异步RL框架AReaL
异步RL框架AReaL
https://www.zhihu.com/question/1890112252100703430/answer/1890177974956970468
转自:https://zhuanlan.zhihu.com/p/1916441720817714438
一、异步的含义
在本文接下来的表达中,我们用**trainer(后端是deepspeed/fdsp/megatron等)**和 **rollout(后端是sglang/vllm等)**等来分别指代RL训练中做【训练】和【生成】的两个后端。
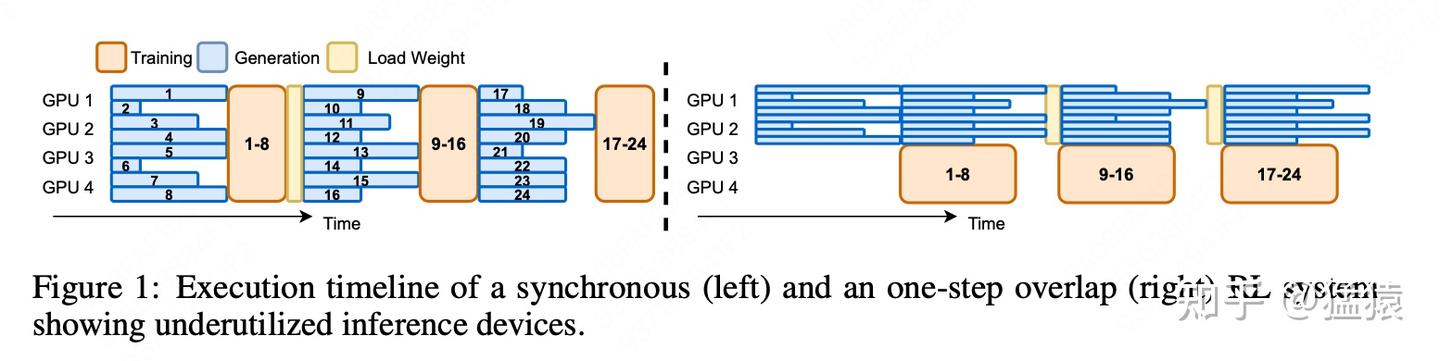
figure1的左图刻画了【同步RL训练】的流程,具体来说:
- 假设初始时刻actor的权重为 θ0
- rollout使用θ0 ,吃一批prompt,生成对应的response。这批数据中的“每一条”都生成完毕后,rollout停止工作
- trainer使用θ0 ,接收这批(prompt, response)数据,进一步生成exp值,进行训练,更新权重为 θ1
- trainer将θ1 发送给rollout,rollout使用 ,重复上面的过程
显而易见,【同步RL训练】存在以下2个问题:
- 在rollout内部,序列长短不一,对长序列的处理时间成了整个rollout的卡点(短序列早就生成完了,却还要继续等长序列)
- 在rollout和trainer之间是没有overlap的。即rollout工作的时候,trainer闲着,反之亦然。这进一步引起了gpu的空转和训练低效的问题。
figure1的右图刻画了【1步异步RL训练】的流程,具体来说:
- 假设初始时刻actor的权重为θ0
- rollout使用θ0 ,吃一批prompt,生成对应的response。这批数据中的“每一条”都生成完毕后,将数据同步给trainer,但此时rollout继续使用θ0 为下一批prompt做生成。
- 在rollout使用θ0 为第二批数据做生成的同时,trainer开始用第一批数据进行训练
- trainer训练完毕,将 θ0 更新至 θ1,它将 广播给rollout,rollout使用这个权重做第三批数据的生成,以此类推。
- 通过这种方式,尽可能实现rollout和trainer间的overlap,但并没有解决rollout内部训练时的低效问题(overlap的程度受到rollout和trainer运行的相对速度的影响,例如在上例中,假若trainer训练相对慢,那么它将 广播给rollout时,rollout可能已经吃了好几批数据了。)
综上,AReaL提出的方法,是希望同时【消灭rollout内的bubble】和【让rollout和trainer尽量overlap】,它的运作流程如下:
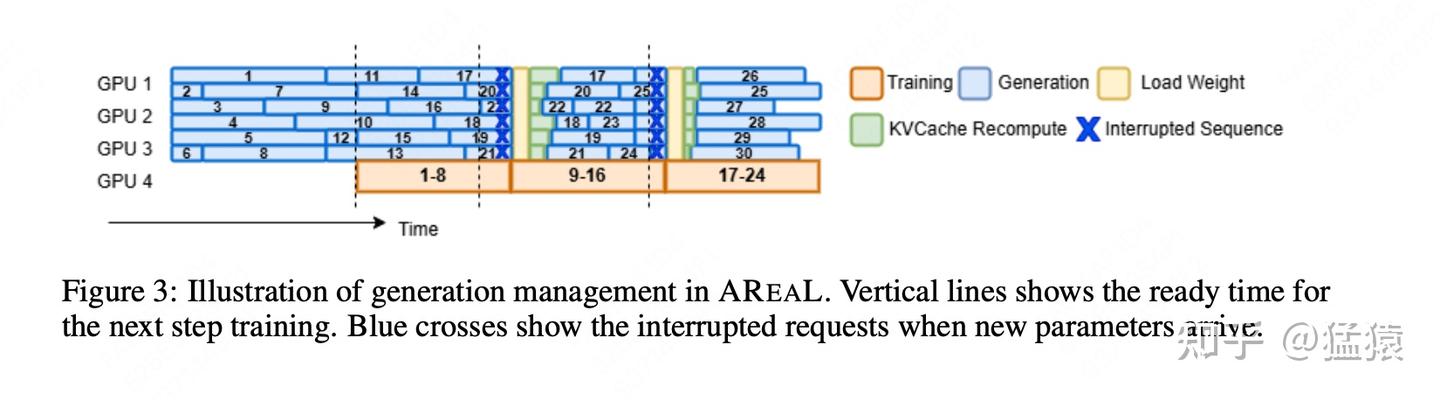
