UloRL:An Ultra-Long Output Reinforcement Learning Approach for Advancing Large Language Models’ Reasoning Abilities
UloRL:An Ultra-Long Output Reinforcement Learning Approach for Advancing Large Language Models’ Reasoning Abilities
论文链接:https://arxiv.org/pdf/2507.19766
转自:https://zhuanlan.zhihu.com/p/1932380821412638989
得益于Test-time Scaling的成功,大模型的推理能力取得了突破性的进展。为了探索Test-time Scaling的上限,我们尝试通过强化学习来扩展模型输出长度,以提升模型的推理能力。然而,强化学习在处理超长输出时面临两个问题:1) 由于输出长度的长尾分布问题,整体的训练效率低下;2) 超长序列的训练过程中会面临熵崩塌问题。为应对这些挑战,我们对GRPO做了一系列优化,提出了一个名为UloRL的强化学习算法。在Qwen3-30B-A3B的实验表明,通过我们的方法进行强化训练,模型在AIME-2025上由70.9提升到85.1,在BeyondAIME上由50.7提升到61.9。
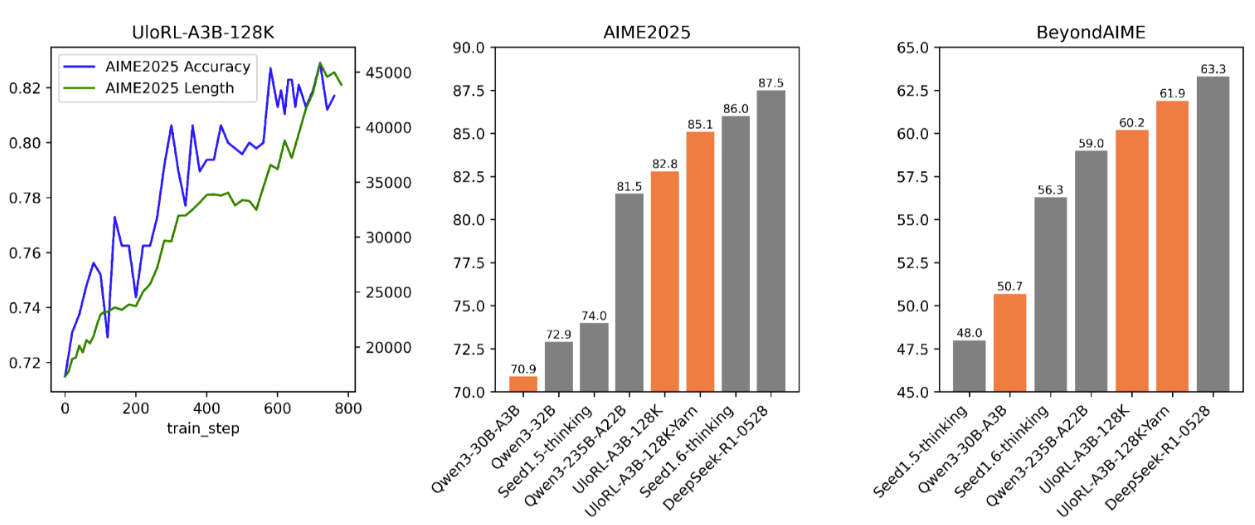
UloRL在Qwen3-30B-A3B 128k长度RL实验效果
1. 提升训练效率:基于分段解码的强化训练
在传统RL框架中,只有batch内所有数据采样结束才能进入训练环节。在超长输出的场景下,比如128k,由于长尾效应,一个batch内可能80%的数据长度都在64k之内,但所有样本都要等待最长的128k输出结束才能进入经验池等待训练,大大降低了训练速度和资源利用率。我们采用分段解码的方式来应对这一挑战,整体思路是把一次超长序列的解码拆分成多个解码阶段。每次只解码一个segment的长度;正常结束的样本加入经验池进行训练,没有结束的样本在下一次迭代中拼接上一轮的结果继续解码。
