揭秘RLVR的真相:强化学习真的能提升大语言模型的推理能力吗?
揭秘RLVR的真相:强化学习真的能提升大语言模型的推理能力吗?
近年来,大型语言模型(LLM)在数学和编程任务中的推理能力取得了显著突破,而**基于可验证奖励的强化学习(RLVR:Reinforcement Learning with Verifiable Rewards)**被认为是这一进步的核心驱动力。RLVR通过自动计算奖励(如数学答案的正确性或代码的单元测试通过率),绕过了传统依赖人工标注的监督学习方法,被认为能够激励模型自我进化,甚至超越基础模型的推理能力边界。
然而,这篇由清华大学LeapLab团队领衔的研究却提出了一个颠覆性的问题:**RLVR真的能让模型学会全新的推理能力吗?还是仅仅在优化已有能力的采样效率?**通过大规模的实验和分析,研究团队发现,RLVR并未真正扩展模型的推理边界,反而可能限制其探索潜力。这一发现不仅挑战了当前对RLVR的主流认知,也为未来LLM的训练范式提供了新的思考方向。
论文地址:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
1. 研究背景与核心问题
1.1 RLVR的兴起与争议
RLVR的核心思想是通过强化学习优化模型,使其输出更可能通过验证的答案。例如,在数学任务中,模型生成的答案若与标准答案一致,则获得奖励;在编程任务中,代码通过单元测试即可得分。这种方法因其可扩展性和自动化优势备受推崇,甚至被认为是实现LLM自我持续改进的关键。
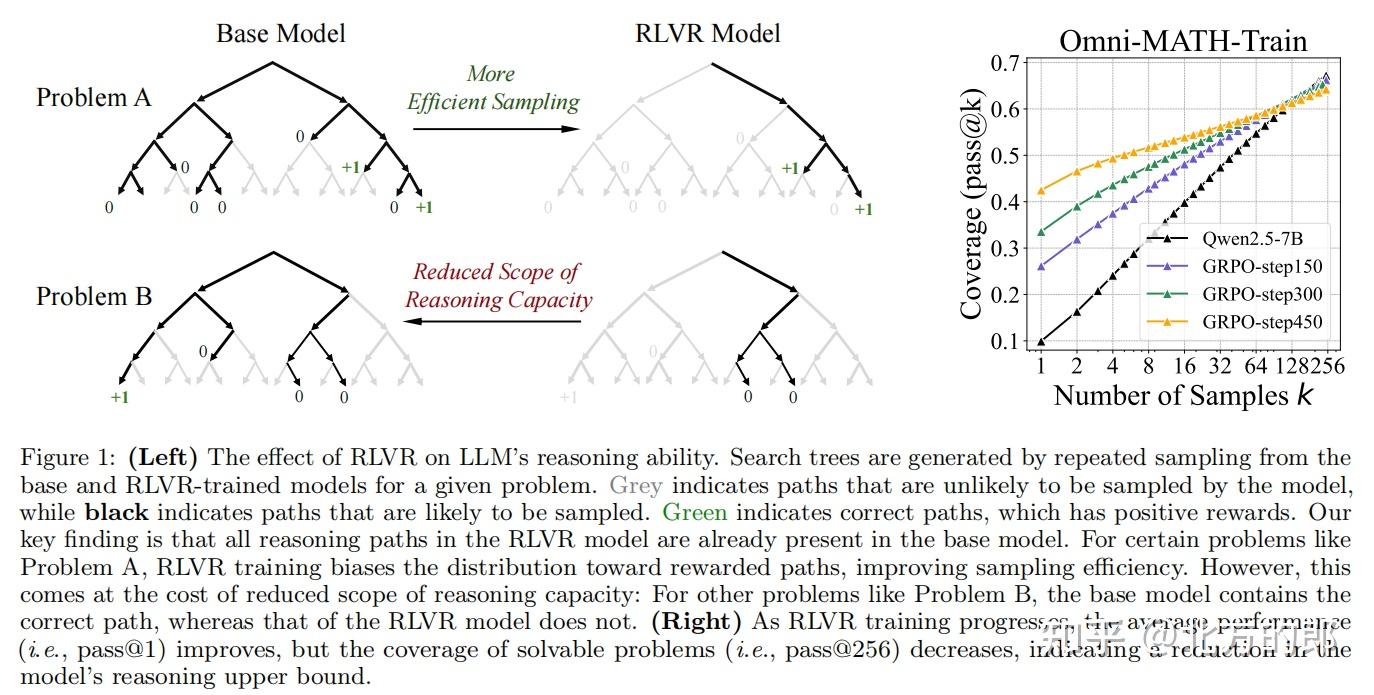
然而,研究团队指出,此前的研究多关注小规模采样(如pass@1)的性能提升,而忽略了模型在大规模采样(如pass@256)下的表现。如果RLVR真的赋予了模型全新的推理能力,那么即使在大量采样中,RL模型也应显著优于基础模型。但事实是否如此?
