基于 Ray 的分离式架构:veRL、OpenRLHF 工程设计
基于 Ray 的分离式架构:veRL、OpenRLHF 工程设计
转载:https://zhuanlan.zhihu.com/p/26833089345
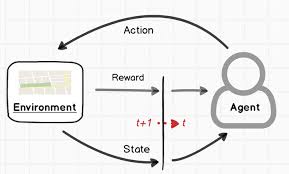
在 RL、蒸馏等任务中需要多个模型协同完成计算、数据通信、流程控制等工作。例如 PPO 及各类衍生算法中,就需要管理 Actor、Rollout、Ref、Critic、Reward 等最多 5 类模块,每类模块还承担着 train、eval、generate 其中的一种或多种职责,而蒸馏任务中也存在着多组 Teacher 和多组 Student 共同蒸馏的场景。
如果我们仍然采用 Pretrain、SFT 训练这种基于单脚本多进程的运行模式(通过 deepspeed、torchrun 等命令启动任务),是难以实现灵活的任务调度和资源分配策略的。而 Ray 提供的 remote 异步调用和 Actor 抽象,可以让每个模块有独立的运行单元和任务处理逻辑,这种分离式架构使之天然适配多模型之间的频繁交互和协同工作的场景。
这篇文章以当今最为流行的两个 RL 框架 veRL 和 OpenRLHF 为例,从工程角度分析这两个框架的特点和优势,以及它们是如何实现多 Actor 场景下的分离式训推混合任务的(也为我最近开发的一个蒸馏框架提供一些灵感hhh)。
我会从以下 3 个角度去分析两个框架:
- 每个模型/模块的职责,以及它们训练/推理所采用的 backend 是什么;
- 如何通过 Ray 分配各个模块的资源,以及如何实现模块的资源共享(colocate、Hybrid Engine);
- 运行过程的 data flow 和 control flow 是怎样的,从任务分发到任务实际执行的调度链路是什么。
文章中有非常多的代码的跳转链接,我非常推荐各位大佬们结合实际代码来理解文章内容,毕竟 talk is cheap,多看代码才能快速提升基本功~
好的,大家坐稳了,我们要出发了~
先简单介绍下 Ray
这里给不太熟悉 Ray 工作模式的同学普及一下基本概念。
ray详解:https://zhuanlan.zhihu.com/p/460600694
源码分析:https://zhuanlan.zhihu.com/p/14075071550
1. 启动方式
Ray 提供了多种语言的调用接口,但我们用的最多的还是 Python 接口,一般我们会运行一个 Python 脚本,并在这个脚本中运行ray.init()就自动创建了一个 Ray 集群,通常这个脚本的运行进程叫做 driver process。除此之外,我们也可以通过在命令行运行ray start手动启动 Ray 集群,并在脚本中去 attach 到这个集群上。
2. 运行逻辑
Ray 集群在操作系统层面上主要体现为节点上一组驻留的进程池。当我们创建一个函数或者一个类,并用@ray.remote装饰后,这个函数/类就成为了一个可调度的 Task/Actor。我们可以调用这个 Task/Actor 的 remote 方法,按照调度策略将这个 Task/Actor 分配到某个节点的进程池上运行或初始化。对于 driver 来说,分发出去的任务是异步运行的,因此还需要通过 ray.get去获取异步运行结果。
Task/Actor 所传入的参数和返回的结果都会先被序列化为一个 Object,存放在 Ray 集群的 Object Store 里面。从 Ray 的层面看,一个 Ray 集群中所有节点的 CPU memory 共同组成了一个 (Shared) Object Store,节点之间在逻辑上是共享这个 Object Store 的所有资源的,因此我们(在逻辑上)不需要关心哪个对象存放在哪个节点,只需要ray.get这个 Object 的 reference,然后 Ray 就会自动拿取实际的 Object 并反序列化到运行进程中。
