TD lamda和GAE
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Roger-Lv's space!
相关推荐
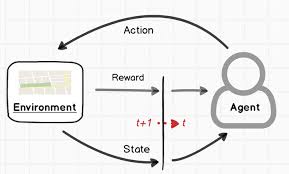
2024-09-11
RLHF
RLHF 从零实现ChatGPT——RLHF技术笔记 - 知乎 (zhihu.com) 一文读懂「RLHF」基于人类反馈的进行强化学习-CSDN博客 大模型 | 通俗理解RLHF基础知识以及完整流程-CSDN博客
2024-09-11
强化学习笔记
强化学习笔记 强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO-CSDN博客

2025-08-14
Qwen3技术报告解读
Qwen3技术报告解读 转自:https://zhuanlan.zhihu.com/p/1905926139756680880 模型架构 Qwen3系列,包括6个Dense模型,分别是Qwen3-0.6B、Qwen3-1.7B、Qwen3-4B、Qwen3-8B、Qwen3-14B和Qwen3-32B;2个MoE模型,分别是Qwen3-30B-A3B和Qwen3-235B-A22B。 Qwen3 Dense模型的架构与Qwen2.5相似,包括GQA、SwiGLU、RoPE以及RMSNorm with pre-normalization。此外,移除了Qwen2中使用的QKV偏置,并在注意力机制中引入了QK-Norm,以确保Qwen3的稳定训练。 Qwen3 MoE模型采用了细粒度专家分割,共有128个专家,激活8个专家。但与Qwen2.5-MoE不同,Qwen3-MoE去除了共享专家。同时,采用了全局批次负载平衡损失。 预训练 预训练数据共36T Tokens,包含119种语言和方言,涉及代码、STEM、推理任务、书籍、合成数据等。 其中,有部分数据是Qwen2.5-VL模型对...
2025-08-14
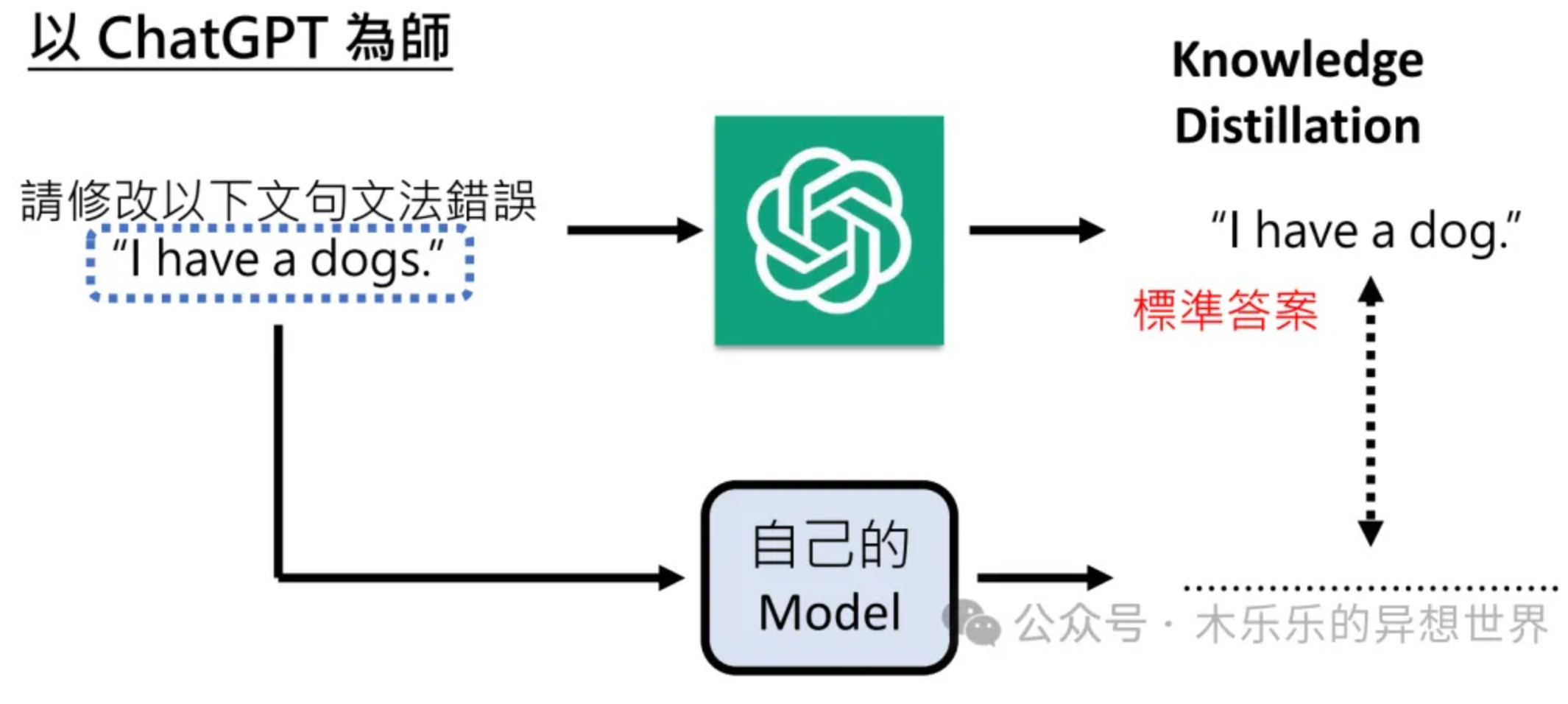
大模型蒸馏技术
导读 在人工智能快速发展的今天,模型的规模越来越大,计算成本也越来越高,这对中小型开发者来说无疑是一个巨大的挑战:如何通过将大模型的知识和能力浓缩到更小、更轻量化的模型中,降低硬件要求,以更低的成本享受到先进的人工智能技术? DeepSeek-R1及其API的开源标志着这一领域的重要突破。 对于中小型开发者而言,这意味着他们不再需要依赖庞大的计算资源就能实现高效、强大的人工智能应用。DeepSeek提供的开源蒸馏检查点(如基于Qwen2.5和Llama3系列的1.5B、7B、8B等参数规模)为开发者提供了丰富的选择空间,无论是初创公司还是个人项目,都可以根据自身需求灵活调用这些模型。 github 地址:https://github.com/deepseek-ai/DeepSeek-R1 这一技术不仅降低了人工智能的准入门槛,也为中小型开发者在资源有限的情况下实现创新提供了更多可能性。通过蒸馏模型,他们可以更专注于业务逻辑和应用场景的优化,而无需过多关注底层计算资源的限制。这无疑将推动人工智能技术在更广泛的领域中落地生根。 接下来,详细跟大家聊聊模型蒸馏。 一、为什么...
