CUDA容器化&Container runtime相关技术梳理
CUDA容器化&Container runtime相关技术梳理
整体结构
CUDA API体系

CUDA Driver API:GPU 设备的抽象层,通过一系列 API 直接操作 GPU 设备,性能好,但编程难度高(需要显式进行device初始化以及context管理等);
CUDA Runtime API: 对 CUDA Driver API 进行一定封装,简化编程过程,降低开发难度;
CUDA Libraries: 更高层的封装,包含一些成熟的高效函数库。
因此要实现 NVIDIA 容器化,也就是要让应用程序可以在容器内调用 CUDA API 来操作 GPU,一般来讲,就要使容器内应用程序内可调用 CUDA Runtime API 和 CUDA Libraries,容器内可使用 CUDA Driver 相关库。
NVIDIA CONTAINER TOOLKIT 具体结构
一些背景知识
- 什么是运行时?什么是高级运行时(high-level runtime)和低级运行时(low-level runtime):
- docker和containerd的区别和联系:
- 官方参考:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/arch-overview.html
- 什么是OCI?CRI?
组件介绍
在整个container-runtime的组织结构图中,分别对上图进行各个组件的解释:
-
containerd:
-
CRI 插件 是一个中间层,位于 Kubelet 和具体容器运行时之间。插件实现了 CRI 定义的接口(例如 PodSandboxService 和 RuntimeService),并将 Kubelet 发送的请求翻译成对应容器运行时的 API 调用。而containerd是被调用的其中的一种。

-
而docker的如下图所示(其中也包含了containerd):
-
containerd 是一个高级容器运行时(high-level container runtime),它在低级运行时(如 runc)之上构建,提供更丰富的功能和更高层次的抽象。作为高级运行时,containerd 负责容器镜像的传输和管理,以及从镜像运行容器。它通过插件机制实现扩展,包括与 Kubernetes 的 CRI 插件集成、使用 CNI 插件进行网络管理以及使用 CSI 插件进行存储管理。
-
其设计目标是简单、高效,并且与 Kubernetes 深度集成,使其成为 Kubernetes 的首选容器运行时。它提供了核心的容器管理功能,如镜像管理、容器执行和存储管理,并且通过 gRPC API 与外部客户端通信,提供标准化的接口以执行容器操作。
-
containerd 是 Kubernetes 默认的容器运行时。
-
-
runc:
- runc是一个轻量级的、符合 Open Container Initiative (OCI) 规范的低级容器运行时(**low-level container runtime)**工具,它的主要任务是创建和运行容器 。作为一个低级运行时,runc 专注于在 Linux 系统上利用命名空间(namespaces)和控制组(cgroups)等内核特性来提供容器的隔离性。它不涉及镜像管理、网络配置或卷管理等高级功能,这些通常由 Docker、containerd 或 Kubernetes 等更高级的容器管理系统来处理。
- runc 直接与 Linux 内核交互,创建容器所需的隔离环境,并执行指定的容器进程。它不关心镜像的分发和存储,而是假定已经有一个准备好的文件系统(rootfs)和一个配置文件(config.json)来描述容器的运行配置。runc 的设计哲学是保持简单和专注于容器的生命周期管理,如创建、启动、停止和删除容器。
- 在容器技术栈中,runc 作为容器运行的基础,被设计为可以被更高级别的容器管理系统所调用,例如 containerd 或 CRI-O。这些系统在 runc 之上提供了额外的功能,如镜像管理、网络和存储的集成、API 接口等,使得用户可以更方便地使用容器技术。
- runc 作为低级运行时,提供了容器运行所需的核心功能,而高级运行时(比如containerd)则构建在 runc 这样的低级运行时之上,提供更全面和易用的容器管理服务。
-
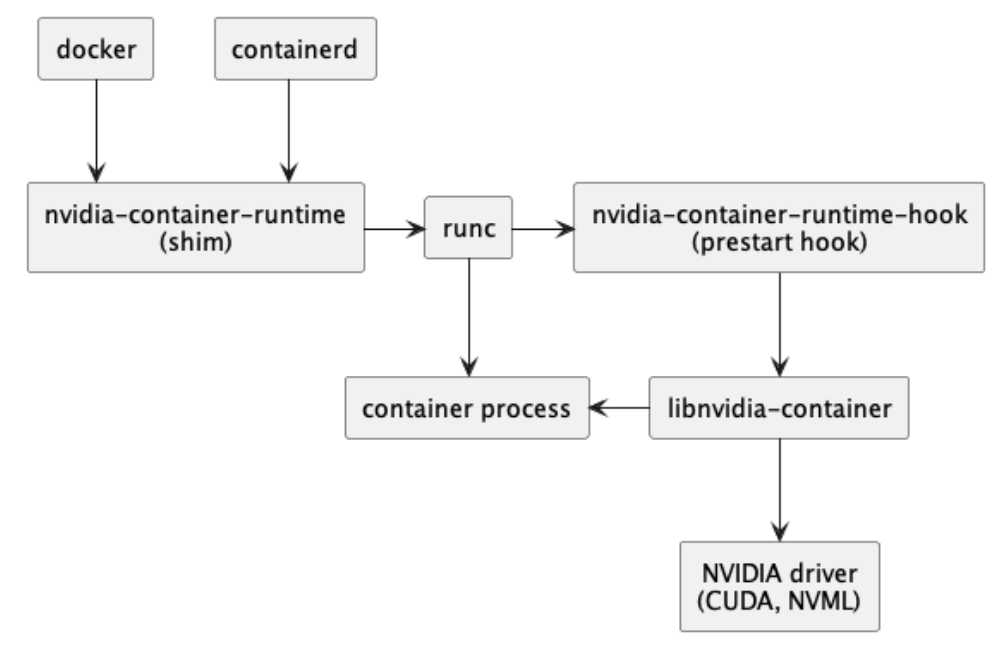
NVIDIA Container Runtime和runc的关系
- NVIDIA Container Runtime 是一个与 Open Containers Initiative (OCI) 规范兼容的 GPU 感知容器运行时,它在 runc 的基础上增加了对 NVIDIA GPU 的支持。runc 本身是一个遵循 OCI 规范的低级容器运行时,专注于创建和运行容器。
- NVIDIA Container Runtime 通过在 runc 的基础上增加一个 prestart hook(称为 nvidia-container-runtime-hook),在容器启动后(Namespace 已创建完成),容器自定义命令(Entrypoint)启动前执行。这个 hook 会检查容器是否需要使用 GPU(通过环境变量 NVIDIA_VISIBLE_DEVICES 判断),如果需要则调用 libnvidia-container 来挂载 GPU 设备和 CUDA 驱动到容器中。如果检测不到需要 GPU 的环境变量,则会执行默认的 runc 运行时逻辑。
- runc 是一个低级容器运行时,主要负责容器的生命周期管理,如创建、启动和停止容器。而 NVIDIA Container Runtime 则是在 runc 的基础上增加了 GPU 支持的能力,使得容器可以访问和利用宿主机上的 NVIDIA GPU 资源。这种设计使得 NVIDIA Container Runtime 可以灵活地支持不同的容器运行时,如 Docker、LXC 和 CRI-O,从而在容器中运行 GPU 加速的应用。