下面提供了一个案例,我们在 remote 初始化了一个 ParentActor并调用了它的 create_child 方法,这个方法在 remote 创建了一个 ChildActor。后续 parent_actor.get_work会让 parent 链式调用 child 的方法,获得 child 的运行结果。
1 | import ray |
上面的例子说明,Actor 可以通过组合的方式创建和运行,即在一个 Actor 中可以 remote 创建和调用另一个 Actor。值得注意的是,在现版本的 Ray 中是不能用继承的方式去继承一个 Actor 的方法的,所以我们只会在最终的子类上用 @ray.remote 装饰。
3. 资源调度
在创建 Actor 时,我们可以指定这个 Actor 所需要的运行资源(num_cpus, num_gpus 等),并从资源池中获取这些资源,若所需的资源不足则无法立即调度,这种方式只能实现资源的独占。同时我们还可以事先分配一个资源组(placement group),并将一个或多个 Actor 分配到这个资源组的一个 bundle 上,实现资源的独占或共享。显然后者的资源调度方式更为灵活,像 veRL、OpenRLHF 均采用了这个策略。
在我的蒸馏框架里面也采用了资源组的方式分配资源:
1 | remote_ray_worker = ray.remote( |
例如 RLHF 中的一个 Actor 模块,开启 dp=4,那么就可以创建一个 GPU=4 的资源组(暂时忽略 CPU 资源),并建立 4 个 GPU=1 的 bundle,然后对每一个 Actor worker 的分片,依次分配一个资源组的 bundle 即可。
2. 解析 OpenRLHF
从工程逻辑的角度看,OpenRLHF 的代码较为简洁易懂,而 veRL 有一些工程实现上的小 trick。所以我们先从 OpenRLHF 入手解读。
我现在使用的版本是最新的发版版本 v0.5.9.post1,当前支持 Ray 训练部分的仅有 PPO 及其衍生算法(REINFORCE++, GRPO, RLOO),我们主要看这一部分的代码。
与 Ray 相关的核心代码文件有:
- cli/train_ppo_ray.py:启动脚本
- trainer/ray/launcher.py:核心调度组件 PPORayActorGroup,以及 Ref Actor 和 Reward Actor 的实现
- trainer/ray/ppo_actor.py:Actor 和 Actor Trainer(继承 PPOTrainer)的实现
- trainer/ray/ppo_critic.py:Critic 和 Critic Trainer(继承 PPOTrainer)的实现
- trainer/ray/vllm_engine.py:vLLM Rollout Actor 的实现
- trainer/ray/vllm_worker_wrap.py:vLLM Worker 子类,同步 Actor 和 Rollout 模块权重的逻辑
- trainer/ppo_trainer.py:PPOTrainer 实现,即 PPO 算法主体
先放一张整体架构图:
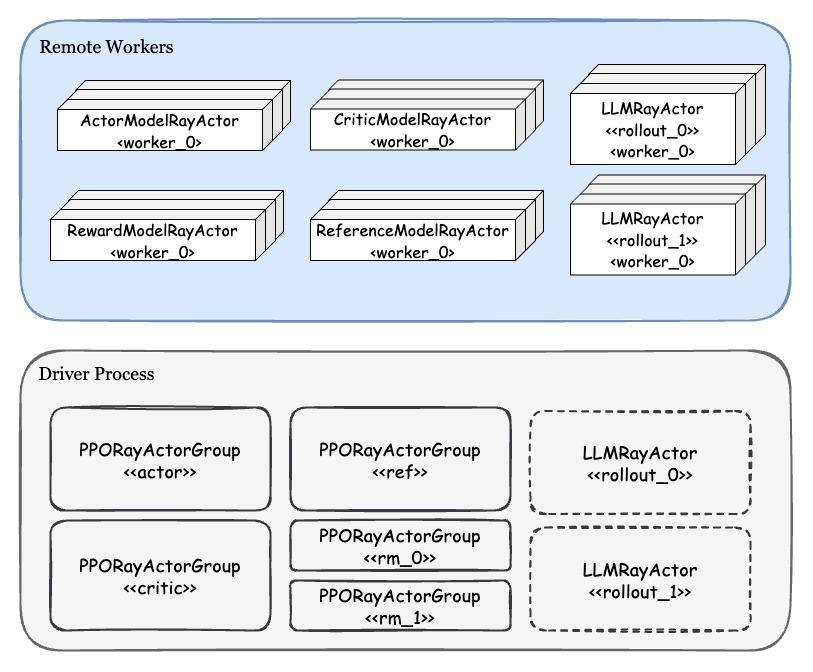
