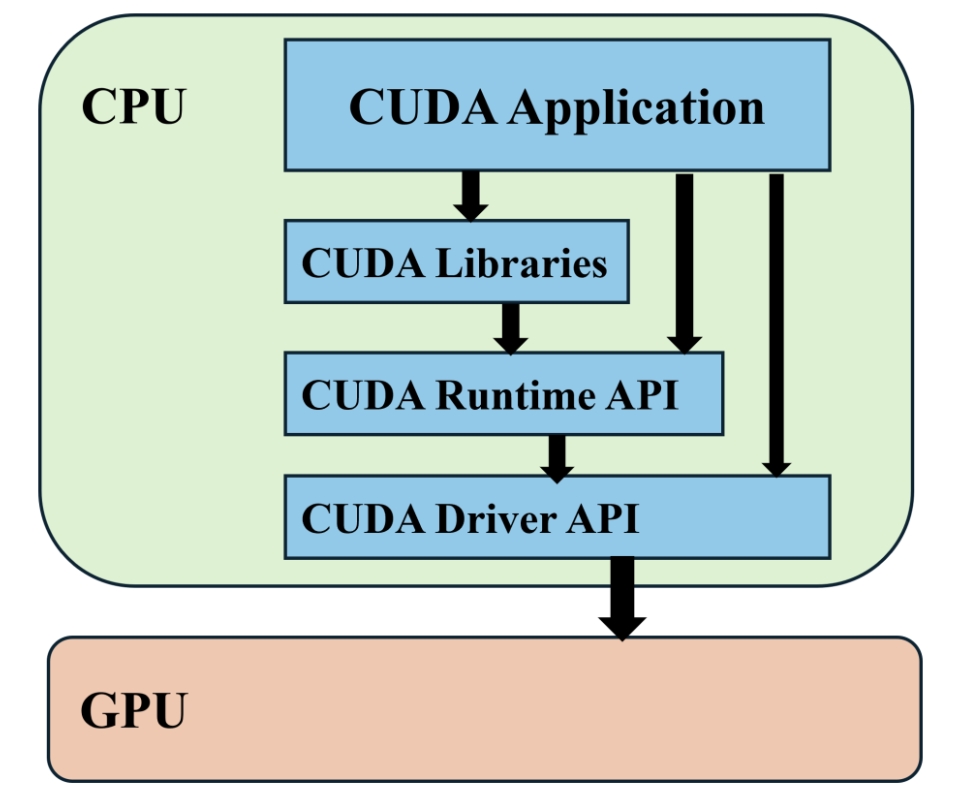
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
| func (s *Server) GetGpuPidPods(req *v1alpha1.GetGpuPodsRequest) (map[string]*v1alpha1.Pods, map[string]*v1alpha1.GpuInfo, error) {
if ret := nvml.Init(); ret.String() == "ERROR_LIBRARY_NOT_FOUND" {
s.logger.Errorf("return error: %s \n", ret.String())
return nil, nil, fmt.Errorf(ret.String())
}
defer nvml.Shutdown()
containerIdPidMap := make(map[string][]int)
pidContainerIdMap := make(map[int]string)
GpuPods := make(map[string]*v1alpha1.Pods)
GpuInfos := make(map[string]*v1alpha1.GpuInfo)
ctx := namespaces.WithNamespace(context.Background(), s.ContainerdNamespace)
tasks, err := s.taskClient.List(ctx, &tasksapi.ListTasksRequest{
Filter: "status==running",
})
if err != nil {
return nil, nil, err
}
s.logger.Infof("task=container num:%d", len(tasks.Tasks))
for _, process := range tasks.Tasks {
var pids []int
s.logger.Infof("pid:%d,containerID:%s,ID:%s", process.Pid, process.GetContainerID(), process.GetID())
containerProcesses, err := s.taskClient.ListPids(ctx, &tasksapi.ListPidsRequest{
ContainerID: process.GetID(),
})
if err != nil {
continue
}
for _, p := range containerProcesses.Processes {
pids = append(pids, int(p.Pid))
pidContainerIdMap[int(p.Pid)] = process.GetID()
s.logger.Infof("pid:%d, containerID:%s", p.Pid, process.GetID())
}
containerIdPidMap[process.GetID()] = pids
}
gpuNum, ret := nvml.DeviceGetCount()
s.logger.Infof("get count ret : %s", ret.String())
if ret != nvml.SUCCESS {
s.logger.Errorf("Failed to get GPU count: %s", ret.String())
return nil, nil, fmt.Errorf(ret.String())
}
fmt.Printf("gpu num:%d\n", gpuNum)
containerPods, err := s.getContainerPodsFromController(req.WorkerId)
if err != nil {
return nil, nil, err
}
for i := 0; i < gpuNum; i++ {
device, ret := nvml.DeviceGetHandleByIndex(i)
s.logger.Infof("getbyindex: %s", ret.String())
if ret != nvml.SUCCESS {
continue
}
uuid, ret := device.GetUUID()
if ret != nvml.SUCCESS {
continue
}
s.logger.Infof("get UUID: %s", uuid)
process, ret := device.GetComputeRunningProcesses()
if ret != nvml.SUCCESS {
continue
}
name, ret := device.GetName()
if ret != nvml.SUCCESS {
continue
}
usage, ret := device.GetUtilizationRates()
if ret != nvml.SUCCESS {
continue
}
gpuInfo := v1alpha1.GpuInfo{
GpuName: name,
Uuid: uuid,
UsageGpu: usage.Gpu,
}
GpuInfos[uuid] = &gpuInfo
for _, p := range process {
pidName, _ := nvml.SystemGetProcessName(int(p.Pid))
s.logger.Infof("Process ID: %d, Process name: %s, UUID: %s, Name: %s, GPUusage:%v MiB, GPUInstanceID:%v. ", p.Pid, pidName, uuid, name, p.UsedGpuMemory/(1024*1024), p.GpuInstanceId)
if containerID, exist := pidContainerIdMap[int(p.Pid)]; exist {
s.logger.Infof("pid: %v,containerID: %v", p.Pid, containerID)
if podName, exist := containerPods[containerID]; exist {
s.logger.Infof("containerID: %v,podName:%v", containerID, podName)
gpuPods := v1alpha1.PidPods{
Pid: p.Pid,
ProcessName: pidName,
UsedGpuMemory: p.UsedGpuMemory / (1024 * 1024),
Pod: podName,
}
if _, exists := GpuPods[uuid]; !exists {
var pidpod v1alpha1.Pods
GpuPods[uuid] = &pidpod
}
GpuPods[uuid].PidPods = append(GpuPods[uuid].PidPods, &gpuPods)
}
}
}
}
return GpuPods, GpuInfos, nil
}
func (s *Server) GetGpuPods(ctx context.Context, req *v1alpha1.GetGpuPodsRequest) (*v1alpha1.GetGpuPodsResponse, error) {
GpuPods, GpuInfos, err := s.GetGpuPidPods(req)
if err != nil {
return nil, err
}
return &v1alpha1.GetGpuPodsResponse{
GpuPods: GpuPods,
GpuInfos: GpuInfos,
}, nil
}
func (s *Server) getContainerPodsFromController(containerIDPodName string) (map[string]string, error) {
containerPods := make(map[string]string)
err := json.Unmarshal([]byte(containerIDPodName), &containerPods)
if err != nil {
return nil, fmt.Errorf("failed to unmarshal JSON: %w", err)
}
return containerPods, nil
}
type PidContainerID struct {
Pid int
ContainerID string
}
|