1.1 分段解码

分段解码训练伪代码
上面的伪代码展示了带有分段解码的强化训练整体过程。从第8行可以看到,每轮解码的输入有两个来源:1) 前一轮解码没有结束的样本; 2) 强化训练集中的新prompt。每次解码的终止条件有三种情况:
○ 遇到结束符:这种情况表示样本解码完成,进入经验池等待训练
○ 达到段最大长度但未到全局最大长度:这种情况表明当前样本解码尚未结束,进入未完成序列等下一轮继续解码
○ 达到全局最大长度:这种情况表示当前序列超长截断,进入经验池等待训练
假设全局最大输出长度为128k,最多分为8段解码,那么模型每次只需要解码128k/8=16k就可以更新一次模型。这样可以避免因为等待少量特别长样本解码而阻塞整体训练,大大提升了训练速度和资源利用率。我们在Qwen3-30B-A3B上进行了64k输出训练的实验,下表展示了设置不同分段数对训练速度的影响。可以看到,当分段数为4时,相比不分段模型训练速度可以提升2.06倍。
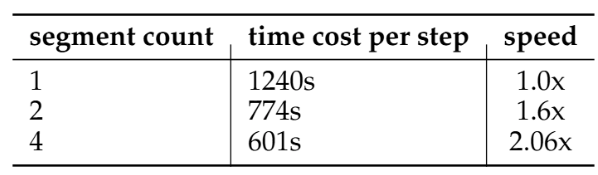
不同分段数对训练速度的影响
1.2 训练策略
首先回忆一下GRPO的训练目标:

在原始的GRPO中,经验池中的一条样本由单一时刻的模型生成。但在分段解码的情况下,如下图(a)所示,经验池中的一条样本可能由不同时刻的多个模型产生片段拼接而成,因此重要性采样 中的 需要进行修正。针对分段解码,我们提出两种针对重要性采样的计算方法。

1) Segment Aware Importance Sampling (SAIS)
由于每条样本中的不同段落可能由多个不同时刻的模型产生,因此不同segment对应的 不同(如上图(b)所示)。不失一般性,设t是当前时刻,我们记t时刻模型生成的片段为seg_t, 则一条完整的采样样本s可以表示为s=[seg_1,seg_2,…,seg_t],那么s中的第i个token对应的重要性采样计算公式如下:
其中f是一个token序号到段序号的映射函数。
2) Pseudo On-policy Importance Sampling (POIS)
