Alita:Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution
Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution
参考:https://zhuanlan.zhihu.com/p/1915741399036438446
Alita 提出了一种通过最小预定义实现最大自演化的通用智能体范式,摒弃传统 LLM agent 对手工设计工具和复杂流程的依赖,仅以一个内置 Web Agent 为核心,借助开放网络自主生成、测试并封装可重用的任务工具(MCPs),展现出无需人工干预即可构建复杂推理能力的潜力;在多个高难度基准任务中即便搭配弱模型也能优于现有方法,同时具备高度的工具迁移性与知识蒸馏价值,为智能体系统的可扩展性与共享生态奠定基础。
Introduction
总体背景
近年来,大语言模型(LLMs)已经从单纯的文本生成器迅速演化为可以自主规划和执行复杂任务的智能体。这种转变使得 LLM 驱动的代理系统能够在极少人工监督的情况下完成包括旅行规划、计算机操作、多步研究任务等在内的各类复杂任务。
为了应对这些日益多样化和复杂的应用需求,研究者们提出了一种新型系统范式——通用型智能体(Generalist Agents)。这类智能体以统一架构为基础,旨在跨越多个任务和领域进行泛化操作。典型的通用型智能体包括 OpenAI 的 Deep Research 和 Manus 等。
当前方法的局限性
尽管已有不少通用型代理框架,但它们普遍依赖于大规模的人工工程设计,例如:
- 精细设计的工作流;
- 预定义的大量工具;
- 硬编码组件。
这种设计带来了三个核心问题:
- 覆盖不全(Incomplete Coverage):现实任务种类繁多,很难通过人工手动预定义所有所需工具。
- 创意与灵活性受限(Limited Creativity and Flexibility):许多任务要求代理能够灵活组合新工具或以新方式使用现有工具,而预定义工作流和硬编码会限制这种组合能力。
- 接口不兼容(Mismatch):现实中有许多实用工具不是用 Python 编写,难以与主流以 Python 为基础的代理框架直接连接。
这些问题共同制约了当前通用型代理在可扩展性、适应性和泛化能力方面的进一步提升。
ALITA 的提出与核心理念
为突破上述限制,作者提出了一种极简主义设计哲学(radically simple design philosophy),并据此构建了通用代理系统 Alita。该哲学基于两个核心原则:
- 最小预定义(Minimal Predefinition):仅配置最少核心能力,避免为特定任务或模态手动设计组件。
- 最大自进化(Maximal Self-Evolution):赋予代理系统自主创造、精炼和复用外部能力的能力。
Alita 的核心设计包括:
- 仅一个核心能力模块(Web Agent);
