)
- 记忆利用(短期记忆与长期记忆)
-
执行:与环境交互
- 定位(确定交互元素位置)
- 交互(点击、滚动等操作或使用API工具)
WebAgents训练方法
- 数据构建:数据预处理(解决多模态差异)与数据增强(数据收集和合成)
- 训练策略:
- 无训练:通过提示词工程直接使用基础大模型
- GUI理解能力训练:提升界面理解能力
- 特定任务微调:针对网页任务技能优化
- 后训练:通过强化学习等方法使Agent持续适应动态变化的网页环境
可信赖性挑战
- 安全与鲁棒性:应对噪声和对抗攻击(如BrowserART测试套件发现的安全漏洞)
- 隐私保护:防止敏感信息泄露(如MEXTRA和EIA攻击揭示的风险)
- 泛化能力:处理分布外数据和跨领域操作
未来研究方向
- 公平性与可解释性:确保无偏见决策和行为可解释
- 评测基准:开发更全面的评估体系
- 个性化WebAgents:结合RAG和记忆机制提供定制化服务
- 领域专用WebAgents:针对教育、医疗等专业领域的适配与应用
核心价值
该综述系统性地梳理了WebAgents的技术架构、训练方法和可信性挑战,特别强调了后训练技术对WebAgents持续适应动态网页环境的重要性,为未来研究提供了清晰的方向指引,预示着人机协作新纪元的到来。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Roger-Lv's space!
相关推荐
2025-08-21
Agentic RL
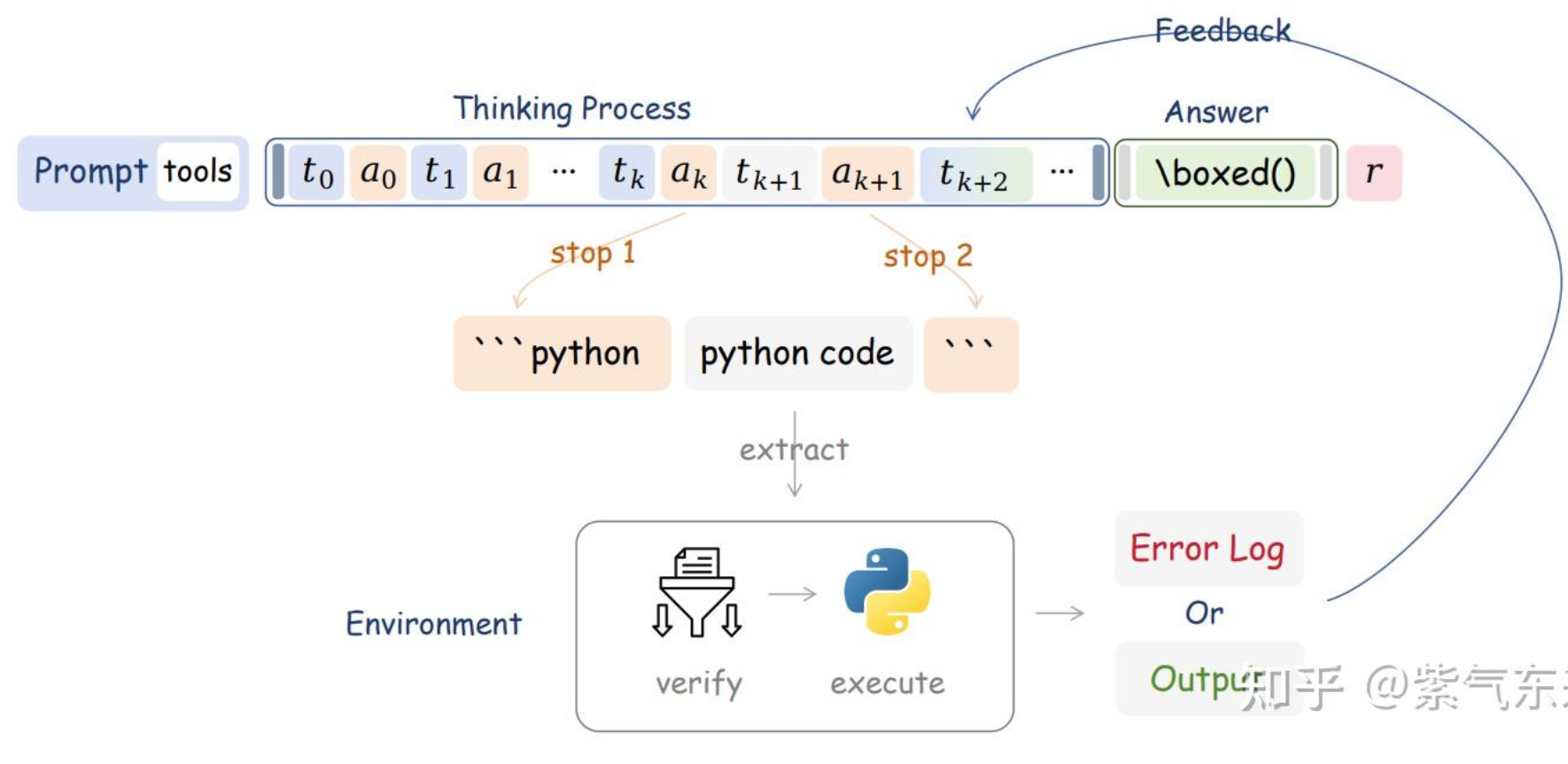
转自:https://zhuanlan.zhihu.com/p/1913905349284591240 通过蒙特卡洛树搜索、过程监督与结果监督、强化学习来提高 LLM 的推理能力,从本质上来说,都是尽可能榨取 LLM 本身的能力,区别可能在于多次尝试、反馈信号、训练方法而已,这类方法可称之为“求诸内”。