-
nvidia-container-runtime-hook
Nvidia-container-runtime-hook的作用为根据 config 设置 nvidia-container-cli 的参数,并调用 nvidia-container-cli。nvidia-container-cli工具包含于libnvidia-container中,用于自动配置利用NVIDIA硬件的相关容器。该实现依赖于内核原语,其设计与容器运行时无关。nvidia-container-cli 通过向容器暴露设备驱动程序,从而配置容器的 GPU 支持,其将进入指定容器的 namespace 中执行部分操作以确保驱动程序的相关功能在容器里可用,注意,此时假定容器已创建但尚未启动,并且主机文件系统是可访问的(即尚未调用 chroot/pivot_root)。
-
Libnvidia-container:
libnvidia-container用于挂载 GPU Device 和 CUDA Driverlibnvidia-container是 NVIDIA Container Toolkit 的一部分,它提供了一个库和命令行工具来帮助容器发现和使用宿主机上的 NVIDIA GPU 资源。这个库实现了核心的 GPU 发现和挂载逻辑,使得容器可以利用 NVIDIA GPU 进行加速计算。- libnvidia-container 的主要组件包括:
- 库文件 (
libnvidia-container1): 提供核心功能,供其他程序调用。 - 命令行工具 (
nvidia-container-cli): 用于配置 Linux 容器对 GPU 硬件的使用。 - NVIDIA device plugin for Kubernetes 原理分析

容器启动流程(kubelet、containerd、container-runtime、device-plugin、runc)
一些基础背景:
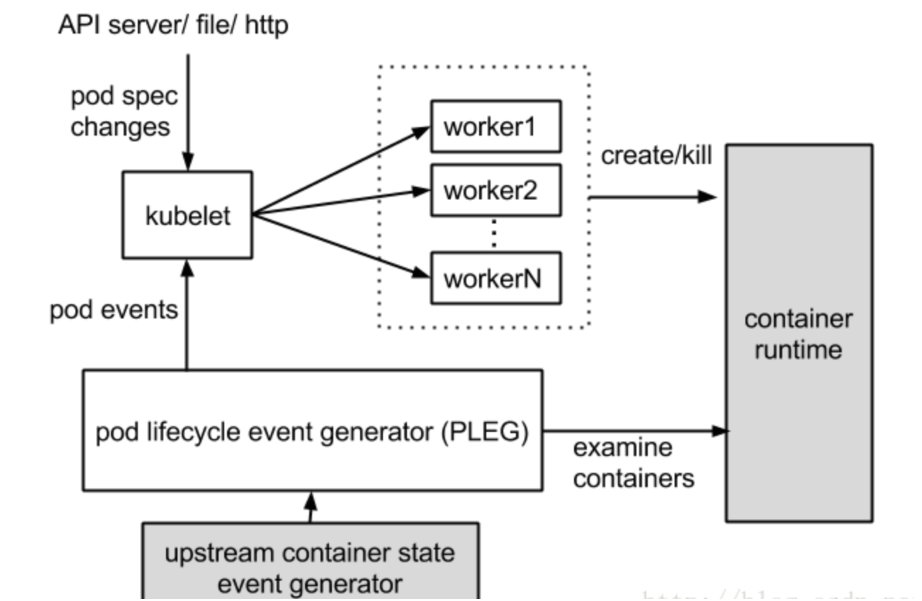
containerd链路:
containerd 作为一个 api 服务,提供了一系列的接口供外部调用,比如创建容器、删除容器、创建镜像、删除镜像等等。使用 docker 和 ctr 等工具,都是通过调用 containerd 的 api 来实现的。

Device plugin & 具体分配example:
NVIDIA device plugin for Kubernetes 原理分析
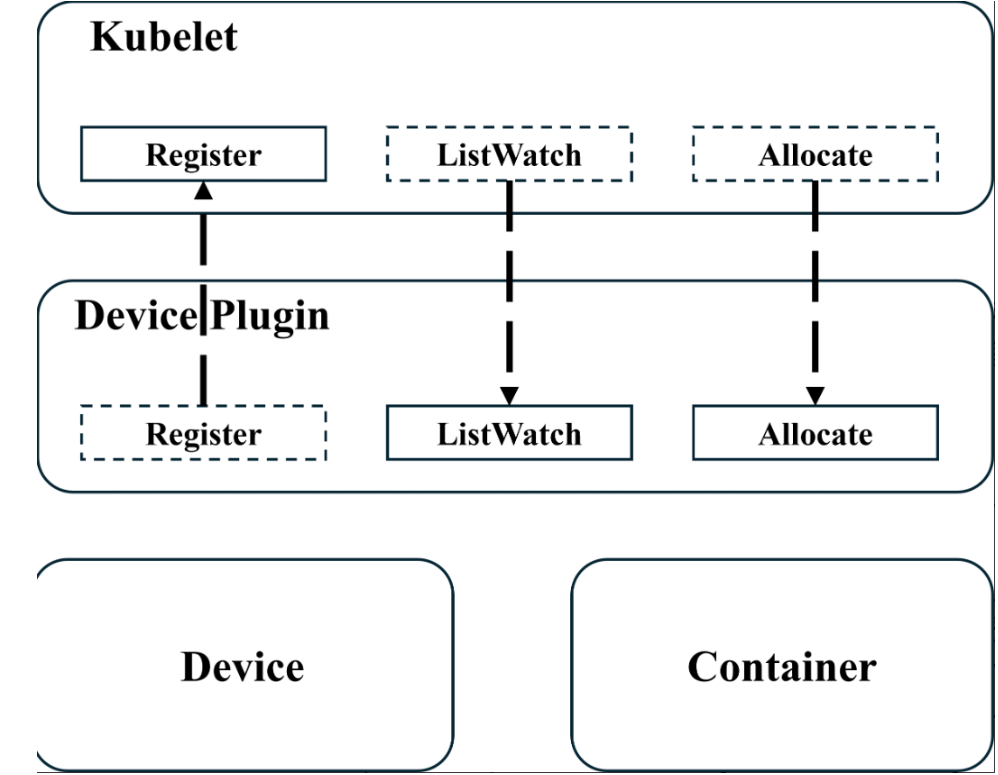
device物理设备要作为资源,通过device plugin的grpc向kubelet注册。在之后的pod/容器的创建便会首先通过kubelet去进行rpc调用listWatch对所拥有的物理设备资源进行查询,并通过allocate进行具体的操作
