Shall We Pretrain Autoregressive Language Models with Retrieval
Shall We Pretrain Autoregressive Language Models with Retrieval? A Comprehensive Study
解析论文《Shall We Pretrain Autoregressive Language Models with Retrieval? A Comprehensive Study》的主要内容
本文由 Boxin Wang 等人(主要来自 NVIDIA)撰写,旨在解决一个核心问题:在预训练自回归语言模型(如 GPT)时,是否应融入检索机制? 通过全面研究检索增强模型 RETRO 及其变体 RETRO++,论文比较了 RETRO 与标准 GPT、微调阶段融入检索的 GPT(如 RAG)和推理阶段融入检索的 GPT(如 KNN-LM)的性能差异。研究基于大规模预训练(参数规模从 148M 到 9.5B,检索数据库包含 330B tokens),并覆盖文本生成质量(text generation quality)、下游任务准确性和毒性等多个维度。以下是详细解析,结构分为六个部分,确保内容逻辑清晰、层次丰富。
1. 研究背景与核心问题
- 问题动机:大型自回归语言模型(如 GPT-3/4)虽在文本生成和下游任务上表现优异,但存在显著缺陷:
- 高参数需求导致部署成本高。
- 事实准确性差(易产生幻觉)。
- 知识更新困难(预训练后无法轻松融入新事实)。
- 检索增强(如 RETRO)可降低困惑度(perplexity),但其对文本生成质量(如流畅性、事实性)和下游任务的影响尚不明确。
- 研究目标:通过复现和扩展 RETRO 模型,系统评估检索在预训练阶段的价值,回答“是否应在预训练自回归 LM 时默认融入检索?”。
- 方法概述:公平比较 RETRO 与 GPT(相同架构、超参数、预训练语料),并引入新变体 RETRO++。
2. 模型设计与实现细节
-