- 一组通用模块(如 MCP 构造组件)用于任务相关功能的自扩展;
- 动态使用 MCP(Model Context Protocol):通过构造任务相关的 MCP,Alita 能在任务执行中根据需求即时构建、适配和复用外部能力,而非依赖固定工具集。
这一机制打破了人工设计功能的局限,为构建简洁而强大的代理系统开辟了新路径。
实验验证与成果
为了验证其设计理念的有效性,作者在多个真实任务基准上(如 GAIA)对 Alita 进行了全面测试,结果表明:
- 简约设计并非性能障碍,反而是一种能力释放;
- 目前 我们产品的搭建的agent的能力太多,导致我们需要写大量的prompt。
- Alita 实现了可扩展的自主智能行为,表现优于众多复杂度更高的系统。
关键贡献
作者总结了本工作的三点主要贡献:
- 提出以最小预定义 + 最大自进化为核心的新型代理架构,挑战传统通用型代理的设计范式;
- 实现并发布了实际系统 Alita,该系统具备高度扩展性的智能推理能力;
- 在 GAIA 等多个任务基准中,无需复杂预定义工具与工作流的情况下,Alita 依然表现出色,超越多个更为复杂的系统。
Related Works
本章从四个方面综述了与 ALITA 相关的研究工作,分别是:Generalist Agent、Auto Generating Agent、Tool Creation、MCP(Model Context Protocol)。
2.1 Generalist Agent
Generalist Agent 的目标是构建一个能够在真实世界环境中协作完成多种复杂任务的 AI 代理系统。代表性工作包括:
- OWL [8]:引入任务分解机制,将复杂任务拆分为子任务并分配给具备专业工具的工作节点。
- Omne [11]:提出多智能体协作开发框架,每个 agent 拥有独立系统结构,可以自主学习、构建世界模型,实现对环境的独立理解。
- OpenAI Deep Research [2]:使用强化学习在真实任务中进行训练,致力于为知识密集型任务生成准确的研究报告。
- A-World [12]:提供一个高度可配置、模块化、可扩展的仿真环境,使开发者可灵活定义和整合各种类型的 AI 代理。
- Magentic-One [13]:整合 Magentic 与 Autogen 系统,将 LLM 驱动的函数生成(微观)与多智能体编排(宏观)区分,从而更高效地构建 agent 系统。
Alita 作为 Generalist Agent 的代表,强调最小预定义工具与流程,专注于直接问题求解,同时在多样化任务中依然展现出优异性能。
2.2 Auto Generating Agent
这类方法旨在使代理能够自动生成适配具体任务的工具、代理或流程,增强代理的多样性与灵活性:
- AutoAgents [14]:通过自动生成多个代理,每个承担不同角色,分别处理子任务。