2025-08-13
基于 Ray 的分离式架构:veRL、OpenRLHF 工程设计
基于 Ray 的分离式架构:veRL、OpenRLHF 工程设计 转载:https://zhuanlan.zhihu.com/p/26833089345 在 RL、蒸馏等任务中需要多个模型协同完成计算、数据通信、流程控制等工作。例如 PPO 及各类衍生算法中,就需要管理 Actor、Rollout、Ref、Critic、Reward 等最多 5 类模块,每类模块还承担着 train、eval、generate 其中的一种或多种职责,而蒸馏任务中也存在着多组 Teacher 和多组 Student 共同蒸馏的场景。 如果我们仍然采用 Pretrain、SFT 训练这种基于单脚本多进程的运行模式(通过 deepspeed、torchrun 等命令启动任务),是难以实现灵活的任务调度和资源分配策略的。而 Ray 提供的 remote 异步调用和 Actor 抽象,可以让每个模块有独立的运行单元和任务处理逻辑,这种分离式架构使之天然适配多模型之间的频繁交互和协同工作的场景。 这篇文章以当今最为流行的两个 RL 框架 veRL 和 OpenRLHF 为例,从工程角度分析这两个框架的特点和优...

2025-08-20
UloRL:An Ultra-Long Output Reinforcement Learning Approach for Advancing Large Language Models’ Reasoning Abilities
UloRL:An Ultra-Long Output Reinforcement Learning Approach for Advancing Large Language Models’ Reasoning Abilities 论文链接:https://arxiv.org/pdf/2507.19766 转自:https://zhuanlan.zhihu.com/p/1932380821412638989 得益于Test-time Scaling的成功,大模型的推理能力取得了突破性的进展。为了探索Test-time Scaling的上限,我们尝试通过强化学习来扩展模型输出长度,以提升模型的推理能力。然而,强化学习在处理超长输出时面临两个问题:1) 由于输出长度的长尾分布问题,整体的训练效率低下;2) 超长序列的训练过程中会面临熵崩塌问题。为应对这些挑战,我们对GRPO做了一系列优化,提出了一个名为UloRL的强化学习算法。在Qwen3-30B-A3B的实验表明,通过我们的方法进行强化训练,模型在AIME-2025上由70.9提升到85.1,在BeyondAIME上由50.7提升...
评论