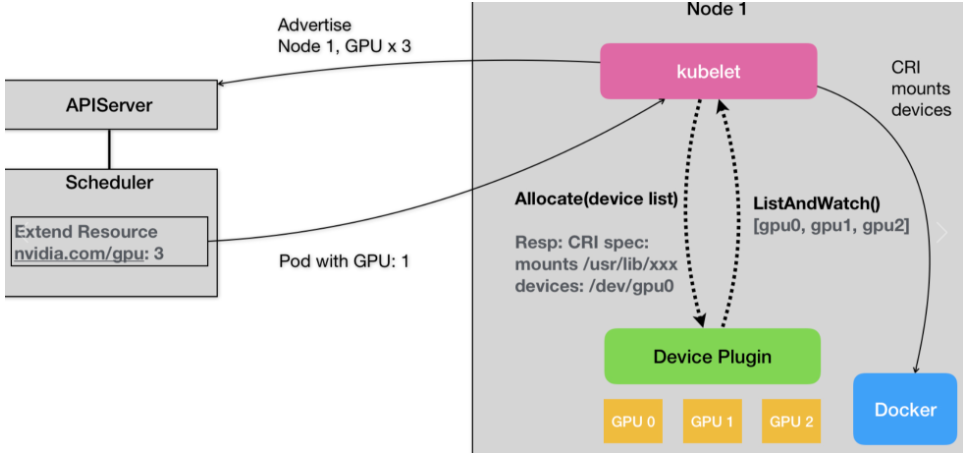
对于上图:
- 首先,对于每一种硬件设备,都需要有它所对应的 Device Plugin 进行管理,这些 Device Plugin,都通过 gRPC 的方式,同 kubelet 连接起来。以 NVIDIA GPU 为例,它对应的插件叫作NVIDIA GPU device plugin。
- 这个 Device Plugin 会通过一个叫作 ListAndWatch 的 API,定期向 kubelet 汇报该 Node 上 GPU 的列表。比如,在我们的例子里,一共有三个 GPU(GPU0、GPU1 和 GPU2)。这样,kubelet 在拿到这个列表之后,就可以直接在它向 APIServer 发送的心跳里,以 Extended Resource 的方式,加上这些 GPU 的数量,比如nvidia.com/gpu=3。所以说,用户在这里是不需要关心 GPU 信息向上的汇报流程的。
- 需要注意的是,ListAndWatch 向上汇报的信息,只有本机上 GPU 的 ID 列表,而不会有任何关于 GPU 设备本身的信息。而且 kubelet 在向 API Server 汇报的时候,只会汇报该 GPU 对应的 Extended Resource 的数量。当然,kubelet 本身,会将这个 GPU 的 ID 列表保存在自己的内存里,并通过 ListAndWatch API 定时更新。
- 而当一个 Pod 想要使用一个 GPU 的时候,它只需要在 Pod 的 limits 字段声明nvidia.com/gpu: 1。那么接下来,Kubernetes 的调度器就会从它的缓存里,寻找 GPU 数量满足条件的 Node,然后将缓存里的 GPU 数量减 1,完成 Pod 与 Node 的绑定。
- 这个调度成功后的 Pod 信息,自然就会被对应的 kubelet 拿来进行容器操作。而当 kubelet 发现这个 Pod 的容器请求一个 GPU 的时候,kubelet 就会从自己持有的 GPU 列表里,为这个容器分配一个 GPU。此时,kubelet 就会向本机的 Device Plugin 发起一个 Allocate() 请求。这个请求携带的参数,正是即将分配给该容器的设备 ID 列表。
- 当 Device Plugin 收到 Allocate 请求之后,它就会根据 kubelet 传递过来的设备 ID,从 Device Plugin 里找到这些设备对应的设备路径和驱动目录。当然,这些信息,正是 Device Plugin 周期性的从本机查询到的。比如,在 NVIDIA Device Plugin 的实现里,它会定期访问 nvidia-docker 插件,从而获取到本机的 GPU 信息。