- OpenHands [15]:采用事件驱动架构,使代理能像人类开发者一样与环境交互,创建自定义工作流。
- AFlow [16]:将工作流优化建模为搜索问题,通过调用多个大型 LLM 节点组合搜索最优方案。
- AutoAgent [17]:为 LLM 代理提供一个操作系统框架,使其能够独立处理系统级操作与文件数据。
Alita 在此方向上使代理可以自动生成高质量的 MCP(Model Context Protocol),既服务当前任务,也为未来执行提供资源支持。
2.3 Tool Creation
该方向关注代理如何自主或借助外部资源创建工具来辅助任务完成:
- CRAFT [18]:利用 GPT-4 生成一系列代码片段作为工具,供系统调用。
- TroVE [19]:维护一组高级函数,自动生成、扩展并定期修剪,以优化程序生成。
- CREATOR [20]:将工具创建的抽象过程与实际执行过程解耦,使 LLM 可在不同粒度水平上处理任务。
- AutoAgent [17]:允许代理根据任务需求,结合网页检索信息,自动创建并集成新工具。
- OpenHands [15]:代理在与环境交互中可类人方式编写脚本辅助任务完成。
相较之下,Alita 采用 MCP 创建机制代替传统工具创建,具有更高的可复用性与环境管理效率。
2.4 MCP(Model Context Protocol)
MCP 是由 Anthropic 提出的标准协议,用于统一 AI 系统与外部数据源或服务的连接方式:
- RAG-MCP [21]:通过检索增强生成,从大量 MCP 描述中筛选最相关工具,以提升代理执行效率与准确性。
Alita 中,生成的有效工具会被包装成 MCP,并用于后续任务中,既便于代理自身复用,也可供其他代理系统使用。
Methods
本章详细阐述了 Alita 的整体设计思想与实现流程,强调其“最小预定义 + 最大自演化”的核心理念。主要包括以下模块内容:
图 3:Alita 系统架构图
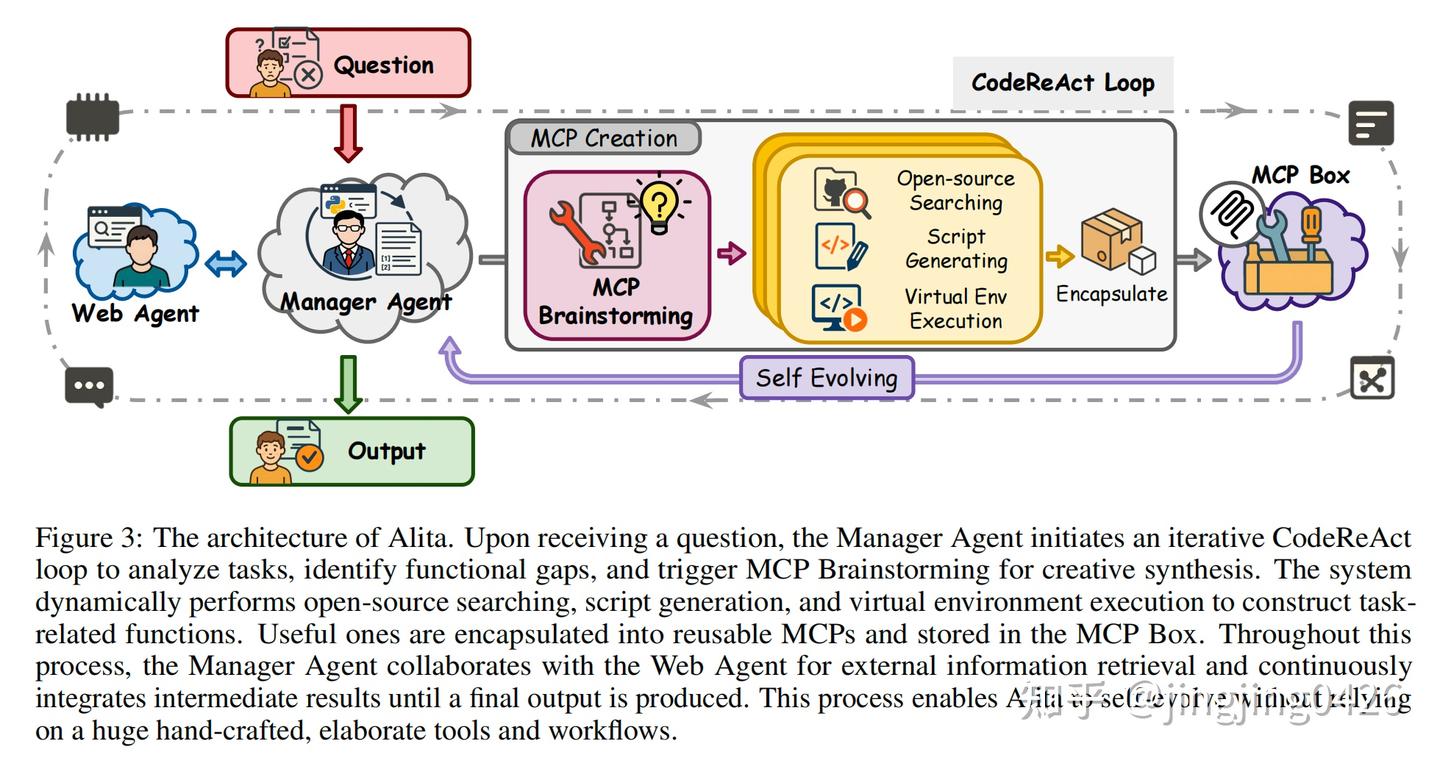
- 图示描述:
- 展示了 Alita 的任务处理流程,从接收任务开始,经过 MCP Brainstorming、Web 搜索、脚本生成、虚拟环境执行等阶段,最终生成可复用的 MCP。
- 核心组件:
- Manager Agent:协调整个流程。
- Web Agent:负责外部检索。
- MCP Box:封装生成的工具。
- 核心解释:
- 接收任务后,Manager Agent 发起 CodeReAct loop(一个反应式代码执行循环);
- 启动 MCP Brainstorming 分析任务能力缺口;
- 使用 Web Agent 检索开源工具;
- 自动构建脚本、配置执行环境;
- 将有效工具封装为 MCP,加入 MCP Box,支持未来复用。
3.1 Execution Pipeline