近期的多项研究表明on-policy训练相比off-policy模型的熵更稳定,效果更好。这主要是因为在off-policy下偏离当前policy太远的token会被目标函数中的clip操作裁剪掉,导致模型多样性受损。但在on-policy下,所有token均由当前模型生成,因此所有token的重要性采样都为1,不会有token被裁剪,模型训练时可以见到更多样的数据。为了利用on-policy的这个优势,我们尝试将segment rollout改造为on-policy训练。
如上图©所示,t时刻是最新时刻,因此t时刻产生的片段是on-policy数据,但1 ~ t-1时刻产生的数据是off-policy数据。为了实现on-policy训练,我们简单地将所有时刻对应的 都替换为最后一个时刻的 ,此时所有token的重要性采样都为1。在这种方法中,经验池中片段为1的样本都是真实的on-policy样本;片段>1的样本,最后一个segment是真实的on-policy样本,其他segment是伪on-policy (pseudo on-policy)样本。因此我们称这种方法为pseudo on-policy importance sampling.
对比实验
为了对比上述两种方法的效果,我们在Qwen3-30B-A3B上进行了一系列的实验,实验分三组:
- TOIS:解码不分段,此时是真实On-policy训练(True On Policy Importance Sampling)
- SAIS: Segment Aware Importance Sampling, 分4段解码
- POIS:Pseudo On-policy Importance Sampling, 分4段解码
我们分别设置全局长度为4k,32k和64k进行强化训练,下图展示了训练过程中模型熵和评测集指标的变化。
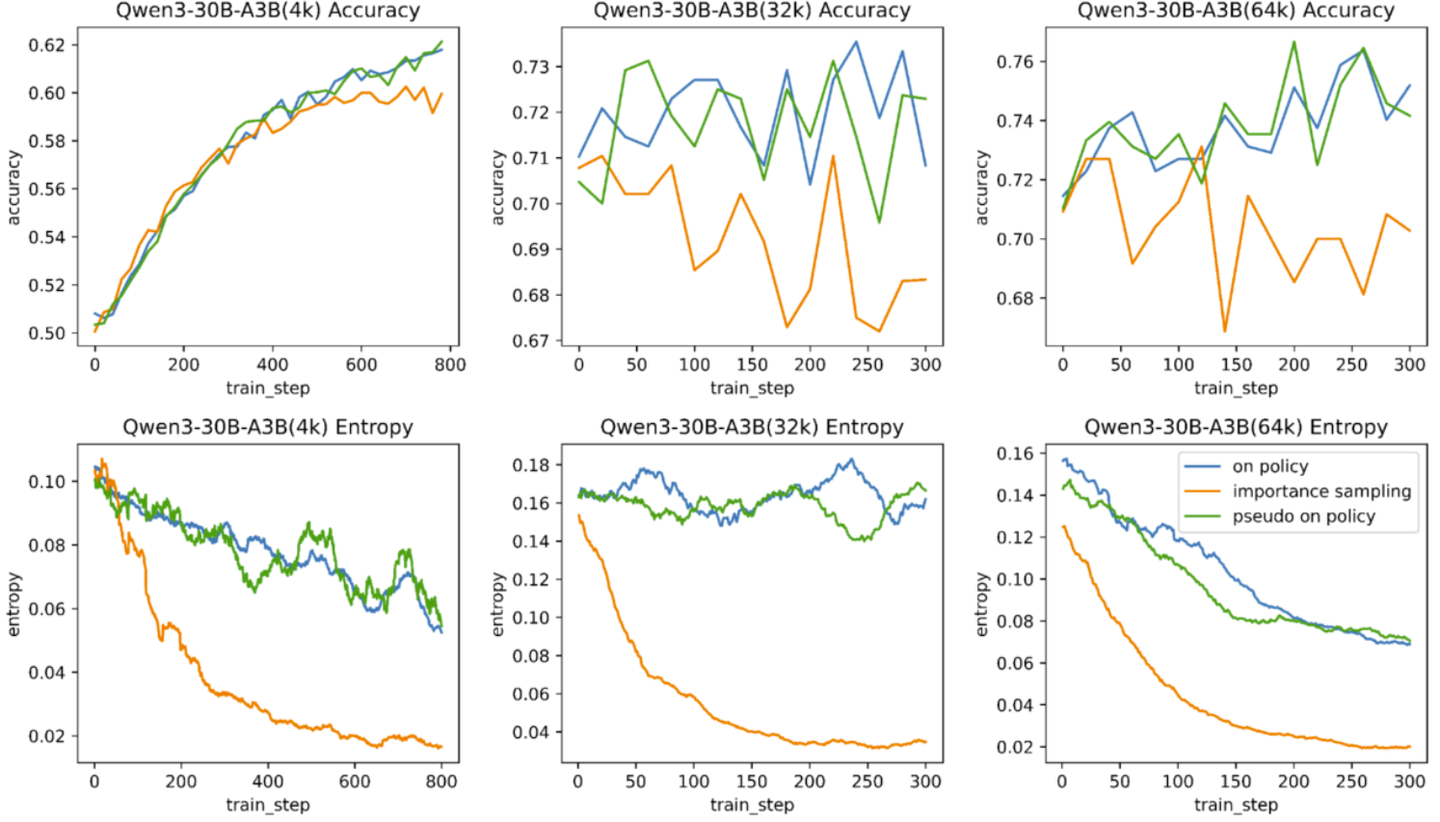
可以看到,在不同模型尺寸下,POIS和TOIS的曲线基本重合。这个结果很出乎我们的预料,我们猜测可能是因为在多段解码的条件下,每条样本至少有一个段落(最后一段)是真实的on-policy数据,这可能降低了伪on-policy数据对模型的负面影响。后续的实验我们都采用POIS方法。