- 而被分配 GPU 对应的设备路径和驱动目录信息被返回给 kubelet 之后,kubelet 就完成了为一个容器分配 GPU 的操作。接下来,kubelet 会把这些信息追加在创建该容器所对应的 CRI 请求当中。这样,当这个 CRI 请求发给 Docker 之后,Docker 为你创建出来的容器里,就会出现这个 GPU 设备,并把它所需要的驱动目录挂载进去。
至此,Kubernetes 为一个 Pod 分配一个 GPU 的流程就完成了。
参考原文链接:https://blog.csdn.net/qq_37756660/article/details/134523326
containerd 创建容器流程:
- 接收到 api 请求,通过调用 containerd-shim-runc-v2 调用 runc 创建容器,主要是做解压文件和准备环境的工作。
- 接收到 api 请求,创建一个 task,task 是一个容器的抽象,包含了容器的所有信息,比如容器的 id、容器的状态、容器的配置等等。
- containerd 启动一个 containerd-shim-runc-v2 进程。
- containerd-shim-runc-v2 进程再启动一个 containerd-shim-runc-v2 进程(相当于这里已经有两个),然后第一个 containerd-shim-runc-v2 进程退出。
- containerd 通过 IPC 通信,让第二个 containerd-shim-runc-v2 启动容器。
- containerd-shim-runc-v2 进程通过调用 runc start 启动容器。
- runc 会调用 runc init 启动容器的 init 进程。
- runc init 进程会调用 unix.Exec 的方式,替换自己的进程,启动容器的第一个进程。这个进程既是容器的启动命令,也是容器的 pid 1 进程。完成之后,runc create 进程退出。
这样 containerd-shim-runc-v2 的父进程就是 init 进程(1),而 容器的init 进程(用户进程)的父进程是 containerd-shim-runc-v2 进程,这样就形成了一个进程树。
一些问题🙋
- 为什么要创建两个 containerd-shim 不嫌麻烦吗?
- 因为第一个 containerd-shim 会在创建完第二个 containerd-shim 后退出,而作为第一个进程子进程的第二个 containerd-shim 会成为孤儿进程,这样就会被 init 进程接管,而和 containerd 本身脱离了关系。
- 为什么要想方设法把 containerd-shim 挂在 init 进程下面,而不是 containerd?
- 为了保证稳定性和独立性。这样做可以确保即使 containerd 崩溃或重启,由 containerd-shim 管理的容器进程仍然可以继续运行,不受影响。此外,这种设计还有助于更好地管理资源和防止资源泄露。
- 为什么 runc start 进程退出了 runc init 进程(用户进程)没有变成 系统init 的子进程 而是containerd-shim的子进程?