每个任务从构造增强的 prompt 开始,由 Manager Agent 发起多步推理流程,期间可能使用 Web Agent 搜索信息,生成新工具,并在隔离环境中执行。
重要流程:
- 成功生成有效工具后,将其转换为 MCP 并注册。
- 所有步骤(代码、中间结果、最终输出)均被记录。
3.2 Manager Agent
Manager Agent 是协调者,任务流程如下:
- 发起 MCP Brainstorming 评估能力缺口;
- 将任务拆解为子任务;
- 分发给 Web Agent 或使用工具生成模块;
- 汇总所有中间结果形成最终回答。
使用工具:
MCP Brainstorming:检测任务中缺失的能力并规划所需工具;ScriptGeneratingTool:构建外部工具;CodeRunningTool:在隔离环境中执行代码并缓存结果,若成功则封装为 MCP。
3.3 Web Agent
在内部知识不足时,Web Agent 负责从外部网站检索代码或文档信息,适合处理领域相关的技术问题。
使用工具:
- 浏览工具:
SimpleTextBrowser,VisitTool,PageUpTool,PageDownTool - 搜索工具:
GoogleSearchTool,GithubSearchTool
通过这些工具可实时访问网页和 GitHub 代码片段,用于辅助工具生成。
3.4 MCP Creation Component
这一部分由多个工具协作,组成 MCP 自动生成能力的支撑体系:
3.4.1 MCP Brainstorming
- 提供任务 + 当前系统能力描述,通过专门设计的提示语促进自我评估;
- 如果发现能力不足,输出用于后续工具生成的参考提示。
3.4.2 ScriptGeneratingTool
- 接收任务描述 + GitHub 代码建议,生成代码脚本;
- 自动生成:
- 环境构建脚本;
- 清理脚本;
- 保证生成脚本可执行、独立,并具备复用性。
3.4.3 CodeRunningTool
- 在隔离环境中运行脚本;
- 若结果正确,则注册为 MCP;
- 支持错误检测和迭代优化,提升代码质量。
3.4.4 Environment Management
- 使用
TextInspectorTool解析 README、requirements.txt、shell script 等; - 自动创建 Conda 环境,并安装依赖;
- 支持多环境并行运行,无需管理员权限或容器;
- 若创建失败,将触发自动恢复机制(如放宽版本限制、识别最小依赖集),若仍失败则记录日志用于未来优化。
总结核心亮点:
- 最小预定义:Alita 只保留必要核心能力,如 Web Agent 和一组简洁通用工具;
- 最大自演化:通过自动 MCP 生成循环,实现逐步自我强化;
- 图 3 是关键图示:完整展现了从接收任务到封装 MCP 的全过程。
Experiments
4.1 Experiment Setting
4.1.1 Benchmarks:任务集详解