我们直接从trainer将权重从 更新到 的这个时刻谈起,也就是figure3中training1-8结束的位置:
- 首先,在trainer执行θ0 ->θ1 的这个训练过程中,rollout继续用θ0 做生成
- trainer将权重更新至θ1 ,并将该权重广播给rollout,rollout收到需要update_weights的信号,立刻停止手头的工作。假设此时rollout手头有一条seq0,它生成了部分response,我们记为
(prompt, response0),那么它就把这个结果保存下来,同时清空和执行θ0相关的kv cache。 - rollout使用θ1 做完权重更新,它现在将把
(prompt, response0)视为一个全新的prompt,利用它继续从prefill阶段开始做生成,我们假设它生成了(prompt, response0, response1)。 - 也就是说,最终当一条seq进入trainer开始训练时,它的构成可能是
(prompt, response0, response1,... responseN),不同的response是由不同的权重θ生成的。
通过这样的方式,在rollout内部,我们就不需要让短序列去等长序列了。你可以向rollout阶段发送比实际训练时更大的batch_size,这样只要rollout吐出了满足一个训练batch的数据,trainer就能直接工作。更细节的infra流程参见下图,这里大家可以自行读论文,就不再赘述了:
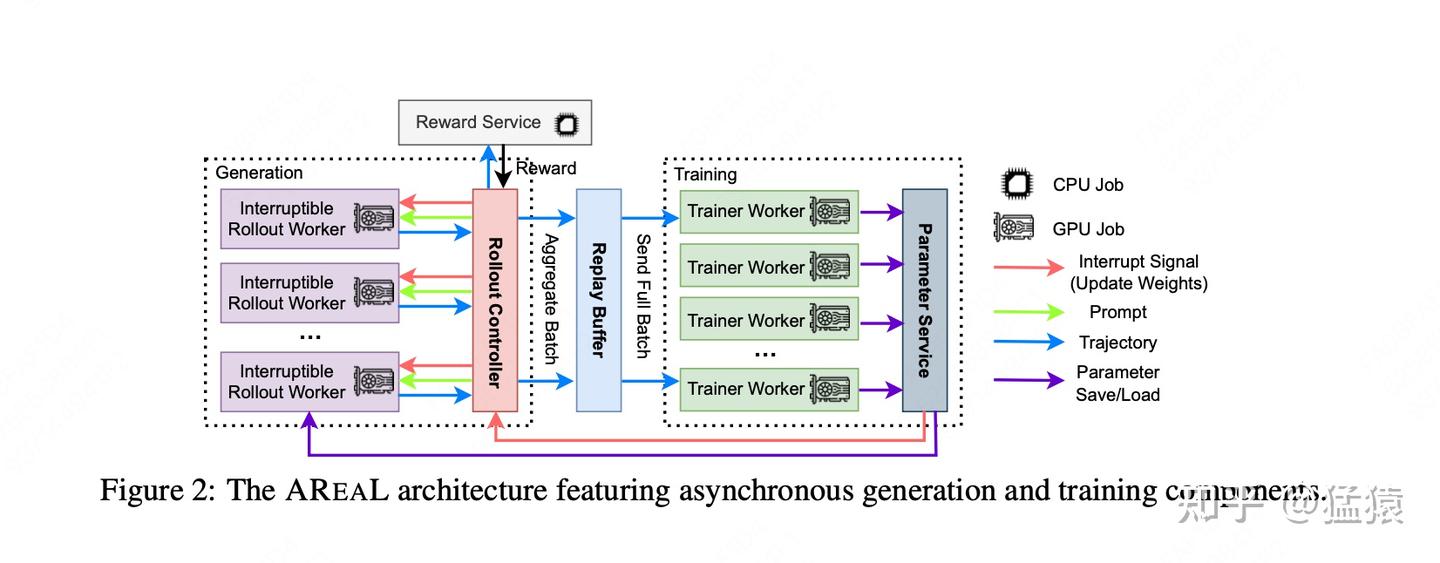
trajectory轨迹
二、decouple PPO:让异步训练更加稳定
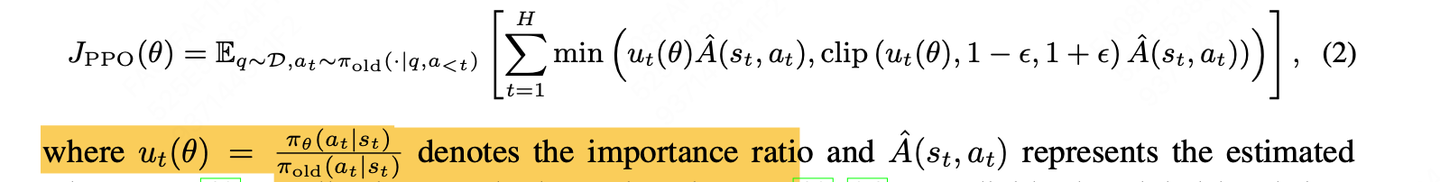
先来回顾一下传统PPO的actor loss,参见上面的公式(2)。在同步RL中,一个seq的response一定来自同一个actor权重,也就是公式中所说的πold 。 限定了actor模型更新中的trust region。
但是在异步中,当一条seq最终进入trainer开始训练时,它的构成可能是(prompt, response0, response1,... responseN),不同部分的response是由不同的权重生成的,那这个 πold要怎么计算呢?
(1)使用若干个权重分次对1条数据做response生成,可以等价于使用某个权重1次性对这条数据做生成。
我们知道 πold 即代表logP,当一条数据的组成是(prompt, response0, response1,... responseN)时,各个responses部分对应的logP即是用生成它的那个权重计算出来的。而(1)中说的这个性质,即是在证明,你可以从抽象的意义上找到一个“统一”的权重,让这条数据看起来就像是这个“统一”的权重生成的一样。这个相关证明在文中的proposition1。有了这个证明,即使本质上这些logP来自不同的权重,你也可以将其视为来自某个抽象的 πold ,也就是不干扰公式(2)的逻辑。