上图区分了 driver process 和 remote 上存在的实例。在 Driver 上有着各种模块对应的 PPORayActorGroup 实例,每一个 Group 实例代表着逻辑上的一个完整模型,而 Group 中的每个 remote worker 是这个完整模型的 DP 分片。对于 Rollout 模块而言,driver 上存在一个或多个 LLMRayActor 的 handle,每个 Actor 代表一个 vLLM engine,也就是一个完整的 DP 模型,每个 engine 内部还会通过 Ray 启动 TP worker Actor(这个 Ray 会 attach 到已有的 cluster,不会新建一个)。
Group 中创建 worker 是依次进行的:首先创建 rank0 worker(master actor),并由它获取整个 Group 建立通信的 addr 和 port,接着依次创建其他 worker 并传入通信的 addr 和 port。在初始化模型时,统一作通信组的初始化。注意 Group 之间的通信是相互隔离的,因此每一个 Group 的训练就可以等价于平时做的多进程模型训练。
因此在 Ray 的抽象下,各个模块都可以看成是独立的 multi-process training / generate,而模块之间的交互是通过 Object Store 和 Object Ref 做数据的收发来实现的。我们可以看到 Ray 在底层帮我们隐藏了许多技术细节,从而简化了多模型协同训练的搭建逻辑。
2.1. 训推模块与 backend
我们首先整理一下 PPO 算法中各个模块的功能和职责:
- Actor:训练模块,前向反向都计算,需要更新权重
- Critic:训练 + Eval 模块,前向反向都计算,需要更新权重
- Rollout:批量推理模块,用于生成 trace samples,需要和 Actor 同步权重
- RM、Ref:Eval 模块,仅前向计算,权重不更新
理论上,训练模块可以采用市面上所有的训练引擎充当 backend(torch DDP、FSDP、torchtitan、Megatron、Deepspeed 等),批量推理模块可以采用所有的推理引擎充当 backend(SGLang、vLLM、TGI 等)。但 Eval 模块训练推理引擎都可以做,需要仔细斟酌要用哪个,考虑到训练和推理引擎的精度差异(logit 数值上约有 10% 的相对误差),在涉及关键的 loss 计算还是要优先确保精度而非速度,所以我们可能会更倾向于在训练引擎跑一个 plain forward。
在 OpenRLHF 中,训练模块采用 Deepspeed,它的好处在于和现有 HF 生态融合地非常好,基本没有兼容性问题,也不太依赖特定版本,当然用 FSDP 也差不多。推理模块用 vLLM(为什么不用更快的 SGLang?可能是因为兼容性、框架熟悉程度或者使用习惯?),同时支持了 DP(多个 engine)、TP(每个 engine 内部)并行。
2.2. Ray 资源调度与 colocate
所谓 colocate,在这里的含义就是多个 Ray Actor 共享同一个 GPU 资源。由于 OpenRLHF 中每个 Ray Actor 都是某个模块的 DP(对 vLLM 而言是 DP+TP)分片,因此可以理解为不同模块对应的分片同时存放于一张卡上。这里的“同时存放”是概念上的,不一定要同时占用显存,实际上每个模块的分片可以通过 offload/reload 轮流占用显存。
OpenRLHF 提供了三种 colocate 方式:colocate_actor_ref,colocate_critic_reward 和 colocate_all_models。其中 colocate_all_models既包括了前两者,又增加了 Actor 和 Rollout 的 colocate。这三种 colocate 的实现方式都是类似的,也就是上面提到的事先分配资源组并给每个 worker 分片指定 bundle 的方式。