✅ GAIA Benchmark【主测评集】
- 出自原文:“[GAIA] consists of 466 real-world scenario-based questions covering daily tasks, scientific reasoning, web browsing, and tool usage.”
- 覆盖任务类型:
- 日常任务(如订机票)
- 科学推理(推断类、图表类)
- 网页浏览类(信息查询)
- 工具使用(编程、代码执行)
- 任务难度等级(源自原文):
- Level 1:较简单,基础类问题;
- Level 2:中等复杂度,通常需要逻辑推理和工具调用;
- Level 3:高难度,需构建工具、生成代码或整合多个步骤。
- 评估指标:
- pass@1:一次运行中回答正确的比例;
- pass@2, pass@3:最多运行2或3次,挑选最优结果。
✅ MathVista Benchmark
- 目的:测试视觉上下文中的数理推理能力;
- 任务涵盖:
- 图像+文本的多模态输入;
- 数学题解答;
- 编程题生成;
✅ PathVQA Benchmark
- 目的:医学领域视觉问答;
- 考察维度:
- 医学图像理解
- 空间与因果推理
- 医学知识融合与检索
**4.1.2 Baselines:对比系统分析&**lt;br/>
| Baseline | 原文简介 | 设计方式 | 局限性 |
|---|---|---|---|
| Octotools | 多工具组合平台 | 拥有 10+ 工具卡片,专用于多任务场景 | 静态工具,泛化性弱 |
| Open Deep Research (ODR) | 来自 Smolagents 项目 | 基于多轮工具使用链,支持复杂研究任务 | 工具重,复杂度高 |
| AutoAgent | 零代码平台 | 用户可通过自然语言设计 agent 工作流 | 偏交互配置,不具备自动生成功能 |
| OWL | CAMEL-AI 系统构建的多 agent 框架 | 子任务自动分配给专属 agent 类型 | 可扩展性强,但更依赖预配置结构 |
| A-World | 灵活模块化模拟环境 | 多 agent 协作 | 更偏测试模拟平台 |
| OpenAI Deep Research | GPT 驱动的高级智能体 | 可执行多步研究任务 | 性能好,但系统闭源 + 复杂度高 |
AutoAgent: https://zhuanlan.zhihu.com/p/33129109075
4.2 Results
图表编号:Table 1
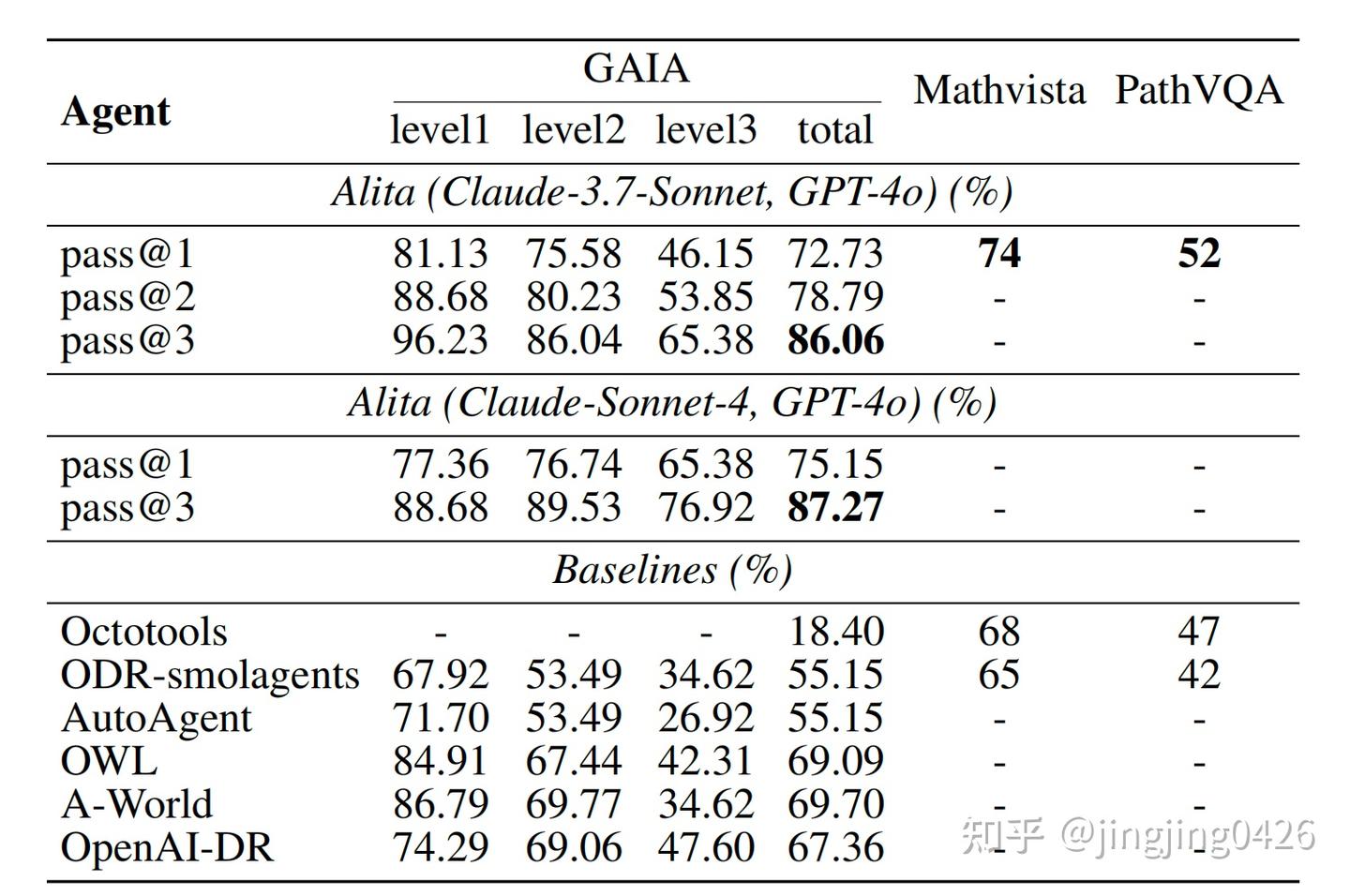
原文解释:
“Alita outperforms all baseline agents across the GAIA levels, achieving the highest total accuracy.”