RETRO 核心机制:
-
分块检索(Chunk-wise Retrieval):输入序列被分为固定大小块(chunk size=64),每个块基于前一块检索最近邻(k-nearest neighbors),并通过双向编码器融合检索信息,指导下一个块的生成。这确保了因果性(causality)和可扩展性。
-
检索数据库:使用整个预训练语料(330B tokens)构建 Faiss 索引,支持高效近似最近邻搜索(查询延迟约 4ms/chunk)。
-
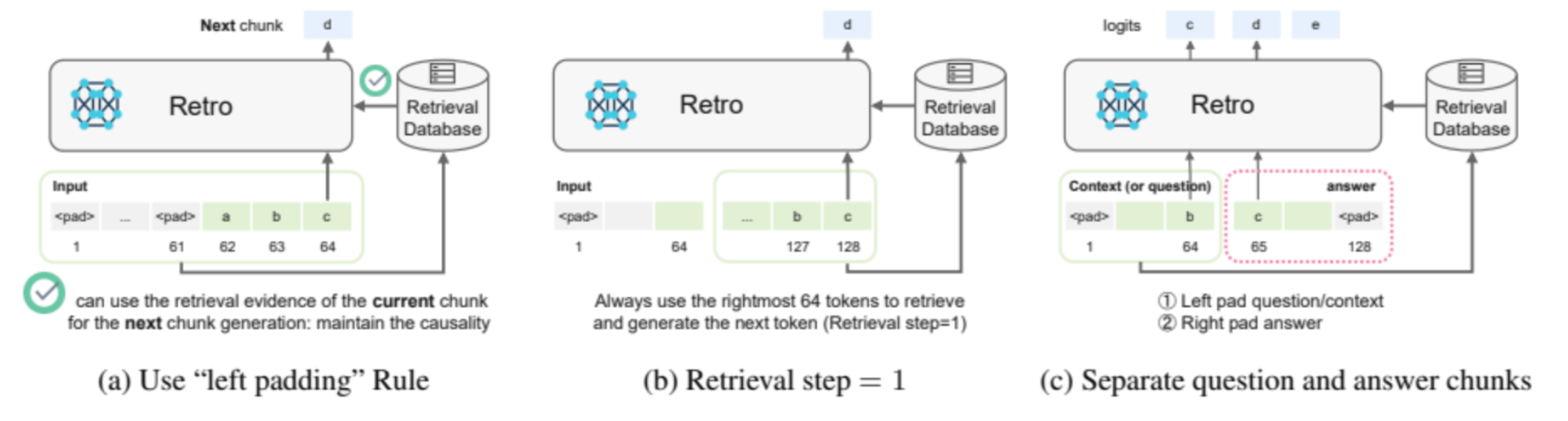
推理优化:提出“左填充规则”(left padding rule),解决短上下文下的检索对齐问题(图1展示填充设计)。

-
检索频率策略:支持灵活检索步长(retrieval step),平衡生成准确性和计算开销(小步长用于短答案任务,大步长用于长文本生成)。图3 示意不同步长的影响。
-
-
RETRO++ 变体:针对开放域 QA 任务优化,将最相关证据(top-1 检索结果)输入解码器作为上下文,其余证据输入编码器。这显著提升 QA 准确性。
-
预训练设置:RETRO 和 GPT 使用相同配置(层数、隐藏大小等),预训练语料为 330B tokens(包括 Wikipedia 和 CommonCrawl)。RETRO 预训练开销比 GPT 高约 25%(表11),但收益显著。

3. 关键发现:文本生成质量评估
论文全面评估了开放端文本生成(open-ended generation),涵盖质量、事实性和毒性:
-
文本质量:
-
自动评估(基于 5000 个提示):RETRO 显著减少重复(repetition% 平均降低 21%),同时在多样性(Self-BLEU)和词汇使用(Zipf 系数)上与 GPT 持平(表3)。
-
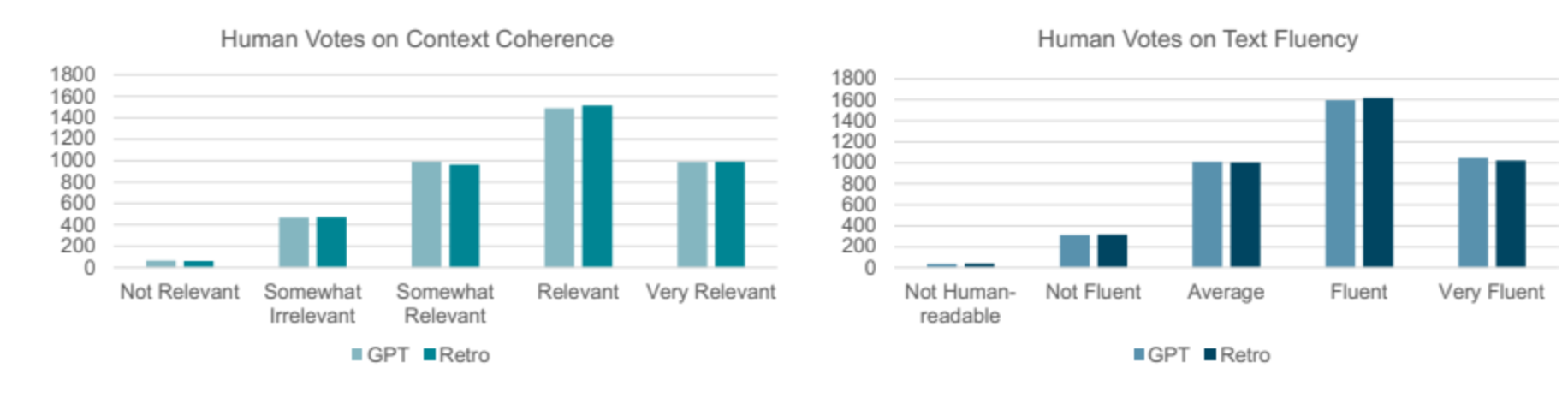
人工评估(200 个样本):RETRO 在流畅性(fluency)和连贯性(coherence)上略优于 GPT(平均分数:RETRO 3.826 vs. GPT 3.818),图4 显示人类投票分布。