2. 阻止熵坍塌:动态屏蔽已掌握Token的训练
强化学习训练成功的关键因素是保持模型在训练过程中能够持续地维持利用和探索的均衡。利用是指模型能够采样到高质量的解题路径去监督模型的优化,可以通过采样样本的正确率来反应利用的好坏;探索则是指模型能够采样出和已有路径不同的解题思路从而不断提升模型的解题能力,一般用模型的熵来反映其多样性。成功的强化学习需要兼顾二者,模型能不断采样到高质量且多样化的解题路径。
然而,在强化学习的实际训练中,熵过早的坍塌是最常见的挑战。现有研究中,对这一问题的解决方法主要分为两类。一类是直接在loss中引入熵loss,将熵也作为模型优化的目标之一。由于熵的目标和我们最终的学习目标并不一致,因此这种方法可能对模型的能力上限有损。另一类方法是调整参与训练的样本或token。例如DAPO提出提高clip的上限值从而允许和当前分布差异更大的token参与到训练中来,但这种方式只在off-policy的训练中有效,on-policy的训练没有clip这一项因此无法适用。
2.1 为什么会熵坍塌
我们认为对正样本中模型已掌握的token过度训练是导致熵坍塌的根本原因。其中“正样本”指reward为1的样本,"模型已掌握"的token是指模型本来已经可以有很高的置信度正确预测的token。我们称这类token为well-Mastered Positive Tokens (MPTs). 如下图所示,模型对已掌握token进行过度更新,会进一步增大被选中token的生成概率,从而导致分布更加尖锐,导致熵降低。
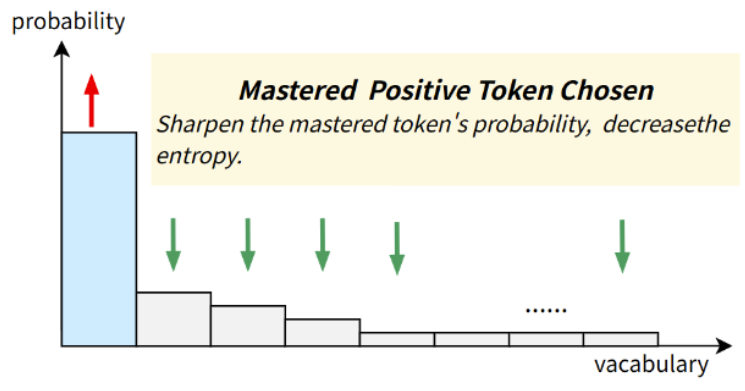
为了验证上述猜想,我们做了一系列实验。实验配置如下:
Baseline:对全量token进行训练
Masking MPTs:训练时屏蔽MPTs,只训练其它token
我们在qwen3-4B/qwen3-8B/qwen3-30B-A3B上进行了实验,训练长度128k分8段,每段16k。下图展示了训练过程中熵的变化:
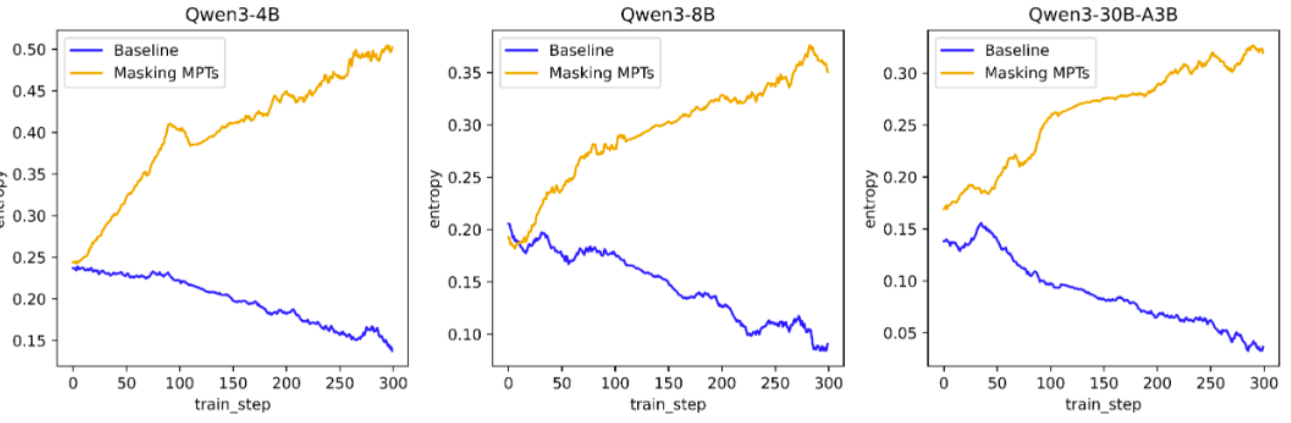
可以看到,三个尺寸的模型,Baseline随着训练的进行熵持续走低。当屏蔽掉MPTs的训练后,熵则持续走高。这一现象验证了我们上述猜想。