MathVista 和 PathVQA 详细分析:
- MathVista 上:
- Alita 74% > Octotools 68% > ODR-smolagents 65%
- 更强的数理+视觉多模态能力;
- PathVQA 上:
- Alita 52% > ODR-smolagents 42%
- 医学问答中具备更好的检索与推理整合能力;
细节能力对比分析(为何 Alita 更强)
✅ Alita 使用动态构建 MCP,零预定义
传统系统如 Octotools、ODR:
- 需提前定义一堆工具;
- 若任务未覆盖 → 工具失效、解答失败;
而 Alita:
- 动态构建工具 → 自生成脚本 → 自动部署 Conda 环境 → 封装为 MCP → 多次复用;
- 具备任务驱动型能力成长机制。
✅ 自动失败修复机制
原文说明:
“If these recovery attempts are unsuccessful, the tool is discarded, and the failure is logged for offline analysis and future investigation.”
意味着 Alita 能够:
- 检测失败;
- 自动调整依赖;
- 不污染主环境;
- 提高 agent 健壮性与容错性。
✅ 更高的可迁移性与通用性
Alita MCP 可被其他系统调用,例子将在第5章展示(如 smolagents 使用 Alita MCP,GAIA 得分大幅上升)。
这意味着:
- 你可以只部署 Alita,用它来为其他系统“造工具”;
- 避免自己重复开发脚本和功能接口。
✅ 为什么应参考 Alita?
- 如果你不想手工配置工具、脚本;
- 如果你需要 agent 面对开放任务(未知输入、领域)仍可处理;
- 如果你想让 agent 系统具有 “自增长” 能力;
那 Alita 是目前少有真正具备“进化性”的系统设计实例。不像其它系统靠人堆工具,它靠agent 自己生成 MCP 工具并复用,非常契合通用智能体未来的方向。
Analysis
本章深入分析 Alita 的内部运行效果及其生态复用能力,分为以下结构:
- 5.1:Alita 生成的 MCP 的复用能力分析
- 5.2:小模型(低算力)版本的 Alita 表现
- 5.3:具体任务场景案例研究(Appendix A)
5.1 Reuse of Alita-Generated MCPs
Alita 的一大核心优势是**“可以生成通用性很强的 MCP”,这些 MCP 不仅自己用得好,还能迁移给其他 agent 使用**,显著提升其性能。
5.1.1 概述(Overview)
- MCPs 是 Alita 使用 Claude + GPT-4o 在 GAIA 上生成的任务工具(如爬虫、脚本等);
- 它们的优势是:
- 通用性强:任务适配广泛;
- 无需训练:由大模型原生生成;
- 即插即用:作为 MCP 服务器,可被别的系统远程调用;
- 具备 distillation 效果:
“The reuse of MCPs…can be viewed as a new way of distillation from larger LLMs.”
即:原来 distill 需要用大模型生成数据训练小模型,而现在直接复用大模型生成的 MCP,更快更便宜。
5.1.2 ODR-smolagents 上的复用实验
对比:在 GAIA 上运行 ODR-smolagents agent:
| Model 配置 | Level 1 | Level 2 | Level 3 | 总体 |
|---|---|---|---|---|
| ❌ 无 Alita MCP | 33.96% | 29.07% | 11.54% | 27.88% |
| ✅ 使用 Alita MCP | 39.62% | 36.05% | 15.38% | 33.94% |
原文结论:
“The consistent improvement…indicates that Alita’s MCPs provide generalizable utility.”