-
-
事实准确性:
- 在 FACTUALITYPROMPTS 基准上:RETRO 通过贪婪解码(greedy decoding)减少幻觉(hallucination),命名实体错误率(NEER)降低 2.45%,蕴涵率(EntailR)提高 3.75%(表4a)。
- 在 TruthfulQA 基准上:RETRO 在对抗性问题上表现更稳健,但改进幅度较小(因问题涉及逻辑谬误,检索帮助有限)。
-
毒性控制:
- 使用预训练数据库时,RETRO 毒性略高于 GPT(因检索可能放大有害内容)。
- 但切换到 Wikipedia 数据库后,毒性概率(toxicity probability)从 37% 降至 35%(表5),证明检索数据库质量是关键。
4. 下游任务性能:LM 评估基准与开放域 QA
-
LM 评估基准(Zero-Shot):
- 知识密集型任务:RETRO 在 Hellaswag(常识推理)和 BoolQ(是/否问答)上显著优于 GPT(平均提升 2-6%),因检索提供额外事实支持(表6)。
- 非知识密集型任务:如 Lambada(词预测)和 RACE(阅读理解),RETRO 与 GPT 持平(平均差异 <1%)。
- 微调后性能:在 Hellaswag 和 Lambada 上微调后,RETRO 改进幅度更大(表15),表明其更易适应新领域。
- 对比检索增强 GPT:在推理阶段直接添加检索证据会损害 GPT 性能(准确率降至 ~24.5%),因噪声证据干扰上下文(表16)。
-
开放域 QA 任务:
-
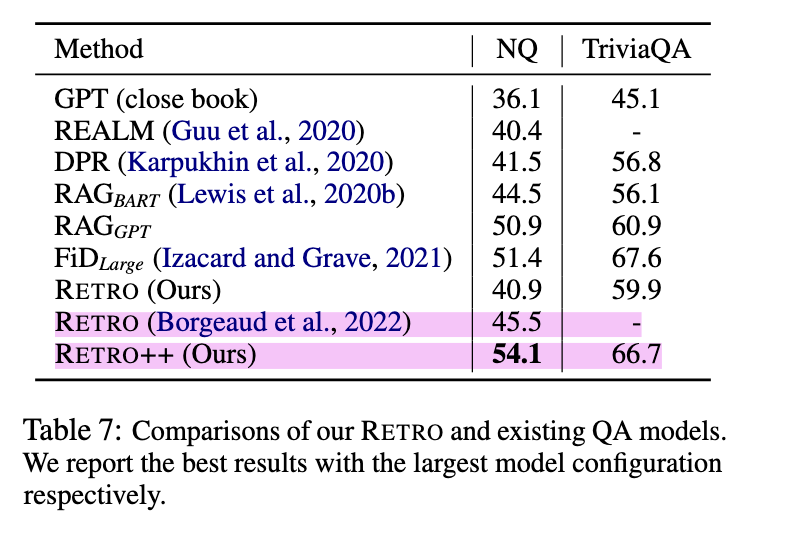
RETRO++ 的突破:在 Natural Questions(NQ)和 TriviaQA 上,RETRO++ 的 EM 分数显著提升(NQ:54.1% vs. 原始 RETRO 40.9%),超越 RAGGPT(微调阶段融入检索的 GPT)和 FiD 等基线(表7)。