而由 scaling law 可知,模型的能力是有限的,那么该如何进一步提高LLM在具体问题上的表现呢?近期的答案是,类似 RAG,Multi-Agent 系统,让 LLM 学会使用工具,毕竟人与动物的关键区别也只是“能制造并使用工具”,这种方式则是“求诸外”。那么本篇就以此为中心,重点讨论以下问题: Agentic LLM 的算法逻辑、具体方法与实际表现? RL 如何训练 Agentic LLM,其与 tool using 的 SFT 的差异在哪? Agentic RL 的工程化问题 一、Agentic RL 的算法设计 Agent 和 RL 都并非新鲜事物,而使用 RL 训练基于 LLM 的 agent 则是近期的研究的热点,那么,从算法角度来说,如何理解二者结合的动机、场...
2025-09-01
UI-R1:通过强化学习增强GUI代理的动作预测能力
UI-R1:通过强化学习增强GUI代理的动作预测能力 最近的DeepSeek-R1展示了通过基于规则的强化学习(RL)在大型语言模型(LLMs)中涌现出的推理能力。基于这一理念,我们首次探索了如何利用基于规则的RL来增强多模态大语言模型(MLLMs)在图形用户界面(GUI)动作预测任务中的推理能力。 为此 我们精心整理了一个包含136个具有挑战性任务的小而高质量的数据集,涵盖了移动设备上的五种常见动作类型。 我们还引入了一种统一的基于规则的动作奖励机制,使模型可以通过基于策略的算法(如组相对策略优化(GRPO))进行优化。 实验结果表明,我们提出的数据高效模型 UI-R1-3B 在领域内(ID)和领域外(OOD)任务上都取得了显著改进。具体来说,在ID基准测试 AndroidControl 上,动作类型准确率提高了 15% ,而定位准确率提高了 10.3% ,相较于基础模型(即Qwen2.5-VL-3B)。在OOD GUI定位基准ScreenSpot-Pro上,我们的模型超越了基础模型,提高了 6.0% ,并实现了与更大模型(例如OS-Atlas-7B)相当的性能,这些模型是...
