大模型混合并行DP/TP/PP,如何划分机器?
大模型混合并行DP/TP/PP,如何划分机器?
1 DP/TP/PP的通信量比较
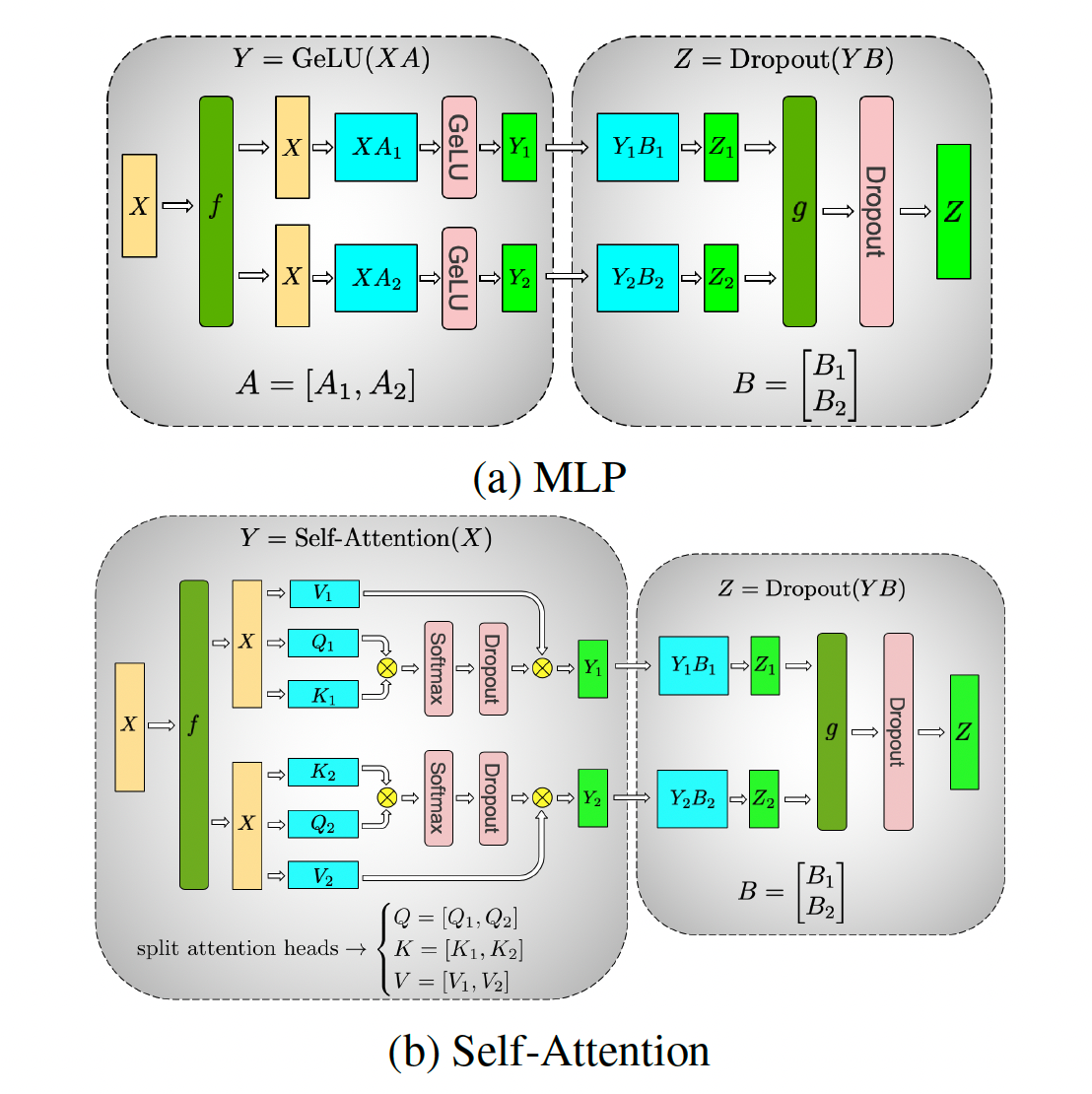
在大规模深度学习模型的训练过程中,为了加速训练和减少单个计算节点的压力,通常会使用分布式训练技术。分布式训练涉及到几种并行策略,其中最常提到的是数据并行(Data Parallelism, DP)、模型并行(Model Parallelism, MP)和流水线并行(Pipeline Parallelism, PP)。另外,模型并行中还有一种称为张量并行(Tensor Parallelism, TP)的方式,它是指将模型的张量(如权重矩阵)分割到不同的设备上进行计算。
- 数据并行(DP):解决计算墙的问题。每个设备上都会有一个模型的完整副本,每个设备独立地处理一部分数据集,然后将各自的梯度汇总起来(通常是通过AllReduce操作)。因此,DP的通信主要发生在训练的每个epoch结束时,各个设备之间需要交换梯度信息。这种通信通常量较大,因为它涉及到模型所有参数的同步。
- 张量并行(TP):解决内存墙的问题。模型的权重矩阵被分割成多个部分,每个部分由不同的设备负责计算。TP的通信主要发生在前向和后向传播过程中,设备之间需要交换分割后的中间结果。由于需要在每次前向和后向传播时进行通信,TP的通信量也相当大。需要进行concat操作。
- 流水线并行(PP):解决内存墙的问题模型的不同层被分配到不同的设备上,设备之间按照顺序传递激活和梯度。PP的通信量相对较小,因为它只需要在相邻的设备之间传递数据(前一层的输出是后一层的输入),而不是在整个集群中广播。但是,PP引入了额外的复杂性,尤其是在处理依赖关系和同步方面。
一般来说,通信量的大小排序大致如下:
- TP > DP > PP
这是因为TP需要频繁地在每次迭代中交换分割后的张量,而DP则是在每个epoch结束时进行一次较大的通信。PP的通信相对较少,但它需要更精细的调度和同步机制来保证正确的计算顺序。
在实际应用中,通常会混合使用这些并行策略来达到最优的性能。例如,可以在一个节点内部使用TP来分割模型,而在多个节点之间使用DP来加速训练。此外,还可以在TP的基础上加入PP来进一步分解模型的复杂度。选择哪种组合取决于具体的模型大小、硬件配置以及训练数据集等因素。
2 切分示例
假设我们有2台机器(node0和node1),每台机器上有8块GPU,GPU的编号为0~15。
我们使用这16块GPU,做DP/TP/PP混合并行,如下图:

DP/TP/PP混合并行切分
- MP:模型并行组(Model Parallism)。假设一个完整的模型需要布在8块GPU上,则如图所示,我们共布了2个model replica(2个MP)。MP组为:
[[g0, g1, g4, g5, g8, g9, g12, g13], [g2, g3, g6, g7, g10, g11, g14, g15]]。 MP包含TP和PP。 - TP:张量并行组(Tensor Parallism)。对于一个模型的每一层,我们将其参数纵向切开,分别置于不同的GPU上,则图中一共有8个TP组。TP组为:
