KL散度
KL散度
🧩 KL散度公式解析
图片中的KL散度公式为:
🔍 关键参数解释
-
π_θ和π_ref(核心参数)π_θ: 当前策略模型- 带参数θ的神经网络(例如PPO正在训练的策略)
- 策略的数学表示:
π_θ(y|x)= 在状态x下选择动作y的概率 - 动态更新:通过梯度下降不断优化
π_ref: 参考策略模型- 通常表示旧的或冻结的策略版本
- 在PPO中,通常指上次参数更新前的策略
- 保持固定:在每次训练迭代中不变
- 物理意义:KL散度衡量的是 当前策略(π_θ) 相对于参考策略(π_ref) 的变化程度
-
(y|x)(策略条件)x: 当前状态/观察输入- 例如:机器人传感器数据,游戏画面像素等
y: 要选择的动作- 例如:机器人的关节控制指令,游戏中的按键操作
- 整体含义:表示在给定状态
x下采取动作y的概率分布
-
D_KL(π_θ||π_ref)(核心概念)-
非对称性:
D_KL(P||Q) ≠ D_KL(Q||P)在PPO中的物理意义:
-
计算值表示:用π_ref的编码系统描述π_θ时,平均需要的额外信息量(单位为nats)
-
-
期望形式(右半部分)
E_{y∼π_θ}: 表示从当前策略π_θ采样动作y的期望- 物理意义:在当前策略产生的动作分布上,评估新旧策略的概率比值的对数期望
⚙️ 在PPO中的具体作用
| 方面 | 解释 |
|---|---|
| 目标 | 防止策略更新过大导致崩溃 |
| 实现方式 | 在损失函数中加入KL惩罚项: |
L_total = L_policy - β * D_KL(π_θ‖π_ref) |
|
| β (beta) | 调节KL惩罚强度的超参数 |
| 过大→策略更新保守,过小→可能更新过度 | |
| 工作流程 | 1. 收集经验 2. 冻结π_ref=当前策略 3. 多次更新π_θ 4. 当KL>阈值时停止更新 |
📊 直观理解:KL散度就像给策略更新加了一个"安全带",确保新策略不会突然偏离旧策略太远,导致训练不稳定。在微调语言模型时(如RLHF),这相当于约束新模型不要过度偏离原始基础模型的行为特征。
需要进一步说明的是:PPO中的实际实现通常用概率比值的裁剪(Clipped Surrogate Objective)替代直接的KL惩罚,但KL散度仍是理解策略约束的核心数学基础。
均方差和均方误差:https://zhuanlan.zhihu.com/p/673342488
KL散度恒大于0,靠琴生不等式来推(凸函数的期望>=期望的函数)
反映了凸函数“向上弯曲”的特性:连接两点的弦总在函数图像上方。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Roger-Lv's space!
相关推荐

2024-09-05
两万字讲清楚:现在的AI产品有多难做?
两万字讲清楚:现在的AI产品有多难做? https://mp.weixin.qq.com/s/pMt_VMs6uq5wsPPscOyefA 这篇文章深入探讨了AI产品经理在处理大型AI模型时应该考虑的关键问题和机遇。 1. 关注API而非仅仅是产品 核心观点:产品经理应该深入理解大模型的API,因为这是模型能力的直接体现。产品的最终形态往往是API能力的延伸,但可能会因为各种工程限制而与API的能力有所差异。 实际意义:了解API的能力和限制可以帮助产品经理更准确地设计产品功能,避免过度依赖模型无法实现的功能。 2. AI与移动互联网的类比不恰当 核心观点:简单地将AI技术应用到所有应用中并不是一个有效策略。只有那些真正能够从AI中获得显著优势的应用才应该进行AI重构。 实际意义:这要求产品经理进行深入的需求分析和成本效益分析,以确定AI的投入是否真正值得。 3. 产品经理需要学会调用API 核心观点:产品经理应该具备直接与AI模型交互的能力,这有助于更好地理解模型的能力和局限。 实际意义:这种能力可以帮助产品经理在产品开发过程中做出更准确的决策,并能够快速迭代产品以适...