1.2 核心问题与研究方法
为了验证RLVR的真实效果,研究团队设计了以下实验框架:
- 评估指标:采用**pass@k**(即模型在k次采样中至少一次生成正确答案的概率)来衡量模型的推理边界。
- 实验范围:覆盖数学、代码生成和视觉推理三大任务,涉及多种模型家族(如Qwen-2.5、LLaMA-3.1)和RL算法(如PPO、GRPO)。
- 对比分析:不仅比较RL模型与基础模型的表现,还引入**知识蒸馏模型**作为对照,以区分“采样效率提升”和“能力边界扩展”。
2. RLVR对推理能力边界的实际影响
2.1 数学推理任务
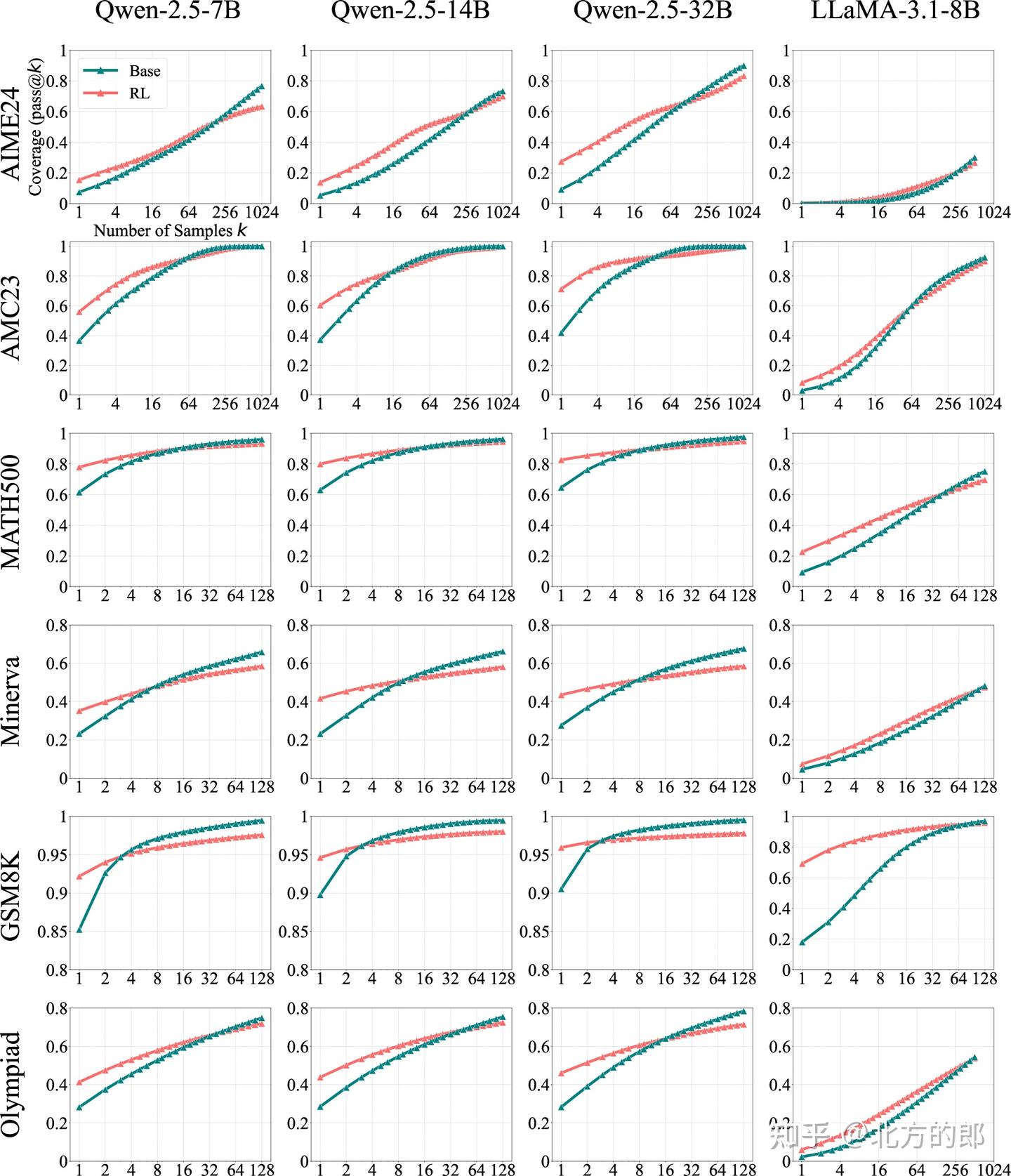
Figure 2: Pass@k curves of base models and their zero-RL-trained counterparts across multiple mathematical benchmarks. When k is small, RL-trained models outperform their base versions. However, as k increases to the tens or hundreds, base models consistently catch up with RL
实验设置
- 模型与基准:使用Qwen-2.5(7B/14B/32B)和LLaMA-3.1-8B,在GSM8K、MATH500、AIME24等数学基准上测试。
