GPU容器相关概念
GPU容器相关概念
CUDA API 体系:
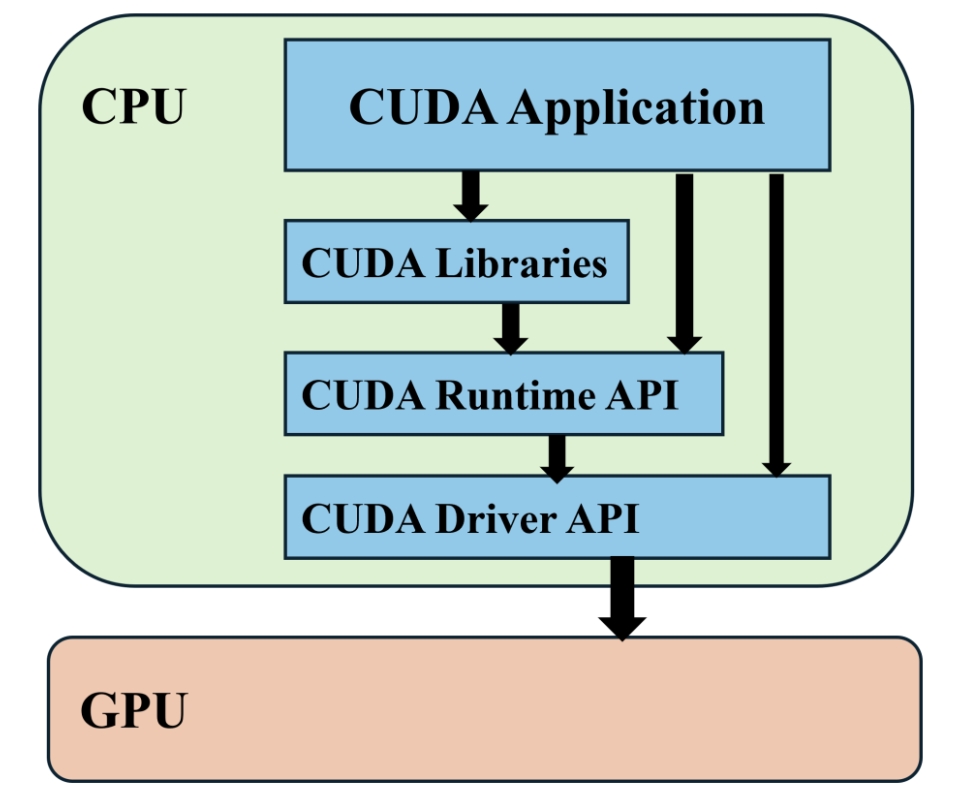
要使编写的 GPU 程序能够正常运行,需要借助 CUDA 直接使用 NVIDIA 的 GPU 来执行通用计算任务,从而使 GPU 能够从图形渲染设备转变为一个通用并行处理器,CUDA API 体系结构图如下:

- **CUDA Driver API:**GPU 设备的抽象层,通过一系列 API 直接操作 GPU 设备,性能好,但编程难度高(需要显式进行device初始化以及context管理等)。
- CUDA Runtime API: 对 CUDA Driver API 进行一定封装,简化编程过程,降低开发难度。
- CUDA Libraries: 更高层的封装,包含一些成熟的高效函数库。
因此要实现 CUDA 容器化,就要让应用程序可以在容器内调用 CUDA API 来操作 GPU,一般来讲,就要使容器内程序可调用 CUDA Runtime API 和 CUDA Libraries,容器内可使用 CUDA Driver 相关库。
CUDA 容器化基本思路
要将 GPU 设备挂载到容器中,NVIDIA Docker 是通过注入一个 prestart 的 hook 到容器中,在容器自定义命令启动前将 GPU 挂载好。设备挂载好后,也需要使用类似 hook 的方式将宿主机中的 CUDA Driver API 挂载到容器里,需要将 CUDA Runtime API 和 CUDA Libraries 与应用程序一起打包到镜像中。
具体实现为将 Docker daemon 的启动参数中默认的 Runtime 改为 nvidia-container-runtime 后,nvidia-container-runtime 在 runc 基础上多实现了 nvidia-container-runtime-hook:
- 该 hook 会在容器启动后(Namespace 已创建完成),在容器自定义命令启动前执行。当检测到
NVIDIA_VISIBLE_DEVICES环境变量时,会调用libnvidia-container挂载 GPU Device 和 CUDA Driver。如果没有检测到NVIDIA_VISIBLE_DEVICES就会执行默认的 runc。
CUDA 三层API中,CUDA Libraries和CUDA Runtime API是和应用程序一起打包到镜像中的,所以在应用程序和CUDA Libraries以及CUDA Runtime间通常不会有什么问题。主要问题是在CUDA Runtime和CUDA Driver之间。CUDA Driver库是在创建容器时从宿主机挂载到容器中的,很容易出现版本问题,需要保证CUDA Driver的版本不低于CUDA Runtime版本。
Nvidia Docker 介绍
原本的 nvidia-docker 与 docker 运行时高度耦合,缺乏灵活性,因此设计了新的容器运行时设计:nvidia-docker2.0。