2.2 动态屏蔽MPTs
从上图可以看到,仅屏蔽MPTs的训练会导致熵持续走高,这样同样不利于强化学习的稳定训练。理想情况下,训练过程中模型的熵应该维持在一个合适的熵附近。为了实现这一目标,我们提出了一种名为动态屏蔽MPTs的方法(DMMPTs)。具体的,我们引入一个新的超参数 用于表示目标熵,在训练过程中,只有当前熵小于目标熵时才屏蔽MPTs的训练:
其中V是词表。在我们的方法中,如果当前模型在样本o上的熵(计算方式参见上述公式中的H)小于目标熵,则屏蔽MPTs的训练,于是预期熵会升高;反之,如果模型在样本o上的熵大于目标熵,则不屏蔽MPTs,预期熵会回落。在我们的算法中,没有引入额外的优化目标,只对MPTs的训练进行屏蔽,这部分token模型本来就有很高的概率可以输出,因此屏蔽这部分token的训练不会降低模型的性能。
为了验证上述方法是否能达到预期目标,我们在qwen3-4B/qwen3-8B/qwen3-30B-A3B上进行了实验,下图展示了实验结果:
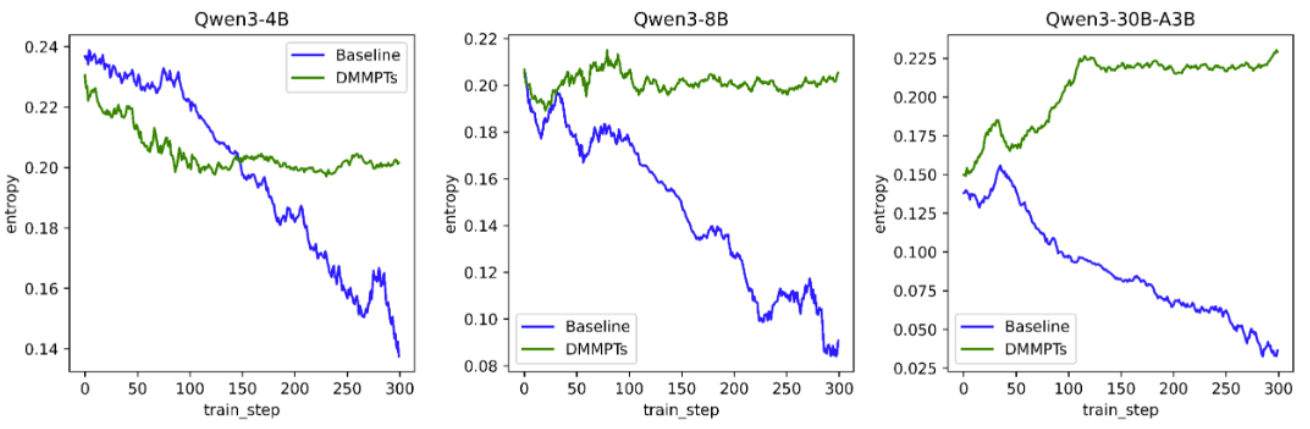
可以看到,加入动态屏蔽MPTs策略后,三个不同尺寸模型的熵都能稳定在预设范围附近,证明了上述方法的有效性。
3. 提升Reward质量:生成式答案验证模型
基于结果的Reward Model已经被证明对推理类任务RL非常有效。和DAPO类似,我们直接基于最终结果计算reward:
和DAPO不同的是,我们的Reward取值为{0,1}而不是{-1,1}。我们这样设计的好处是数据集的平均Reward刚好是Acc。并且在GRPO的框架下,当group内同时存在正负样本时,正样本对应的样本advantage始终大于0,梯度方向为正;负样本对应的advantage始终小于0,梯度方向为负,符合优化预期。另外,判断(y^, y)是否等价也不是一个简单的任务,纯靠规则很容易误判。例如(27cm, 0.27m)/(1/2, one half)。为了解决这个问题,我们训练了一个生成式模型来判别给定的两个答案是否等价。
4. 高质量训练数据很重要
