无标题
Value-Based RL中offline policy、off-policy、on-policy
如何区分强化学习中的「在线/离线」与「同策略/异策略」 这两组概念?
https://www.zhihu.com/question/1923492665154049281/answer/1923493513200378057
https://www.zhihu.com/question/627726012/answer/3613730093
https://www.zhihu.com/question/627726012/answer/3613730093
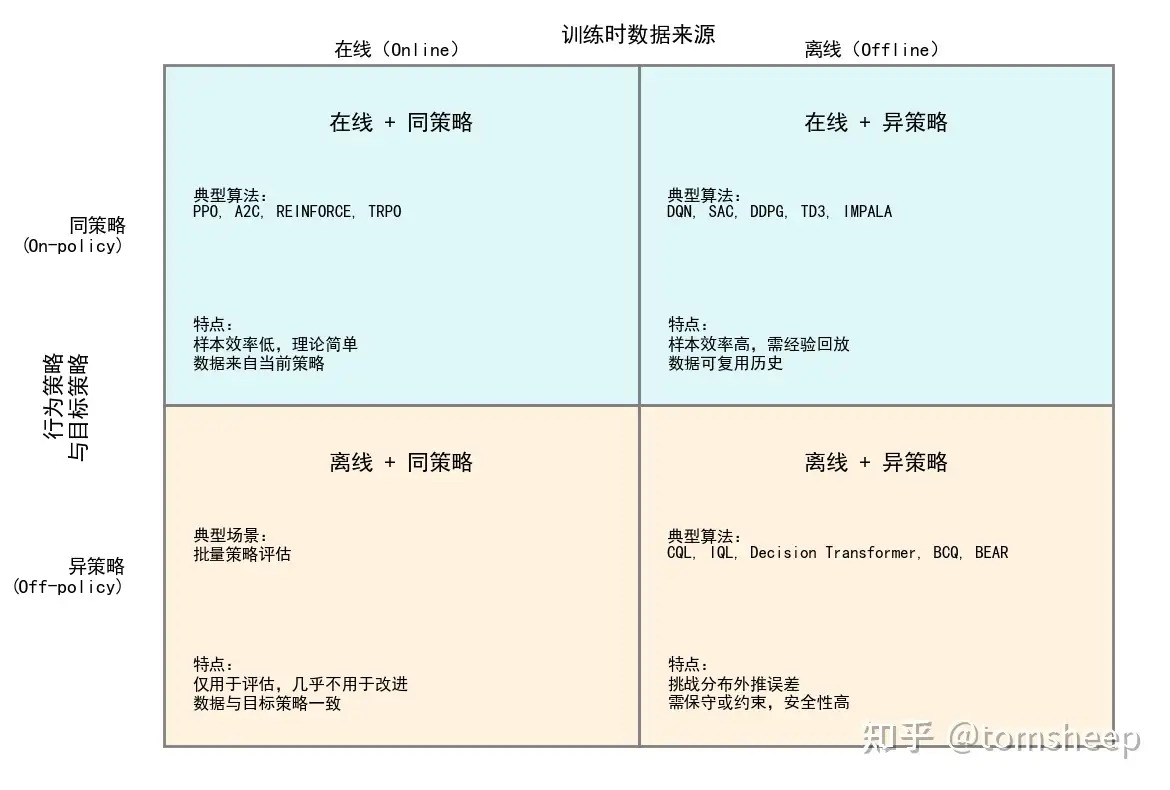
offline policy:
也叫Batch RL或者Offline RL
使用条件:在实时互动与环境成本高昂或者危险的情况下使用,或者当有大量现有数据可用时(比如要train一个真实的机器人,每次尝试都可能导致机器人受损,就可以使用模拟器收集大量的行走数据)。
- 实际上就是从一个静态的数据集去学习,不与环境交互(所以叫离线)
- 没有exploration
缺点:
- agent不能实时地从其行动中学习
- 需要一个高质量、大型的数据集
- 存在过拟合的风险、因为agent只能学习在数据集中存在的那些场景
那这样offline policy和监督学习的区别是?
off-policy:
- 从off-policy的data中学习,生成off-policy的data的策略可以不是当前正在学习的策略,与环境互动(从一个策略搜集的策略来学习另一个策略)
- 隐性要求的exploration
- 经验回收:用行为策略收集经验,把(st、at、rt、st+1)的四元组记录到一个数组里面,之后反复利用这些策略去更新目标策略(这个数组叫做replay buffer)。这种方法只适用于off-policy,因为收集经验时所用的策略不同于想要训练出的目标策略。
其缺点是:
- 采样效率:off-policy学习使用的旧数据可能会导致学习的效率降低,因为并不是所有的旧数据都对当前的策略有用
- 学习稳定性:由于off-poliy学习使用的数据可能来自不同policy,可能会导致训练不稳定。所以其需要额外的技巧,比如DQN,采用target network和evaluate network来探索Q value和评估Q value
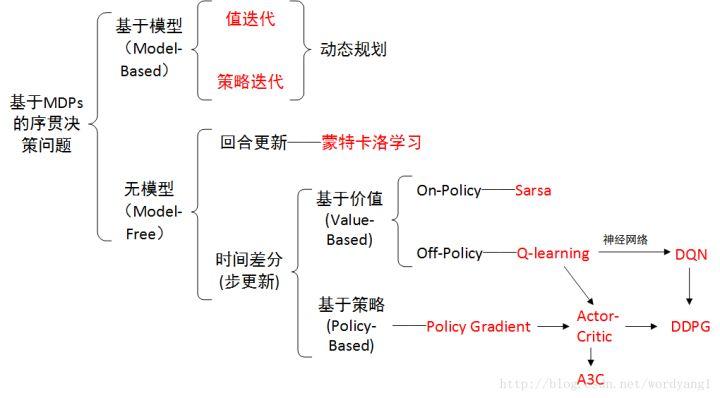
DQN
其实是属于异策略的在线学习
https://zhuanlan.zhihu.com/p/145102068
https://zhuanlan.zhihu.com/p/630554489
Q-Learning---->DQN:https://zhuanlan.zhihu.com/p/35882937
主要Q表是离散的->状态空间过大->zhihanshujinsi
DQN将Q表->Q Network(学的是这个reward)
这里的初始样本训练样本好说,通过epsilon-greedy策略去生成就好。
两个网络
经验回放 experience policy
on-policy:
https://www.zhihu.com/question/56561878/answer/1897473503747344282
数据必须由当前策略
生成,更新公式依赖轨迹分布 dπ(s)d^\pi(s) :
例如,机器人必须用当前“笨拙”动作采集的数据学习行走。
优劣对比:
-
数据效率的理论边界:
-
当动作空间A较大时,off-policy的样本复杂度上界更低:
-
on-policy:
-
off-policy:
-
-
-
收敛稳定性分析:
-
on-policy的天然优势:由于数据分布与当前策略严格一致,由于数据分布 dπ(s)d^\pi(s) 与当前策略严格一致,策略梯度估计的方差更小:
其中 ρ=πθ/πb 为重要性权重,当新旧策略差异大时会产生方差爆炸。
-
Wasserstein距离
Wasserstein距离是指一种衡量两个概率分布之间差异的方法,也称为最优传输距离或地球移动者距离。Wasserstein距离的数学定义是将一个分布“搬运”成另一个分布所需的最小成本,其中成本是基于两个分布之间样本点的移动距离来计算的。
压缩映射原理
https://zhuanlan.zhihu.com/p/630990671
Lipschitz条件
https://zhuanlan.zhihu.com/p/442896922