说明:
- Alita MCP 并非只适用于某些个例;
- 而是能普适提升整个 agent 系统的能力;
- 特别是 Level 3,最复杂问题的提升最明显。
5.1.3 小模型 + MCP 的效果(Low-resource agent)
实验:在 GPT-4o-mini 模型上运行 ODR-smolagents 框架:
| 配置 | Level 1 | Level 2 | Level 3 | 平均 |
|---|---|---|---|---|
| ❌ 无 MCP | 32.08% | 20.93% | 3.85% | 21.82% |
| ✅ 有 MCP | 39.62% | 27.91% | 11.54% | 29.09% |
原文解读:
“This helps bridge the gap between the agents on smaller LLMs and agents on larger LLMs…”
说明:
- Alita MCP 是一种**“无需再训练的压缩迁移机制”**;
- 小模型原本无法解决复杂任务;
- 复用 MCP 即可拥有大模型级别的工具能力。
5.2 Alita on Smaller LLM(低算力模型适配性)
实验:用 GPT-4o-mini 替代 Claude-Sonnet-4 + GPT-4o 运行 Alita。
| 配置 | Level 1 | Level 2 | Level 3 | 总体 |
|---|---|---|---|---|
| Claude + GPT-4o | 81.13% | 75.58% | 46.15% | 72.73% |
| GPT-4o-mini | 54.72% | 44.19% | 19.23% | 43.64% |
原文总结:
“This substantial performance gap highlights the critical role of the underlying models’ coding capabilities.”
说明:
- MCP 构建过程仍依赖大模型的代码理解与生成能力;
- 小模型单独执行 Alita 的架构会显著降分;
- 但!→ 可以通过 MCP 复用缓解这一问题(如 5.1 所示)
本章总结:Alita 的核心优势在哪里?
✅(1)MCP 模块具有极高通用性
- 可跨 agent 迁移;
- 无须再训练、即可使用;
- 本质上实现了“能力原子化”:一个 agent 可以产出其他 agent 可复用的“能力块”。
✅(2)支持能力下沉,适配轻量模型
- 用 GPT-4o-mini + MCP,可实现中高复杂度任务;
- 特别适用于算力预算紧张但任务多样的 agent 系统;
- MCP 是低成本推理增强机制。
✅(3)Agent 自演化机制 = 更低维护成本
你无需提前部署一堆工具;
- Alita 会根据任务自检 → 生成合适的脚本 → 封装为 MCP;
- 极大减少人工配置负担,适合复杂、变动大环境(如搜索、科研、API 操控等)。
站在产品/系统构建角度:你为什么该参考 Alita 方法?
| 问题 | 传统做法 | Alita 提供的新解法 |
|---|---|---|
| 任务多样,难以预定义工具 | 静态 hardcode 工具库,维护成本高 | 动态构建 MCP,适应性强 |
| 多 agent 系统需重复造轮子 | 每个 agent 定义一套流程/工具 | 共用 MCP Box,实现模块复用 |
| 小模型无法完成复杂任务 | 需蒸馏训练或替换大模型 | 小模型 + 大模型生成的 MCP 即可 |
| 如何实现能力升级? | 需整体换模型或重构 | 自演化机制,持续成长 |
| 如何验证模块有效性? | 手动测试/部署 | MCP 有标准化接口 + 自动执行验证 |
✅ 总结语:
Alita 不是在“堆”智能,而是在“进化”智能。
- 它构建的是一个可以自己评估自己 → 自主构建能力 → 自主复用能力的 agent;
- 它的 MCP 能力具备系统可迁移性、架构普适性、工具可复用性;
- 对于构建复杂、多变、需要长期维护的 agent 产品系统,Alita 的理念可以极大降低人力维护与技术门槛。
思考
一、应从 Alita 中借鉴什么?