[[g0, g1], [g4, g5],[g8, g9], [g12, g13], [g2, g3], [g6, g7], [g10, g11], [g14, g15]]。 - PP:流水线并行组(Pipeline Parallism)。对于一个模型,我们将其每一层都放置于不同的GPU上,则图中一共有4个PP组。PP组为:
[[g0, g4, g8, g12], [g1, g5, g9, g13], [g2, g6, g10, g14], [g3, g7, g11, g15]] - DP:数据并行组(Data Parallism)。经过上述切割,对维护有相同模型部分的GPU,就可以做数据并行,则图中共有8个DP组。DP组为
[[g0, g2], [g1, g3], [g4, g6], [g5, g7], [g8, g10], [g9, g11], [g12, g14], [g13, g15]]
明确了分组设计,我们再来看下面几个问题。
(1)分组的原则是什么?
- **MP设定原则:**MP其实由TP+PP共同决定。在开始训练前,需要我们根据实际模型,预估训练时显存消耗(特别注意峰值显存),来为模型安排GPU资源。
- TP、DP和PP设定原则:在这三种并行模式的原理篇中,我们分析过三者的通讯量。一般而言,TP>DP>PP。通讯量大的尽量放入一台机器内,因为机器内带宽高。所以在图例中,TP和DP不跨机,PP跨机。再提一点,在使用Megatron时,很多项目是不用PP,仅用TP+DP的,此时一般将TP放入一台机器内,令DP跨机(比如codegeex)
(2)分组的目的是什么?
- 分配进程:
- 确认分组方案后,在每块GPU上启动一个进程(process),每个进程独立执行自己所维护的那部分模型的计算,实现并行训练。
- 进程0~15,为一个进程大组(group),其下的每一个DP/MP/PP组,为一个进程子组(subgroup)
- **组间通讯:**确认好DP/TP/PP组,并分配好进程后,我们就能进一步设置不同进程间的通讯方案。例如属于一个DP组的g0和g2需要进行梯度通讯,属于一个PP组的g4和g8需要进行层间输出结果的通讯。
总结来说,初始化Megatron做了如下事:
- 定义模型的切割框架
- 在此框架上,初始化进程,分配GPU,设置进程组(DP/TP/PP)
TP_size : number of GPUs used to parallelize model tensor.
PP_size : number of GPUs used to parallelize model pipeline.
world_size : All gpu numbers
一般情况下,根据TP+PP就可确认MP,进而推出DP。也就是定好了TP和PP,DP_size就能根据 world_size // (TP_size * PP_size)计算得出。
参考:
 猛猿:图解大模型系列之:Megatron源码解读1,分布式环境初始化614 赞同 · 68 评论
猛猿:图解大模型系列之:Megatron源码解读1,分布式环境初始化614 赞同 · 68 评论