具体而言,PPO 的每个模块在逻辑上属于一个 PPORayActorGroup,如果模块之间存在 colocate,则往这个 Group 中传入同一个 placement_group(pg),然后在 Group 内部分配每个 worker 的 bundle。由于我们希望至多 5 种模块的 worker 共享一张卡,因此设置 num_gpus_per_actor=0.2 可以刚好满足资源需求。【不过这里存在一个 caveat:当开启 colocate_all_models并存在多个 reward model 时,那就有 6 个及以上的模块了,那么资源分配应该会失败,看官方是否认为这是个问题吧。】
不做 colocate 的模块则在 Group 内部新建资源组并分配 bundle,每个 DP 分片独占 1 个 GPU,因此也不会抢占其他 colocate 模块的 GPU 资源。
**这里需要尤其关注 Actor 和 Rollout colocate 的情况。**在 OpenRLHF 中,Actor 和 Rollout 是独立的两个模型,一个放在 deepspeed 训练引擎,一个放在 vLLM 中,它们需要保持权重的同步。因此当 Actor 更新时,需要将新权重 broadcast 到 Rollout 上。由于两个模块是 colocate 到一张卡上的,而 NCCL 无法做同一张卡上两个进程的通信,所以需要用 CUDA IPC 做进程间通信。通信组是在 Actor 的 worker0 和所有 vLLM engine 的所有 worker 之间建立的,权重同步分两步:一是在 Actor workers 内部 all_gather 权重,二是由 worker0 代表 Actor 向所有 Rollout 实例 broadcast 权重。
2.3. Data/Control Flow 梳理
OpenRLHF 各个模块写的非常整洁,然而它缺少了贯穿这些模块的统一的 Control 模块,使得实际的执行流程分散在各个模块之间,这同时也是这个代码库最难理解和 track 的部分。
从启动脚本出发,完成参数初始化、各个模块建立和模型初始化后,控制逻辑交给了隶属于 Actor 的 Group,调用 async_fit_actor_model,这个方法内会调用所有 Actor worker 的 fit方法,其本质是调用了PPOTrainer.fit,至此所有 worker 同时开训。
此时控制逻辑在每个 Actor worker 的 trainer 中,同时每个 Actor worker 都绑定到一组 (Ref, Critic, RMs) worker 上,Actor worker 生成或需要的数据只通过这些绑定的 worker 传输。理论上由于所有 Actor、Ref、Critic、RM 都是 DP 分片,Actor worker 向任何一个分片发送/接受数据都是等价的,实际上 OpenRLHF 是通过 round-robin 轮询的策略挑选组合的。
后续的控制逻辑比较分散,我整理后展示其伪代码如下:
1 | # In `PPOTrainer.fit`: https://github.com/OpenRLHF/OpenRLHF/blob/17bbb313551a3af3cdd213d8b9e7522fe9c6271b/openrlhf/trainer/ppo_trainer.py#L189 |
需要注意的是,这些所有的控制逻辑全部由 Actor workers 执行,同时每一个 Actor worker 负责控制对应它绑定的 (Actor, Ref, Critic, RM, Rollout) 这个 worker 组的 data flow,因此 Actor workers 的计算和通信负担是非常重的。当然这里只是直观上的结论,具体的性能瓶颈仍然需要跑实验看下。
3. 解析 veRL