- RL训练:采用SimpleRLZoo框架,基于GRPO算法优化模型。
关键发现
- 小k值(如pass@1):RL模型表现优于基础模型,例如在GSM8K上,RL模型的pass@1为28.1%,而基础模型仅为23.8%。
- 大k值(如pass@256):基础模型反超RL模型。例如,在Minerva基准上,32B基础模型的pass@256比RL模型高9%。
- 案例验证:手动检查AIME24中最难问题的推理路径,发现基础模型在2048次采样中仍能生成正确答案,且其推理链逻辑正确。
结论
RLVR并未引入新的推理能力,而是通过偏向高奖励路径提升采样效率,但代价是缩小了模型的推理覆盖范围。
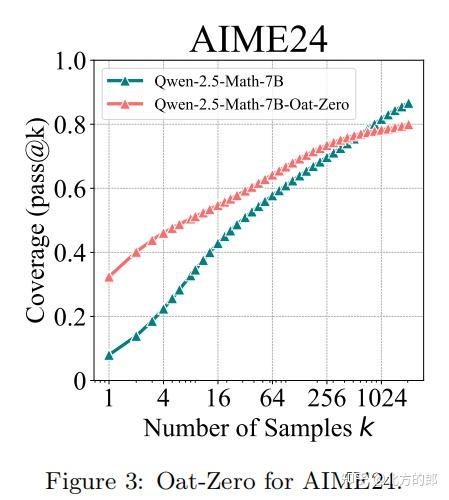
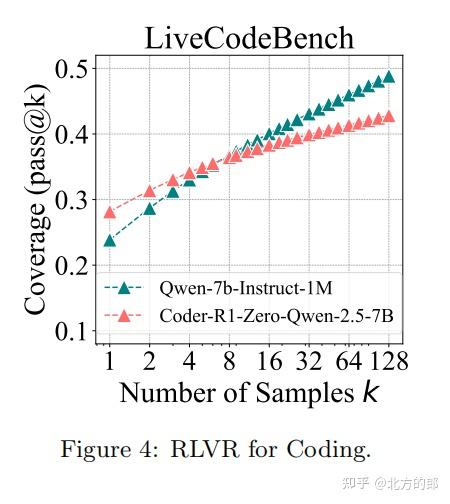
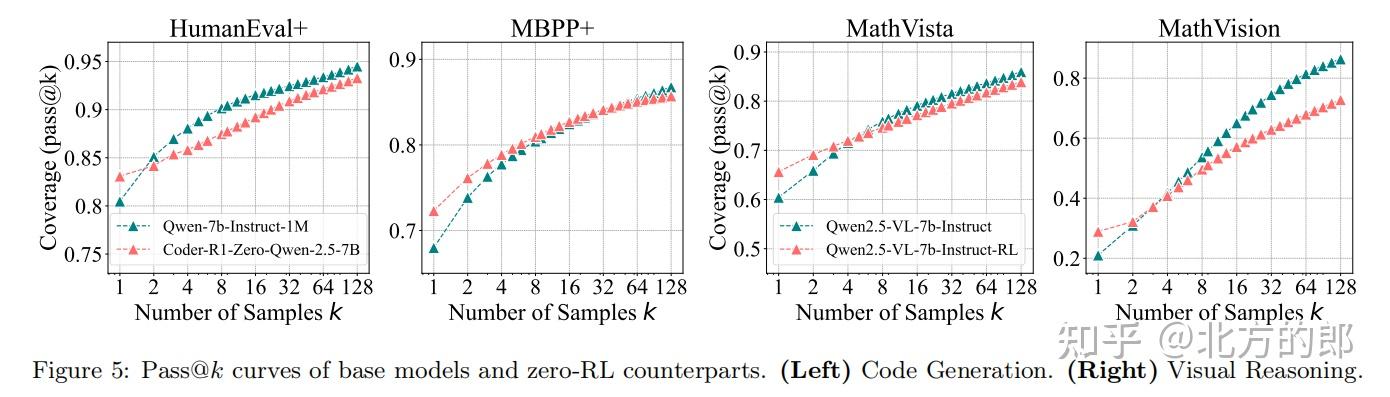
2.2 代码生成任务
实验设置
- 模型与基准:基于Qwen-2.5-7B-Instruct,在LiveCodeBench和HumanEval+上测试。
- RL训练:采用Code-R1框架,通过编译器验证代码正确性。
关键发现
- pass@1:RL模型(28.1%)优于基础模型(23.8%)。
- pass@128:基础模型解决50%的问题,而RL模型仅解决42.8%。
- 趋势分析:基础模型的pass@k曲线斜率更大,表明其潜力未被充分挖掘。
2.3 视觉推理任务