1.「最小预定义,最大自演化」的系统设计理念
传统 agent 系统往往预设大量工具和任务流程 —— Alita 启发我们:
你不需要一开始就为每个任务设计工具,而是让 agent 自己在运行时识别缺口、构建能力。
意义:
- 降低工程初期复杂度;
- 增强应对未知任务的能力;
- 结合 GPT/Claude 的强代码能力,你完全可以复刻 Alita 的 CodeReAct 循环 + MCP 生成功能。
- 「MCP:工具原子化 + 共享」机制
MCP(Model Context Protocol)本质是对能力的标准化封装,使得:
- 工具可以动态创建,也可以跨 agent 共享;
- 每个 agent 不必自己从头实现某能力,而是通过「调用已有 MCP」。
意义:
- 你可以设计一个「MCP Registry」作为你系统的插件库;
- agent 间共享已有能力,避免冗余开发;
- 支持对小模型 agent 的能力增强(通过调用大模型创建的 MCP)。
- 自我反馈与工具验证机制
Alita 允许工具失败,并具备:
- 环境创建失败自动降级;
- 错误脚本迭代修复;
- 无效 MCP 自动废弃,记录用于日志。
意义:
- 提升产品稳定性;
- agent 可边跑边 debug,适合 real-world 场景下的鲁棒系统;
- 可以构建 MCP 打分 / 健康评估体系。
✅ 二、基本的问题表述
| 问题 | 回答(基于 Alita) |
|---|---|
| Q1:Alita 和 AutoGPT、OpenAI Agent 有什么不同? | Alita不靠预设插件,而是运行时自动分析缺口、自动生成代码工具(MCP);它的重点是“系统自演化”,不是工具套壳。 |
| Q2:你们产品如何保证生成的代码可执行? | 我们借鉴 Alita,设计了环境自动创建 + 多轮执行验证 + 自动清理机制,确保生成代码有效。 |
| Q3:Alita 是不是太依赖 LLM 编程能力? | 是的,但 Alita 提供了一个替代方案:工具生成后封装为 MCP,可以让小模型也能用;我们在产品中也采用类似“能力转移”策略。 |
| Q4:Alita 的 agent 是如何协作的? | 实际上 Alita 是单 agent 自演化结构,不涉及显式多 agent 协作;但 MCP 可以作为不同 agent 的连接桥梁,我们系统在此基础上设计了多 agent 的能力链路。 |
| Q5:MCP 和 API 有啥区别? | MCP 是 LLM 可解释/使用的协议封装,不只是调用 API,它包含背景信息、接口结构说明,更适合语言模型上下文调用。 |
✅ 三、这篇论文的不足与应用挑战(特别针对multi-agent的产品)
❌ 1. 依赖大模型高质量代码生成能力
- 若模型如 GPT-4o / Claude 表现不稳定,可能生成:
- 无效代码
- 环境依赖错误
- 异常逻辑
对策:
- 加强 script validation 层(语法 + dry-run);
- 设计评分机制,对历史 MCP 进行效果跟踪与淘汰;
- 加入人类 review option(选择性验收)。
❌ 2. MCP 的标准化和权限管理问题
Alita 使用开源 MCP 概念没细谈:
- 谁有权创建 MCP?
- 如何确保安全(不执行恶意脚本)?
- 如何控制 agent 间权限访问?
对策:
- 你可以实现「MCP 权限标签 + sandbox 执行环境」;
- MCP 分为公开/私有;
- MCP 可绑定作用域,例如只供某类任务或 agent 使用。
❌ 3. 缺乏 Agent 间协同机制(非多 Agent)
Alita 本质是一个 “Self-evolving Single Agent”,
- 无 Multi-Agent 任务规划;
- 无角色分工 / 意图调度;
- 无对话状态共享;
对策:
- 你可以引入一个「Planner Agent」专门调度多个「Executor Agent」,他们共享 MCP;
- 多 agent 分任务、分技能模块,例如:
- 信息检索 Agent
- 代码生成 Agent
- 审核 Agent
- 输出包装 Agent
❌ 4. 未考虑执行效率与资源成本
MCP 生成 + 多轮运行很消耗资源,论文未讨论:
- 执行时间成本;
- 多环境并行执行带来的系统负担;
- 任务粒度与工具粒度不匹配问题。
对策:
- 设置任务复杂度阈值,轻任务不生成 MCP;
- 合理缓存、归档常用 MCP;
- 针对「任务 → MCP」进行聚类或推荐系统优化。
✅ 最后总结建议
针对Multi-Agent 产品,可以借用 Alita 的三个精华:
- 能力原子化(MCP):模块化所有生成工具,复用 + 可控;
- 运行时工具合成:agent 不要全靠人类设定流程,让系统根据任务决定该生成什么;
- 自演化+复用闭环:任务运行 → 工具生成 → 工具验证 → 工具注册 → 未来复用,这是产品通用性关键。