veRL 代码的开源部分稍微乱了些,有许多看起来比较多余的抽象和封装,不过它是从闭源代码中抽出来的部分,内部应该还会对大量业务方和研究课题做了扩展和适配,因此这种“凌乱”可以理解。除此之外,我觉得 veRL 设计上最好的一点就是模块间充分的解耦,这使得修改和扩展自定义模块非常容易,同时框架使用了很多 Python 语法糖来巧妙的让一个 Ray Actor 在多种角色之间自由切换。
我目前看的也是最新版本 v0.2.0.post2。当前整个代码库基本都建立在 Ray 之上,我们这里主要关注 veRL 与 Ray + FSDP 相关的工程部分,相对而言会忽略 Megatron 部分以及绝大部分的模型、算法细节,不过 veRL 对于这部分做了充分的解耦,阅读和修改代码不会有太大的困难。
相关的核心代码文件有:
- trainer/main_ppo.py:启动文件
- workers/fsdp_workers.py:所有与 FSDP backend 相关的 Worker 实现
- ppo/ray_trainer.py:Trainer 和资源管理
- single_controller/ray/base.py:基于 Ray 的 colocate 和 WorkerGroup 实现
- workers/rollout/vllm_rollout/vllm_rollout.py:vLLM Rollout 实现
周边代码还有:
- single_controller/base/decorator.py:数据分发策略
- single_controller/base/worker.py:Worker 基类
- single_controller/base/worker_group.py:WorkerGroup 基类
首先还是从整体来看框架的组成部分:
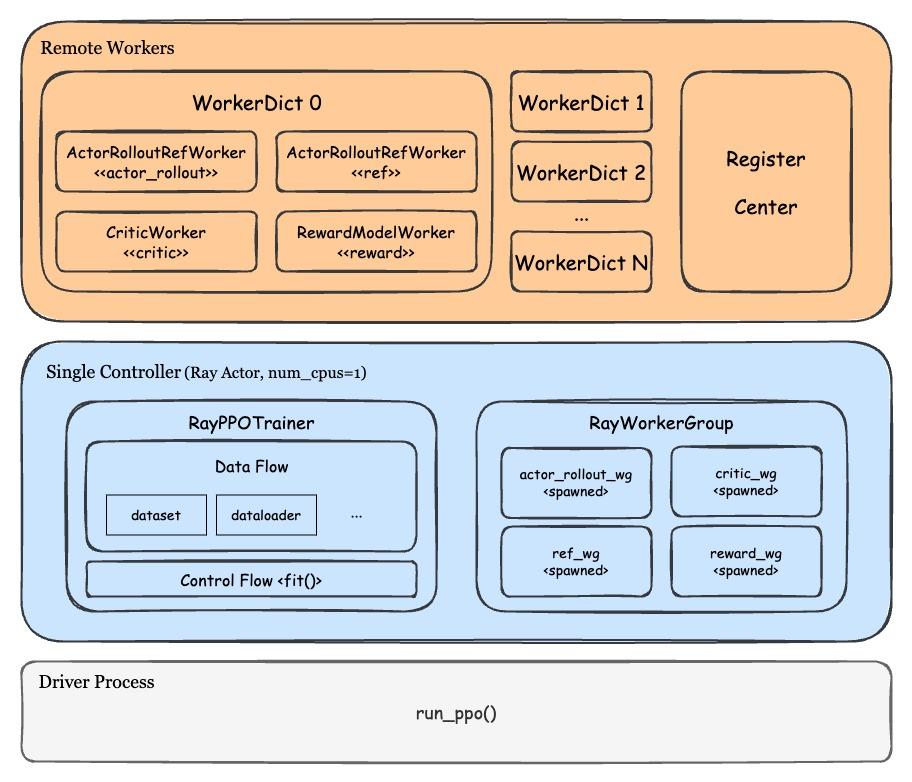
不同于 OpenRLHF 由多个 Actor 控制一组 workers 的 control flow,veRL 的主体控制逻辑集中于一个 Ray Actor 中(veRL 官方称之为 single controller),这个 single controller 仅运行在 CPU 上,负责管理 data flow、control flow、各类数据结构的初始化,WorkerDict 的 remote 创建和调用,以及数据收发的统一管理。由于 single controller 的负载较大,官方推荐 single controller 尽可能调度在非 head 节点上。
这里最精妙的结构是 WorkerDict,它本身只是一个 Worker 的基类,也就是 RLHF 某一个模块的模型分片,但实际上它绑定了 Actor、Critic、Rollout、Ref、Reward 等所有模块的公开方法,因此可以灵活地动态指定或切换一个 WorkerDict 实际代表的模块,可以看作一个万能的 Worker。
在 WorkerDict 之上是一个名为 RayWorkerGroup 的数据结构。它主要是用于从资源组获取资源,动态指定 WorkerDict 的模块(通过 method 的重命名和 rebind 来实现)并创建 WorkerDict,同时作为任务调度器向指定的 WorkerDict 分发执行任务。
3.1. 训推模块和 backend
因为 PPO 算法对模块的需求是相同的,因此这部分的分析同 OpenRLHF。那么在 veRL 中,训练模块可以是 FSDP/HSDP 或者 Megatron,推理模块仍然是 vLLM(SGLang 应该在接入中)。
3.2. Ray 调度与 Hybrid Engine
尽管这里的副标题没有提到,但 veRL 实际上也可以做模块之间的 colocate,相比于 OpenRLHF 有限的 3 种 colocate 方式,veRL 理论上可以实现任意的 colocate 组合。从代码上看,我们可以将需要 colocate 的模块绑定到同一个 resource pool 中,然后逐个创建 resource pool 对应的模块 class。