2024-09-05
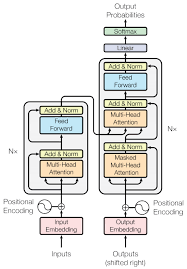
Transformer解析
Transformer解析(Attention Is All You Need) 【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客 Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili 【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客 大模型面试准备(十二):深入剖析Transformer - 残差连接和层归一化_残差层和归一化层-CSDN博客 Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT-CSDN博客 “Attention Is All You Need” 是一篇由 Ashish Vaswani 等人撰写的论文,发表于 2017 年的 NeurIPS 会议上。这篇论文提出了 Transformer 模型,Transformer是一种用于自然语言处理(NLP)和其他序列到序列(sequence-to-sequence)任务的深度学习模型架构。Transformer架构引入了自注意力机制(self-attention mechanism),这是一个...
2024-09-05
大模型学习路线
大模型学习路线 现在门槛降低了,成本也降低了。大模型技术爆发,抓住机会。 开源大模型(离线,更安全)/在线大模型 微调:Lora->垂类 适用于用户意图识别 RAG:检索增强生成(一系列专家,提升表现幅度,降低幻觉) 只要提供了正确答案,大概率就不会答错 适合私有数据库 所以依赖于提供的数据库的信息,对数据质量要求比较高 推理更加缓慢(低于微调) 对知识库构建/信息压缩排名等(并非深度学习方面,需要深度学习算法工程师进行辅助) 提示词工程 【AI大模型】Prompt 提示词工程使用详解_大模型prompt的用法详解-CSDN博客 预训练:创造出属于自己的全新大模型 需要算力最多(微调其次,RAG和提示词工程对于算力的要求就没那么高) agent->担任80%脑力工作 一些课程 NLP FudanNLP/nlp-beginner: NLP上手教程 (github.com) 自然语言处理的入门练习 深度学习 跟李沐学AI的个人空间-跟李沐学AI个人主页-哔哩哔哩视频 (bilibili.com) 动手学深度学习 论文精读 https://...
2024-09-10
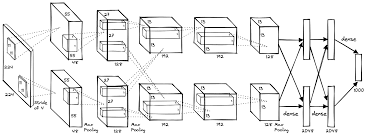
AlexNet解析
AlexNet解析 卷积神经网络经典回顾之AlexNet - 知乎 (zhihu.com) AlexNet论文逐段精读【论文精读】_哔哩哔哩_bilibili 饱和:saturating 非饱和:non-saturating
2024-09-10
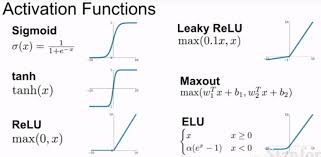
饱和(saturating)和非饱和(non-saturating)的激活函数
饱和(saturating)和非饱和(non-saturating)的激活函数 在神经网络中,激活函数是决定网络能否学习复杂模式的关键因素之一。激活函数的选择会影响网络的收敛速度、性能以及最终的泛化能力。激活函数可以根据其输出特性被分为“饱和”(saturating)和“非饱和”(non-saturating)两大类: 饱和激活函数(Saturating Activation Functions) 定义: 饱和激活函数是指当输入值增大或减小时,函数的输出值会达到一个上限或下限,并在该范围内趋于稳定,不再随输入的增加而显著变化。 特点: 输出值存在一个明显的上限和下限。 当输入值增大到一定程度后,输出值不再显著增加(或减少)。 例子: Sigmoid 函数:[ \sigma(x) = \frac{1}{1 + e^{-x}} ] Tanh 函数(双曲正切函数):[ \tanh(x) = \frac{2}{1 + e^{-2x}} - 1 ] ReLU 函数(Rectified Linear Unit)在正区间内是非饱和的,但在负区间内是饱和的。 影响: ...
2024-09-10
常用激活函数
常用激活函数 激活函数汇总_高斯激活函数-CSDN博客 常用的激活函数合集(详细版)-CSDN博客 重点关注ReLU(max(0,x)),Sigmoid(0-1),Softmax(0-1概率) 神经网络之softmax(作用,工作原理【示例说明】,损失计算)_softmax层-CSDN博客 预处理直接做原始图片 (224 * 224 * 3)
评论