nvidia-docker2.0 通过修改 docker 的配置文件/etc/docker/daemon.json 来让 docker 使用 NVIDIA Container runtime。
- nvidia-container-runtime 在原有的 docker 容器运行时 runc 的基础上增加一个 prestart hook 用于调用 libnvidia-container 库。
- libnvidia-container 提供一个库和一个简单的 CLI 程序,使用这个库可以使 NVIDIA GPU 适用 Linux 容器。
其之间的关系可参考下图
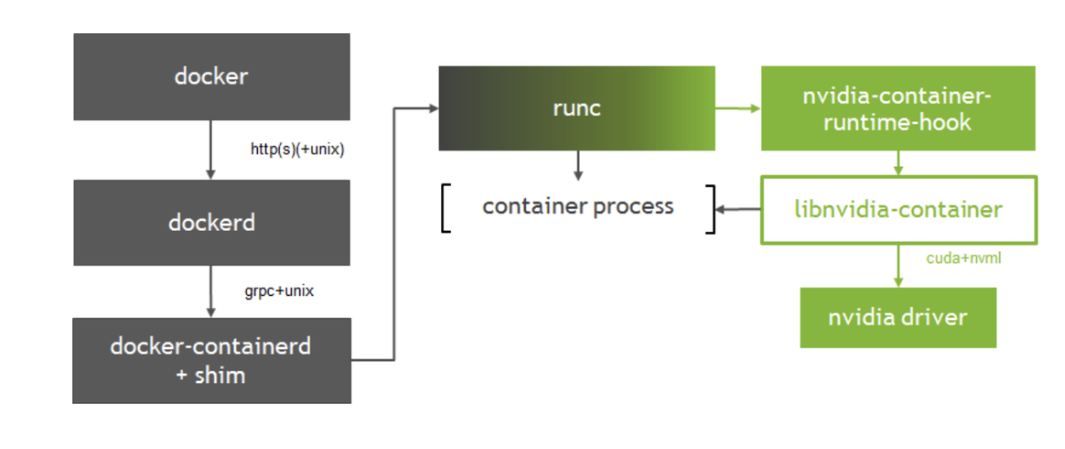
正常启动一个容器会通过 containerd 去调用 runc,而 GPU 容器会将 runc 换为 nvidia-container-runtime,如果需要使用 GPU 则调用 libnvidia-container,否则走默认的runc。
目前 nvidia docker2 已经被 nvidia container toolkits 取代。
Nvidia Container Toolkit
NVIDIA Container Toolkit 在实际场景中的位置如下图所示
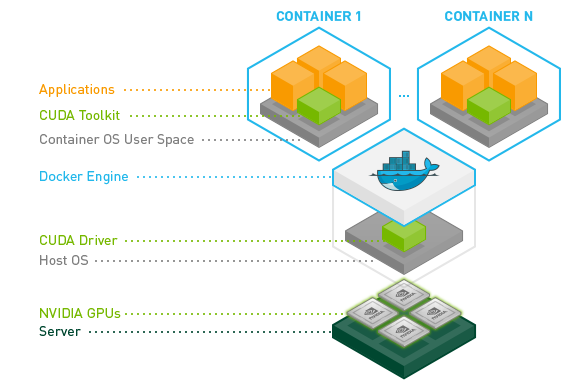
NVIDIA Container 的组件包括了:
- NVIDIA Container Runtime(nvidia-container-runtime)
- NVIDIA Container Runtime Hook(nvidia-container-toolkit/nvidia-container-runtime-hook)
- NVIDIA Container Library and CLI(libnvidia-container1, nvidia-container-cli)
这些组件被打包为了 NVIDIA Container Toolkit,对于 Docker 或者 Containerd,NVIDIA Container Runtime(nvidia-container-runtime)被配置为一个符合 OCI 标准的运行时,其结构如下图所示(具体流程就是 prestart-hook 设置好参数,从而调用 nvidia-cli 执行相关挂载):

- NVIDIA Container Library and CLI
这些组件被打包为了 libnvidia-container-tools 和 libnvidia-container软件包,其能够自动配置能够利用 GPU 的 Linux 容器,实现只依赖于内核原语,与容器运行时无关。
- NVIDIA Container Runtime Hook
该组件被包含于 nvidia-container-toolkit,其包含一个可执行文件,实现了runc prestart hook 所需的接口。脚本在容器创建后、启动前由runc调用并获得与容器关联的config.json的访问权限,然后获取其中的信息并结合一些 flags (如选择哪些 GPU)调用 nvidia-container-cli,其关键部分如下:
1 | if len(nvidia.Devices) > 0 { |
- NVIDIA Container Runtime
该组件被包含于 nvidia-container-toolkit-base 中,曾经其就只是一个 runC 的复制体,但是现在其变成了一个安装在主机上的对 runC 的封装,其会将 prestart hook 注入 runC 的 spec 中,再用这个新的 spec 作为参数去调用本地的 runC
- NVIDIA Container Toolkit CLI
该组件被包含于 nvidia-container-toolkit-base 中,其包含大量用于与 NVIDIA Container Toolkit 交互的实用程序。
- Libnvidia-container
libnvidia-container 用于挂载 GPU Device 和 CUDA Driver,其关键概念如下:
1 | /* Query the driver and device information. */ |
nvc_driver_info_new() 和 nvc_device_info_new() 方法分别获取了 CUDA Driver 和 GPU Device 相关信息,如 driver libraries,driver binaries 路径,cuda version 等。再通过 select_devices() 方法选出容器可用的GPU Device。
获取到 CUDA Driver Libraries/Binaries 路径,以及可用的 GPU 后,将其挂载到容器中。实现如下:
1 | /* Mount the driver and visible devices. */ |
其是采用 mount --bind 将 CUDA Driver Libraries/Binaries 一个个挂载到容器里,而不是将整个目录挂载到容器中。可通过 NVIDIA_DRIVER_CAPABILITIES 环境变量指定要挂载的driver libraries/binaries,可通过NVIDIA_DRIVER_CAPABILITIES 环境变量指定要挂载的driver libraries/binaries。
总而言之,NVIDIA Container Toolkit 是一系列软件包的集合,这些软件包将容器运行时(如 Docker)与主机上的英伟达驱动程序接口相连。libnvidia-container库负责提供 API 和 CLI,通过运行时包装器自动向容器提供系统的 GPU,其内部结构如下:
nvidia-container-toolkit组件实现了一个容器运行钩子。这意味着当一个新容器即将启动时,它会收到通知。它会查看要附加的 GPU,并调用libnvidia-container来处理容器创建。
该挂钩由nvidia-container-runtime 启用。它封装了 "真正的 "容器运行时,如 containerd 或 runc,以确保运行prestart钩子。钩子执行后,现有运行时将继续执行容器启动过程。容器工具包安装完成后,会看到 Docker 守护进程配置文件中选择了nvidia-container-runtime。