但在实际的源代码中,veRL 目前的策略只有一种,也就是 colocate 所有模块。我个人认为,如果要在现有代码的基础上支持多种(或者任意的)colocate 策略,WorkerDict 和 RayWorkerGroup 可能要大改,至少需要考虑如何建立每个 resource group 的通信组,如何做环境变量的设置,以及如何做不同资源组之间的 method bind/rebind 等等(这块可以跟 OpenRLHF 学一学 hhhh)。
所以 veRL 主要强调的还是它的 Hybrid Engine 能力,也就是不同模块共享同一个数据结构(WorkerDict)和资源组,并且 WorkerDict 可以灵活地在多种模块、多个 engine 之间切换。这个 Hybrid Engine 的定义与 Deepspeed-Chat 非常接近。
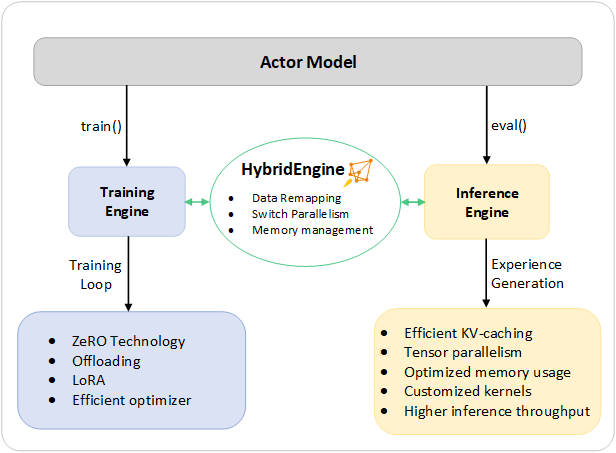
有个非常值得注意的点是,在 veRL 中 Actor 和 Rollout 是共享同一个模型权重的,因此它不需要像 OpenRLHF 一样做权重同步和 CUDA IPC 通信【更正:感谢评论区同学的指正,veRL 通过 ShardingManager 也做了模型的更新和同步,但由于 Actor 和 Rollout 是在同一个进程上的,所以也不需要做通信,此外我还抓到了 veRL 在 vLLM repo 提的 feature request】,但是原生的 vLLM 不支持直接传入模型结构/权重,所以 veRL 还对 vLLM 做了许多 patch 来适配。两种方案哪种更好呢?我觉得 OpenRLHF 实现上更加简单,可维护性和兼容性更好,而 veRL 更节省显存资源,性能上(可能)更好,只能说各有优劣吧。
接下来我们重点来看整个代码库中最 tricky 的部分,也就是如何实现 WorkerDict 的动态特性的。这部分的入口代码仅有几行:
1 | # initialize WorkerGroup |
这里 class_dict 的类型是 dict[str, RayClassWithInitArgs],前者是一个 key string,后者是一个预先保存初始化 RLHF 模块参数的包装类,取 RayClassWithInitArgs.cls就可以得到原本的 user_defined_cls。key 和 user_defined_cls 的对应关系如下:
| Key | User_defined_cls |
|---|---|
| actor_rollout | ActorRolloutRefWorker |
| critic | CriticWorker |
| ref | ActorRolloutRefWorker |
| rm | RewardModelWorker |
在 create_colocated_worker_cls中包含着 WorkerDict 的初始化逻辑:
1 | class WorkerDict(worker_cls): |
注意哦,在这里 worker_cls就是 Worker,而所有 user_defined_cls 也都继承 Worker。所以 WorkerDict 初始化过程不仅会运行一个 Worker 的完整 __init__ 函数,而且还会创建所有 user_defined_cls 并运行一个不做分布式初始化的 __init__ 函数。因此一个 WorkerDict 其实同时包含了 ActorRolloutRefWorker、CriticWorker、RewardModelWorker的所有实例。