实验设置
- 模型与基准:使用Qwen-2.5-VL-7B,在MathVista和MathVision上测试。
- RL训练:采用EasyR1框架,优化多模态推理能力。
关键发现
- 与数学和代码任务一致,基础模型在大k值下表现更优。
- 手动验证表明,性能提升源于有效推理路径而非随机猜测。
3. 深度分析:RLVR为何无法突破能力边界?
3.1 基础模型已包含RL模型的推理路径
通过困惑度分析,研究团队发现:
- RL模型生成的答案在基础模型的输出分布中已存在,且概率不低。
- RL的作用仅是提高高奖励路径的采样概率,而非创造新路径。
3.2 知识蒸馏的对比实验
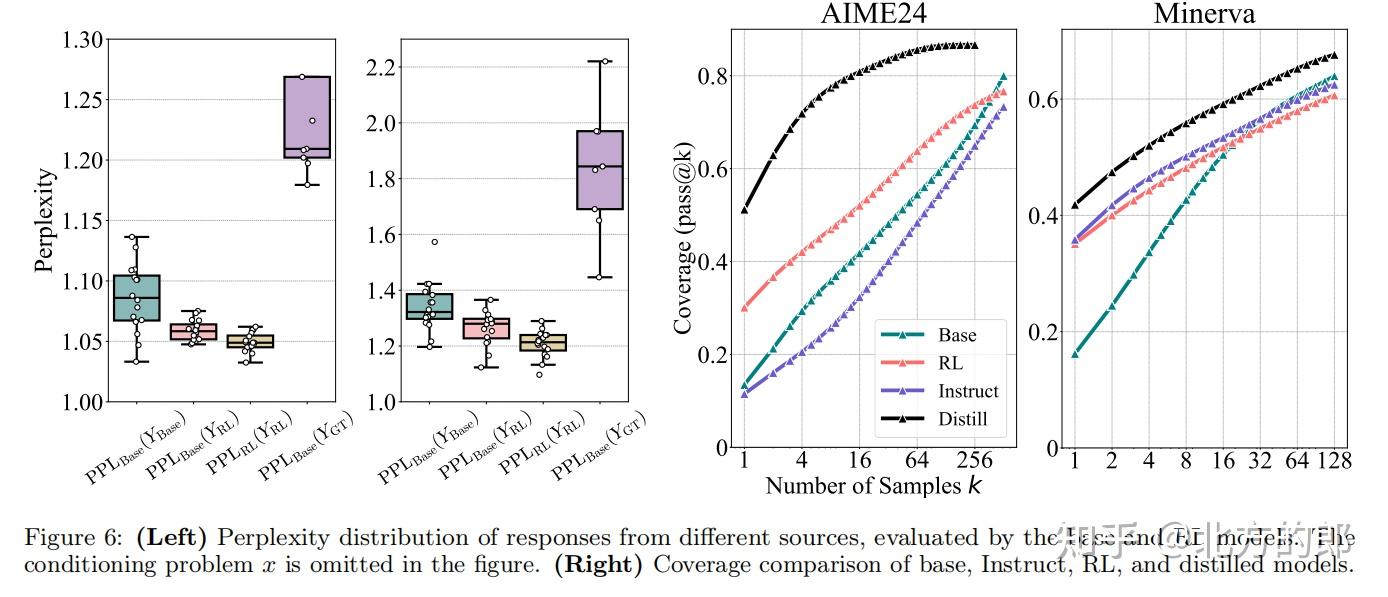
与RLVR不同,蒸馏模型(如DeepSeek-R1-Distill-Qwen-7B)能够真正扩展推理边界。例如,在MATH500上,蒸馏模型的pass@k曲线始终高于基础模型和RL模型。
3.3 不同RL算法的局限性
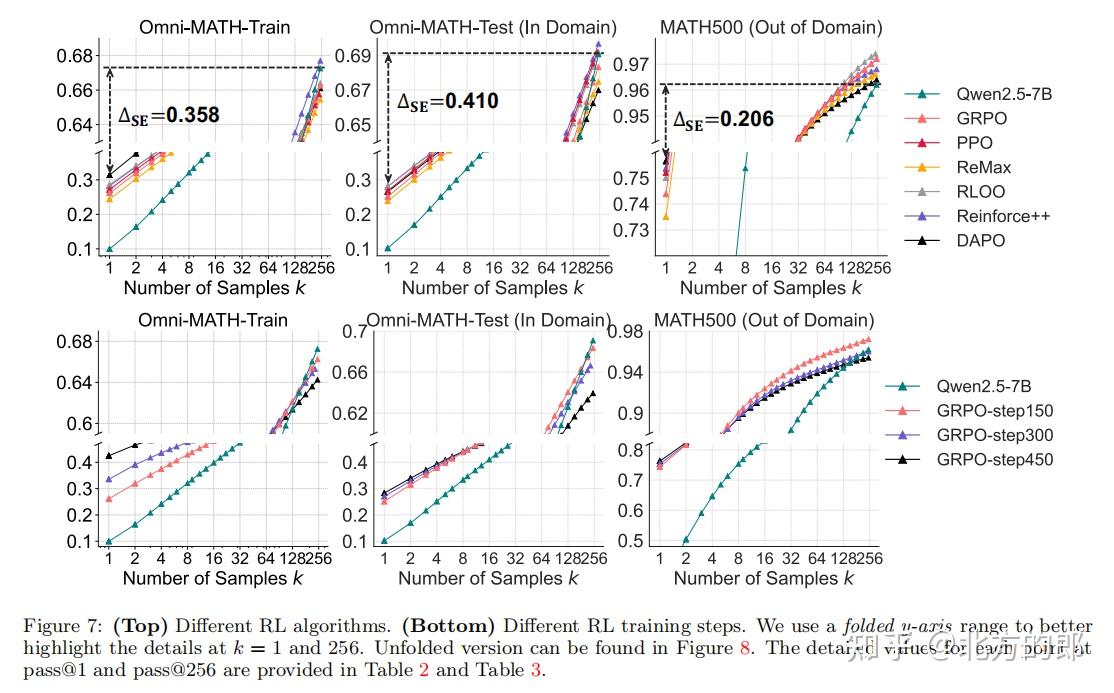
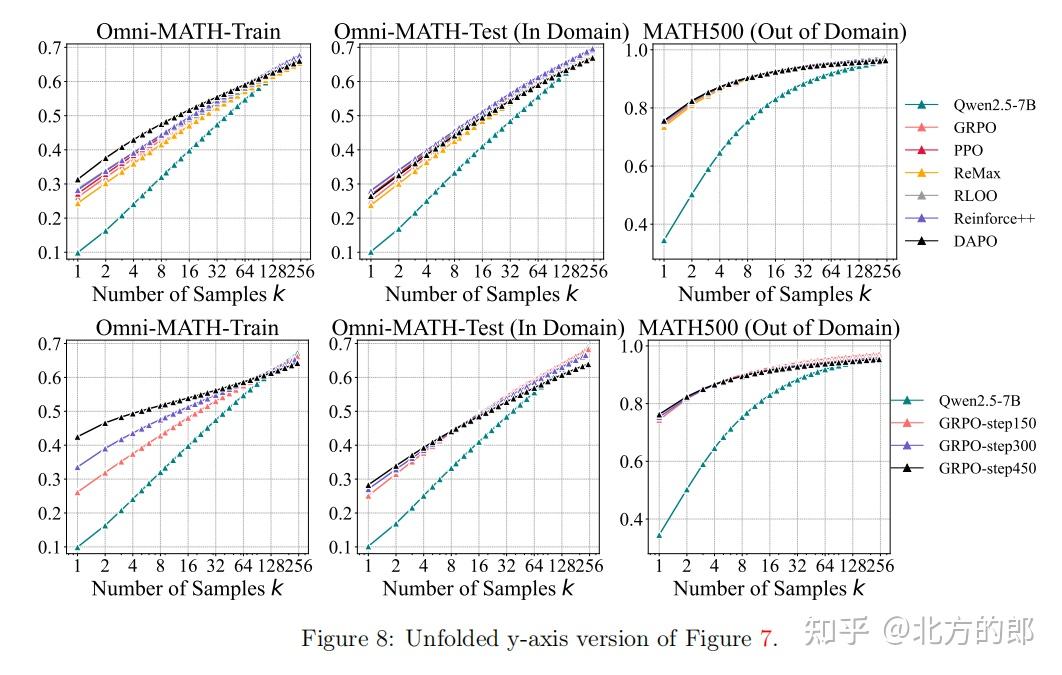
研究团队测试了PPO、GRPO、Reinforce++等算法,发现:
- 采样效率差距(ΔSE):所有算法的ΔSE均高于40,表明当前RL方法远未达到最优采样效率。
- 训练步数的影响:随着训练步数增加,pass@1提升但pass@256下降,进一步证实RLVR会限制探索能力。