为了保证Verifier Model输出reward的准确性,我们从问题和参考答案的维度对RL的训练数据进行了一系列的处理:
问题维度
● 过滤一题多问,避免不同子问题的回答总结不全带来的伪负例问题
● 选择题、判断题转简答题,避免模型猜对答案的情况
● 过滤简单题,用Qwen3-30B-A3B对全量训练数据推理8次,若8次全对则认为题目过于简单,从训练集删除
答案维度
● 对参考答案抽取短答案,降低verifier model的判断难度
● 过滤参考答案过长的题,例如答案为矩阵类的题
● 过滤答案错误的题:用多个SOTA模型同时预测同一个题,如果多个SOTA模型输出结果一致,并且和参考答案不同,则认为参考答案有误,删除这样的数据
5. 实验结果
5.1 总体结果
我们基于Qwen3-30B-A3B,按照最大输出长度128k进行强化训练,具体训练参数参见论文原文。下表展示了实验结果:
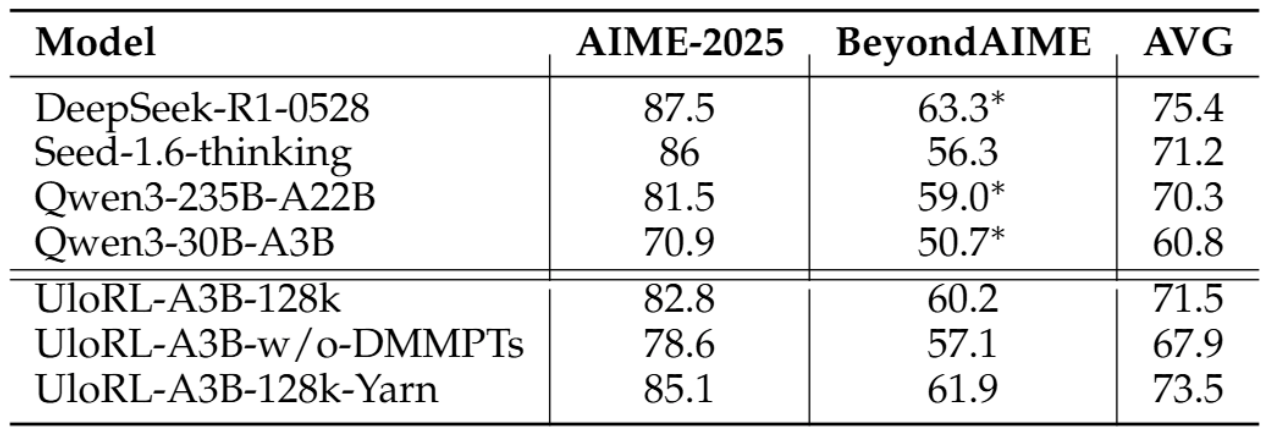
可以看到,经过强化后,UloRL-A3B-128k比Qwen3-30B-A3B在AIME2025上提升11.9个点,在BeyondAIME上提升9.5个点,甚至显著超过了Qwen3-235B-A22B。这个结果充分证明了我们方法的有效性。
另外,去除DMMPTs策略后,UloRL-A3B-w/o-DMMPTs指标显著降低,这证明了我们提出的DMMPTs对强化训练的重要性。另外我们还通过Yarn将输出长度从128k扩展到140k,模型指标取得了进一步提升,说明继续增加长度还可以提升模型的推理能力。
5.2 输出长度对效果的影响
为了验证输出长度对模型效果的影响,我们分别设置最大输出长度为32k,64k, 96k和128k进行强化训练。下表展示了实验结果:
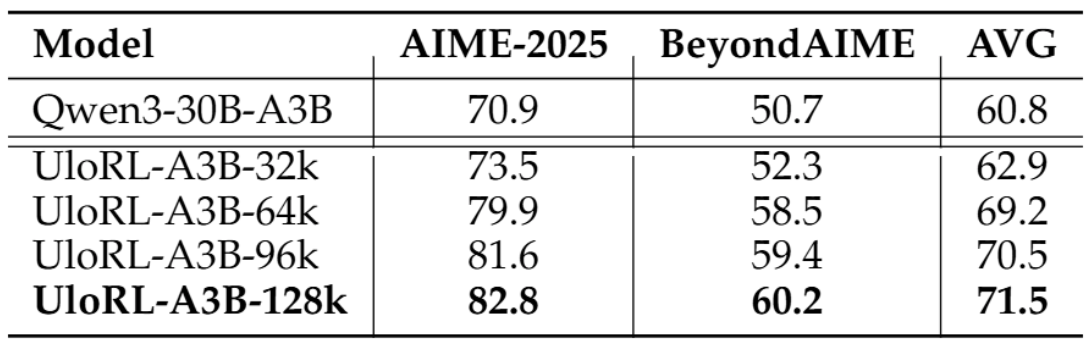
我们可以观察到如下几个现象:
1)当最大长度为32k时,强化带来的提升比较有限。这是因为Qwen3-30B-A3B本来就是一个很强的32k模型,在不扩展长度的情况下,很难大幅提升其推理能力;当最大长度设置为64k时,强化带来了显著的效果提升。
2)总体来看,最大长度越长,模型效果越好,这说明扩展输出长度是提升模型推理能力的有效手段。