接下来,_bind_workers_method_to_parent函数将这些 user_defined_cls 的所有被@register装饰的公开方法绑定到 WorkerDict 本身的方法中。
通过调试,我们可以看到一个 WorkerDict 绑定了哪些方法:
1 | (Pdb) p self.workers |
可以看到有一些带 actor_rollout_、critic_、ref_ 前缀的方法,这些就是新增的绑定方法。
在调用 WorkerDict 这些新增的绑定方法时,实际上是调用了ActorRolloutRefWorker / CriticWorker / RewardModelWorker对应实例的方法,WorkerDict 只是起到一个代理作用。
从 create_colocated_worker_cls 返回后,我们会将这个 WorkerDict 交给 RayWorkerGroup,在这里,除了完成 WorkerDict 的资源分配和创建之外,我们还需要额外做一个工作,那就是将 WorkerDict 新增的绑定方法再绑定到这个RayWorkerGroup上去,这个工作在 _bind_worker_method里面完成。
从代码中可以看出,RayWorkerGroup上的绑定方法具有了自由执行 dispatch、execute 和 collect 方法的功能,可以按照 @register 预先指定的数据分发、集合方案和运行方案来指配每个 WorkerDict 实际接受到/应该返回的数据,这些方案可以从 decorator.py 中找到。
我们从上至下理一下调用的先后顺序,当我们在 RayPPOtrainer 中调用RayWorkerGroup的某个绑定方法时,首先会运行数据分发逻辑(例如 broadcast 和 split),然后执行 execute 逻辑(所有 WorkerDict 都跑任务,或者只有 rank0 跑任务,等等),将任务和数据下发到每个 WorkerDict,每个 WorkerDict 在 remote 拿到数据后开始执行任务,任务执行完成后,结果被 RayWorkerGroup捕获,它随后执行数据的 collect 逻辑(reduce、concat 等),最后返回处理后的数据给 RayPPOtrainer。
那么还剩下最后一个问题,当我们调用 init_model() 时,我们怎么知道它应该调用的是 Critic 的critic_init_model 方法,还是 Ref Model 的 ref_init_model 方法呢?veRL 的处理方法是在原有RayWorkerGroup的基础上,spawn 出 4 个几乎一模一样的RayWorkerGroup,分别命名为 actor_rollout_wg、critic_wg、ref_policy_wg、rm_wg,每个 wg 对应一个 PPO 的模型。然后 veRL 对这些 spawn 出来的 wg 做了一个 rebind,其实就是重命名。例如对于 actor_rollout_wg 而言,它的 actor_rollout_init_model方法就会复制一份,重命名为 init_model,这样调用 actor_rollout_wg.init_model()就等价于调用原来那个 RayWorkerGroup的 actor_rollout_init_model方法,类似地可以对其他 wg 和绑定方法做 rebind 处理。
经过上面的一系列处理后,我们调用 actor_rollout_wg.init_model(),就可以让 remote 的所有 WorkerDict 运行 actor_rollout 的模型初始化函数了。尽管这个工程实现较为复杂,但最后的效果是能让指定的 WorkerDict 运行任何模块的公开方法,并自动处理数据分发和接受逻辑,总体而言是非常精妙的设计!