4. 讨论与未来方向
4.1 传统RL与RLVR的关键差异
- 动作空间巨大:语言模型的输出空间远大于围棋或Atari游戏,RL算法难以有效探索。
- 预训练先验的双刃剑:基础模型的先验虽加速训练,但也限制了RL探索新路径的能力。
4.2 未来改进方向
- 探索超越先验的方法:如结合蒙特卡洛树搜索(MCTS)或分层强化学习。
- 混合训练范式:将蒸馏与RL结合,兼顾能力扩展与采样效率。
5. 结论:RLVR的局限与启示
实验结论总结:
1 经过强化学习(RL)训练的模型在大规模采样(pass@k)时表现反而不如基础模型。
虽然RL模型在小规模采样(如pass@1)时优于基础模型,但随着采样次数k的增加,基础模型的表现持续反超。人工检查发现,基础模型能生成多样化的推理路径,即使对于被认为需要RL训练才能解决的任务,也往往能产生至少一个正确答案。
2 强化学习提升了采样效率,但缩小了推理能力边界。
RLVR训练的模型仅能生成基础模型中已有的推理路径。这种训练方式使模型偏向于曾经获得过奖励的解法,牺牲了探索能力。RLVR并未扩展模型的问题解决潜力——它只是优化了已有的能力。
3 不同RL算法表现相近,且均远未达到最优水平。
对比PPO、GRPO和Reinforce++等算法发现,它们之间的差异微乎其微。采样效率差距(∆SE)始终显著存在,表明当前所有RL方法都远未达到最优性能。
4 RLVR与知识蒸馏存在本质区别。
RLVR仅能优化采样效率,而蒸馏可以引入全新知识。经过蒸馏的模型往往能突破原有推理能力边界,这与受限于基础模型能力的RLVR模型形成鲜明对比。