2025-09-11
Routine:A Structural Planning Framework for LLM Agent System in Enterprise
Routine:A Structural Planning Framework for LLM Agent System in Enterprise 这篇论文的核心价值在于,它没有停留在“让大模型自己想”的层面,而是创造性地提供了一个“剧本”,从根本上解决了企业级Agent落地难的痛点。 我们将从问题根源、解决方案(Routine框架)、系统架构、训练方法、实验结果、核心洞见六个维度,层层递进地进行深度剖析。 PS:在附录提供了prompt、routin的格式、多步工具调用的例子 一、 问题根源:为什么企业级Agent总是“掉链子”? 论文开篇就犀利地指出了当前LLM Agent在企业环境中失败的三大根本原因: “无知” (Lack of Domain-Specific Process Knowledge): 通用大模型(如GPT-4)是“通才”,但不是“专才”。它不了解企业内部错综复杂的业务流程。 后果:模型在规划时会遗漏关键步骤。论文特别指出,最容易被忽略的是权限验证(permission verification)和模型生成(model generation)这类工...

2025-08-18
Camel框架
NeurIPS 2023|AI Agents先行者CAMEL:第一个基于大模型的多智能体框架 转自:https://zhuanlan.zhihu.com/p/671093582 AI Agents是当下大模型领域备受关注的话题,用户可以引入多个扮演不同角色的LLM Agents参与到实际的任务中,Agents之间会进行竞争和协作等多种形式的动态交互,进而产生惊人的群体智能效果。本文介绍了来自KAUST研究团队的大模型心智交互CAMEL框架(“骆驼”),CAMEL框架是最早基于ChatGPT的autonomous agents知名项目,目前已被顶级人工智能会议NeurIPS 2023录用。 1777dbe9073c4bcd8ab59365481bcafc.png 论文题目: CAMEL: Communicative Agents for “Mind” Exploration of Large Scale Language Model Society 论文链接: https://ghli.org/camel.pdf 代码链接: https://github.com/camel-a...

2025-08-13
MCP-Zero:LLM智能体主动工具发现的新范式
MCP-Zero:LLM智能体主动工具发现的新范式 转自:https://zhuanlan.zhihu.com/p/1928760473630798292 引言 大语言模型(LLMs)在处理复杂任务时,通常需要借助外部工具来扩展其能力范围。然而,当前 LLM 智能体与工具集成的主流范式存在显著局限性:它们往往将预定义的工具模式注入到系统提示中,导致模型扮演被动选择者的角色,而非主动发现所需能力。这种方法不仅造成了巨大的上下文开销,也限制了模型的决策自主性。 为了解决这些问题,本文引入了 MCP-Zero,一个旨在恢复 LLM 智能体工具发现自主性的主动框架。MCP-Zero 的核心思想是,智能体能够主动识别自身能力差距,并按需请求特定工具,从而将自身从大规模检索器转变为真正的自主智能体。该框架通过三大核心机制运行:主动工具请求、分层语义路由和迭代能力扩展。这些机制共同作用,使得 MCP-Zero 能够在最小化上下文开销和保持高准确性的前提下,动态构建多步工具链。 图:LLM 智能体的工具选择范例比较。(a) 基于系统提示的方法将所有 MCP 工具模式注入上下文,导致提示过长,...