- 因为 containerd-shim 做了 unix 的 PR_SET_CHILD_SUBREAPER 调用, 这个系统调用大概作用为当这个进程的子子孙孙进程变成孤儿进程的时候,这个进程会接管这个孤儿进程,而不是 init 进程接管。
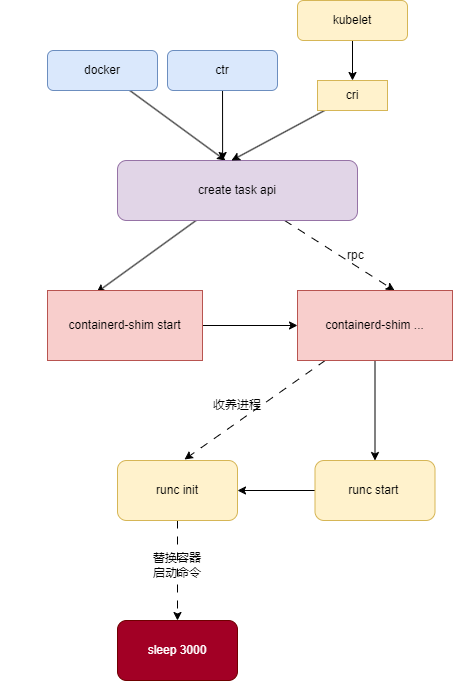
完整链路流程:
下面是一个详细的示意图,展示了包含 GPU 需求的 Pod 在 Kubernetes 集群上的生命周期,包括 Kubelet、containerd、容器运行时(如 runc)、设备插件(如 NVIDIA Device Plugin)之间的交互:
- 设备注册与资源信息同步:
- 每个节点上的 Kubelet 与设备插件(如 NVIDIA GPU Device Plugin)交互,完成设备的注册。
- 设备插件通过 ListAndWatch 方法定期向 Kubelet 汇报节点上可用的 GPU 设备列表。
- Kubelet 将这些设备资源信息同步至 Kubernetes 集群的 API Server。
- Pod 调度:
- 包含 GPU 需求的 Pod 被创建后,Kubernetes 调度器根据 API Server 中的节点资源信息选择合适的节点进行调度。
- 设备分配:
- 节点上的 Kubelet 获取到 Pod 信息后,根据 Pod 的资源需求从本地缓存中选择合适的设备。
- Kubelet 向设备插件发送 Allocate 调用,请求分配 GPU 设备。
- 设备插件根据请求的设备 ID,返回设备路径和驱动目录等信息给 Kubelet。
- Kubelet 存储设备分配信息:
- Kubelet 将设备分配信息存储在一个名为 podDevices 的映射(map)中,这个映射位于 ManagerImpl 中。
- 容器创建:
- Kubelet 在创建 Pod 的容器时,会根据 podDevices 映射中的信息,通过 CRI (Container Runtime Interface) 请求 containerd 创建容器。
- Kubelet 会将 GPU 设备路径和驱动目录作为挂载卷和环境变量传递给容器运行时。
- 容器运行时与设备插件交互:
- containerd 接收到 Kubelet 的请求后,创建一个 task,并启动 containerd-shim 进程来管理容器的生命周期。
- containerd-shim 调用 NVIDIA Container Runtime,它负责在容器内设置 GPU 环境。
- 容器启动:
- NVIDIA Container Runtime 调用 runc 来实际创建容器,进行解压镜像和准备环境的工作。
- runc 启动容器的 init 进程(PID 1),容器启动并运行。
- 容器启动完成:
- 容器启动并运行,Kubelet 将容器状态更新到 Kubernetes 集群。
以下是这个过程的示意图:
1 | Kubernetes Cluster |
在这个过程中,Kubelet 作为 Kubernetes 与容器运行时之间的桥梁,负责协调容器的生命周期管理。containerd 作为容器运行时的守护进程,处理容器的创建、启动和监控。设备插件为容器提供必要的硬件资源,如 GPU。这些组件之间的交互确保了 Pod 能够在节点上顺利创建和运行。