这项研究揭示了RLVR的本质局限:它无法让模型超越基础能力边界,仅能优化已有能力的采样效率。这一发现呼吁社区重新思考RL在LLM训练中的角色,并探索更有效的自我改进范式。
附录,实验Prompt等





总结:
《Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?》,该研究由清华大学LeapLab团队领衔,对当前大模型领域广泛使用的“基于可验证奖励的强化学习”(RLVR)技术提出了颠覆性的质疑。其核心结论可以总结如下:
🧪 核心发现:RLVR并未扩展模型的推理能力边界
文章通过在数学、代码生成和视觉推理三大任务上的大规模实验,得出一个与主流认知相反的结论:RLVR(Reinforcement Learning with Verifiable Rewards)并不能让大模型学会全新的推理能力,反而可能限制其探索潜力。
具体结论分为四点:
-
基础模型已包含“高能力”:
实验发现,经过RLVR训练的模型所生成的正确答案和推理路径,在原始的基础模型(Base Model)中已经存在。RLVR的作用并非“创造”新知识或新解法,而是通过奖励机制,提高了这些已有高奖励路径在小规模采样(如pass@1)时被选中的概率。 -
RLVR提升采样效率,但牺牲探索广度:
RLVR的本质是优化了已有能力的“采样效率”(Sampling Efficiency)。它让模型在少量尝试(如一次生成)中更容易输出正确答案。然而,这种优化的代价是缩小了模型的推理覆盖范围。模型变得“偏科”,过度依赖曾经获得奖励的解法,从而抑制了对其他潜在正确路径的探索。 -