2025-08-27
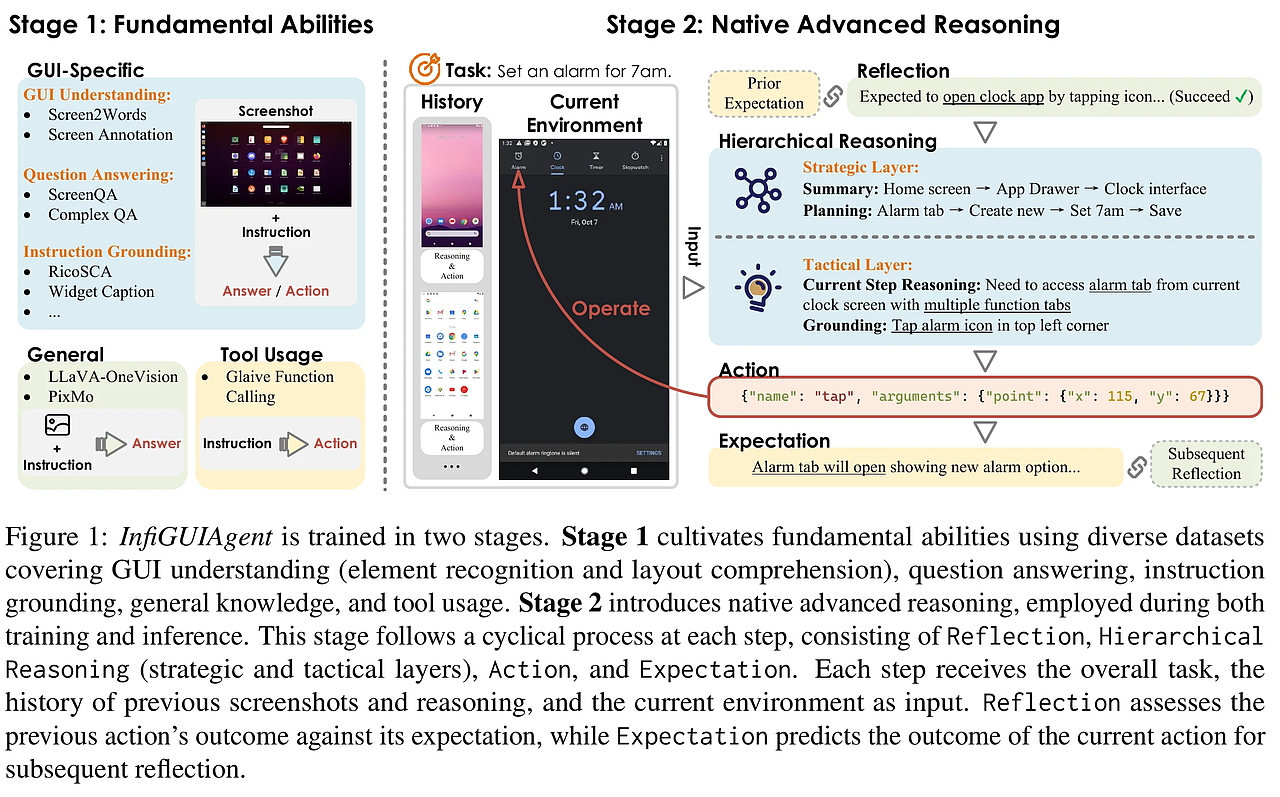
InfiGUIAgent:A Multimodal Generalist GUI Agent with Native Reasoning and Reflection
InfiGUIAgent: A Multimodal Generalist GUI Agent with Native Reasoning and Reflection 2025-01-08|ZJU, DLUT, Reallm Labs, ByteDance Inc, PolyU| 15 http://arxiv.org/abs/2501.04575v1 https://huggingface.co/papers/2501.04575 https://github.com/Reallm-Labs/InfiGUIAgent 研究背景与意义 在当今数字化时代,图形用户界面(GUI)智能体的应用愈发广泛,成为自动化任务的重要工具。现有的多模态大语言模型(MLLMs)为GUI智能体的智能化提供了基础,但其在多步骤推理和对文本注释的依赖上仍存在显著局限。本研究提出的InfiGUIAgent旨在解决这些挑战,强调了原生推理能力在提升GUI交互效率中的重要性,为自动化任务的执行提供了新的可能性。 当前挑战:现有的MLLM基础的GUI智能体在处理复杂操作时,往往受限于单步推理能力,无法有效利...
评论