理解了这个部分,我们就可以跳出技术细节,从宏观上就可以看出,veRL在 Ray 层面的调度非常简单,就是每卡调度一个 WorkerDict 作为 Ray Actor,并让所有模块的对应分片共享这一个 WorkerDict 所分配到的资源。创建每一个 WorkerDict(本质上是 Worker)的方式和 OpenRLHF 基本一致,先创建 rank0 worker,拿到 master addr / port 后,再创建其他 worker。不过 veRL 还创建了一个 register center 用来管理这个 master addr / port,这个 center 就是一个独立的 cpu Ray Actor。
3.3. Data/Control Flow
veRL 采用的 single control 设计将控制逻辑集中在 RayPPOTrainer 里面,首先运行了 init_workers初始化 WorkerDict 及每个模块的模型分片,而 fit 部分就是 PPO 算法的主体逻辑了。RayPPOTrainer里面所有与 wg 相关的 method 调用,都可以参考上面整理的思路来 trace 它的实际运行步骤。PPO 算法部分就留给大家自行阅读了~
4. 总结与评价
到这里我们总结一下 OpenRLHF 和 veRL 两大框架,然后穿插着我的一些个人观点来讲吧~
- 模块设计和 Backend
这个部分两个 RL 框架的设计大同小异,PPO 训练的各个主体都有单独的模块和调用方法,同时每个主体的训推 pipeline 一定程度上都是互相独立的。主要区别在于 veRL 可以兼容并扩展多种训推后端,并且可以任意组合,例如 FSDP/Megatron + vLLM/SGLang。
实际上我在开发训练框架的时候,也提到过 veRL 的这种兼容多 backend 的思想,具体来说是让用户在配置文件中仅修改一个 backend 参数,就能在 Deepspeed、Megatron、torchtitan(或者叫 torch native dist training)以及其他训练引擎之间任意切换。要统一各种引擎的训练接口以及训练精度,还是一个庞大的工程项目呢~(但愿我们能够做成hhh
- Ray 调度和资源管理
两个框架起 Ray Worker 和分配资源的方式有些微的区别:OpenRLHF 是每个模型都起一组 worker,只不过不同模型间对应 rank 的 worker 共享同一个 placement group 的 bundle;而 veRL 是直接让几个模型共生于一个 WorkerDict 里面了,自然也是共享了资源。我个人比较喜欢第一种方案,因为简单明了,veRL 的方法多多少少有点 tricky 了,为了实现这个“共生体”在工程上可费了不少劲。
Colocate/Hybrid Engine 以及类似的功能还是非常有必要的,一方面,在 RL 这种模型之间存在 pipeline 有强依赖的任务上,如果资源隔离就容易导致 A 在跑但 B 在等待,B 在跑 A 又不动了,让 A、B 资源共享就不至于让 GPU 闲置。另一方面,如果任务编排和显存 offload 策略得当,让模型间资源共享,是可以将投入产出压榨到极致的(要知道 RL 训练对 GPU 资源的需求普遍较高),这有利于推动 RL 训练的民主化呀!
- Data flow 与 Control flow
相比于如何理清各个模块之间的关系,写出正确的 data flow 和 control flow,我其实更关心这两个 flow 应该运行在何处,因为它直接影响整个系统的性能表现。OpenRLHF 将这两个 flow 都集中在 Actor 所处的 workers 上,Actor worker 同时承担计算、数据分发和任务调度等工作,因此 Actor 很可能是整个系统的性能瓶颈。相对而言,veRL 将主体的控制逻辑和数据传输集中在 single controller 这个中枢上,而将每个个体的主观能动的逻辑交由它们自行处理,也许是性能上更好的策略。从代码可读性和扩展性上说,这种统一管理的方式也比较有优势吧。
另外一个需要关注的点是,两大框架的许多数据传输都依赖于 Ray 的 Object Store,但一旦通信的数据量非常大,序列化和反序列化的时间会显著变长,同时 GPU 和 CPU 之间的来回拷贝也较为耗时,这在一些传递大 Tensor 的场景下(比如蒸馏场景下的 logits 等)会有明显的性能瓶颈。如果能将大 Tensor 的通信替换为 NCCL 或 IPC 通信,并充分利用 Ray 的异步性(运用 Double Buffer 等技巧),我觉得还有大量潜在的性能提升空间。当然要做到这些,那么如何管理显存资源,如何处理数据传输的存放位置,甚至可能要考虑如何动态做 offload/onload,在工程上都要花时间来处理。