大规模采样下,基础模型反超RL模型:
当使用大量采样(如pass@256)时,原始的基础模型表现反而优于经过RLVR训练的模型。这是因为基础模型的输出分布更“发散”,能探索到更多样化的解法。随着采样次数增加,它最终会“找到”正确的答案,而RL模型则因探索范围受限,提升空间更小。 -
RLVR与知识蒸馏有本质区别:
研究对比了知识蒸馏(Knowledge Distillation)方法。与RLVR不同,蒸馏模型(如将更大模型的知识迁移到小模型)能够真正扩展模型的推理能力边界,其在pass@k曲线上的表现始终优于基础模型和RL模型。这说明,只有引入新的知识或能力,才能突破边界,而RLVR做不到这一点。
🔍 启示与未来方向
- 重新审视RLVR的作用:RLVR并非“点石成金”的魔法,它更像是一个“放大器”,放大的是基础模型中已有的能力,而非创造新能力。
- 警惕过度依赖RL:当前社区过度关注pass@1等小样本指标,可能掩盖了模型探索能力下降的问题。
- 探索新范式:未来应探索能真正突破能力边界的训练方法,例如结合蒙特卡洛树搜索(MCTS)、分层强化学习,或将知识蒸馏与RL结合的混合训练范式。
总而言之,这篇文章揭示了RLVR的“双刃剑”本质:它在提升模型“单次输出成功率”的同时,也“修剪”了模型原本丰富的可能性。模型的“上限”并未提高,只是“平均表现”在特定场景下被优化了。