(2)decouple ppo:构造更稳定的trust region
虽然(1)已不是问题,但现在新的问题来了: πold的目的是限定trust region,以便让整个ppo的训练更加稳定,所以一般 πold 不会和当前待更新的πθ 差距太远。但是现在,对于(prompt, response0, response1,... responseN),明显越往前的response,它的权重和 πθ相距甚远,也就是本身来说,用这种混合的 构造出来的trust region,就是“不可信的”,那更不要提后面PPO训练的稳定性问题了。
所以,有没有办法构造一个更“可信”的trust region?例如,我还是找一个和πθ 差距不大的权重(假设我称呼其为 πprox),用它来构造trust region,可以吗?
现在我们做一些符号的转换,在同步PPO中,我们把一以贯终的用于生成的权重称为πold 。那么在异步PPO中,我们就称呼这个“多段”权重为πbehave (意思是本质上logP由不同的权重生成,但不妨碍你将其统一为一个 πbehave),那么:
- 不做任何处理的情况下,

- 现在我们想重构trust region,我们想引入一个和πθ 更相似的πprox ,则我们考虑这样改写: ,注意,改写后和上面的公式仍然是等价的,改写的目的是decouple掉 πθ 和 πbehave间的依赖关系,引入πprox (这个是我自己对decouple的理解,不确定对不对)
- 现在把改写后的结果带入原始PPO的公式中,也就是上面的公式(2)中,再做一些转换,我们得到:
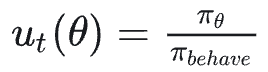
 ,注意,改写后和上面的公式仍然是等价的,改写的目的是decouple掉 πθ 和 πbehave间的依赖关系,引入πprox (这个是我自己对decouple的理解,不确定对不对)
,注意,改写后和上面的公式仍然是等价的,改写的目的是decouple掉 πθ 和 πbehave间的依赖关系,引入πprox (这个是我自己对decouple的理解,不确定对不对)
观察公式(5),可以发现trust region已经被改写,换成了πprox **。**但是,由于这种等价替代的逻辑,当你在不clip的情况下,算公式(5)对θ 的梯度时,你会发现这个梯度和原始PPO(公式(2))求出来的梯度是一致的。也就是本质上,这里只是控制了actor的更新时机(在新的、更可靠的trust region内),但不会改变触发更新时actor的更新方向和程度。
最后,在当前AReaL实践中,behave相关的logP由rollout后端计算,其余两者由trainer后端计算,由于不同框架间存在的精度差异,这里会存在精度对不上的问题。这个后续再看看框架是如何解决的。