-
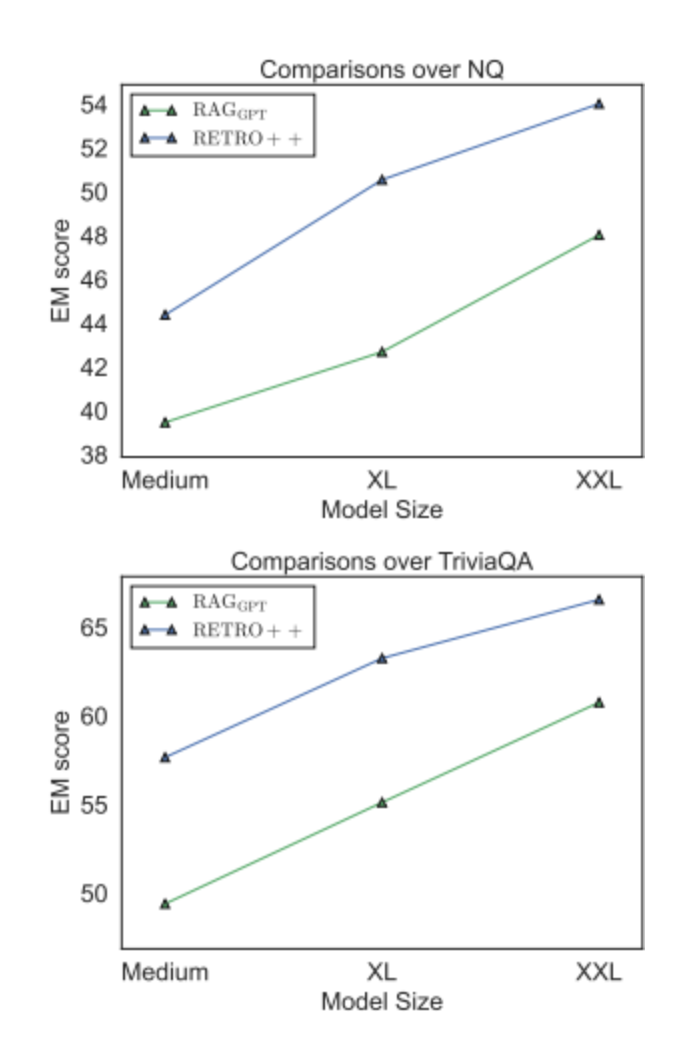
模型规模扩展:图2 显示 RETRO++ 随参数增加(Small 到 XXL)性能单调提升,且始终优于 RAGGPT。
-
指令微调(Instruction Tuning):在 RETRO++ 上应用指令微调后,零样本 QA 准确率进一步提升(NQ EM 从 24.43% 升至 29.75%),凸显检索增强模型的兼容性(表8)。
-
5. 创新贡献与结论
- 核心创新:
- 成功复现并扩展 RETRO(至 9.5B 参数),提供可扩展预训练配方。
- 提出 RETRO++,通过优化证据融合机制,大幅提升 QA 性能。
- 首次全面证明:预训练阶段融入检索,能系统改善文本生成质量、事实性、毒性控制及下游任务(尤其知识密集型任务)。
- 结论:预训练自回归 LM 时融入检索(如 RETRO)是值得推广的方向,因其:
- 降低模型退化(如重复生成)。
- 提升事实准确性(通过检索实时知识)。
- 在相同困惑度下,用更少参数匹配或超越 GPT 性能。
- 实践意义:论文开源代码和模型(GitHub 链接),推动未来基础模型发展,尤其是在检索增强架构上结合指令微调等高级技术。
6. 局限性与未来方向
- 局限性:
- 检索数据库依赖:模型事实性和毒性高度依赖数据库质量(如 Wikipedia 优于预训练语料)。若数据库含偏见或错误信息,性能会下降。
- 计算成本:RETRO 预训练开销比 GPT 高 25%(表11),大规模扩展(如 >10B 参数)尚未探索。
- 任务特定性:RETRO++ 主要优化 QA,其他任务(如对话)需进一步适配。
- 未来工作:
- 探索更大规模模型(如 48B 参数 RETRO)。
- 结合强化学习人类反馈(RLHF)进一步降低毒性。
- 开发动态数据库更新机制,避免预训练后知识过时。
此研究为检索增强语言模型提供了实证基础,证明其在构建高效、可信赖的基础模型中的潜力。如需深入细节,可参考论文中的完整实验数据(如附录中的配置表)或访问开源代码库。