GPU 容器底层实现
容器使⽤ GPU – 问题提出
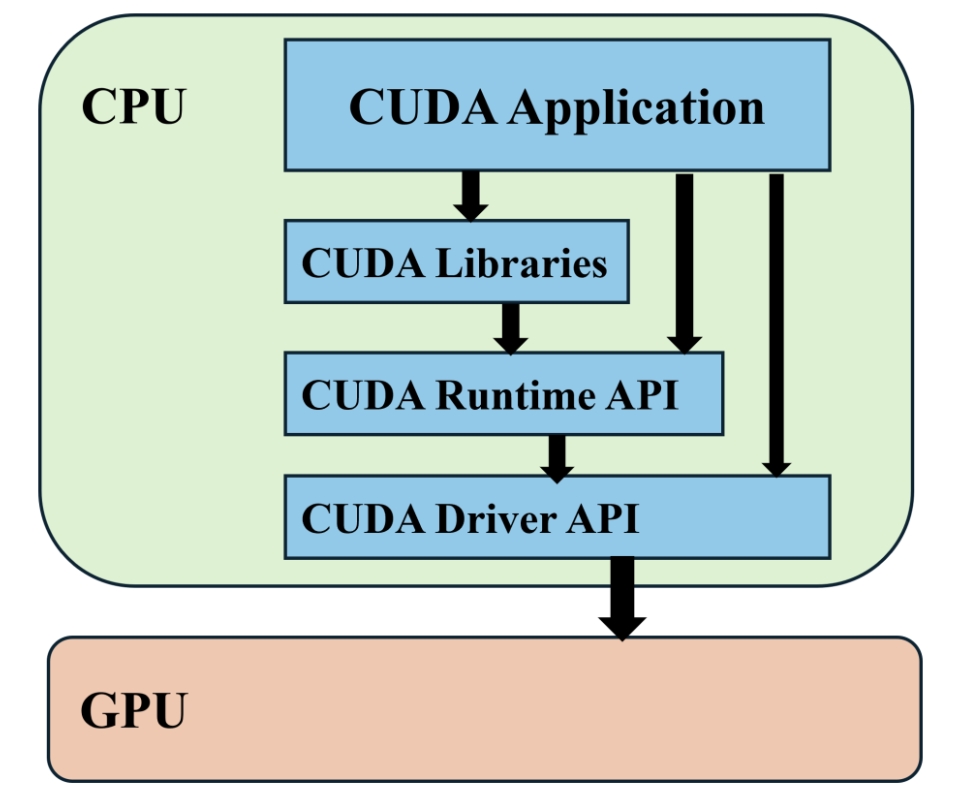
在容器环境中使⽤ GPU 是⼀件有趣的事情,以 NVIDIA GPU 为例,常⻅的⼀个使⽤ CUDA 的应⽤程序,其结构图如下:
**CUDA Driver API:**GPU 设备的抽象层,通过⼀系列 API 直接操作 GPU 设备,性能好,但编程难度⾼ (需要显式进⾏device初始化以及context管理等)
CUDA Runtime API: 对 CUDA Driver API 进⾏⼀定封装,简化编程过程,降低开发难度;
CUDA Libraries: 更⾼层的封装,包含⼀些成熟的⾼效函数库。
因此要实现 NVIDIA 容器化,也就是要让应⽤程序可以在容器内调⽤ CUDA API 来操作 GPU,⼀般来讲,就要使容器内应⽤程序内可调⽤ CUDA Runtime API 和 CUDA Libraries,容器内可使⽤ CUDA Driver 相关库。
曾经 NVIDIA Docker 通过 docker 的 volume ⽅法将 CUDA Driver 挂载到容器⾥,应⽤程序需要在 LD_LIBRARY_PATH 环境变量中配置 CUDA Driver 库所在位置。
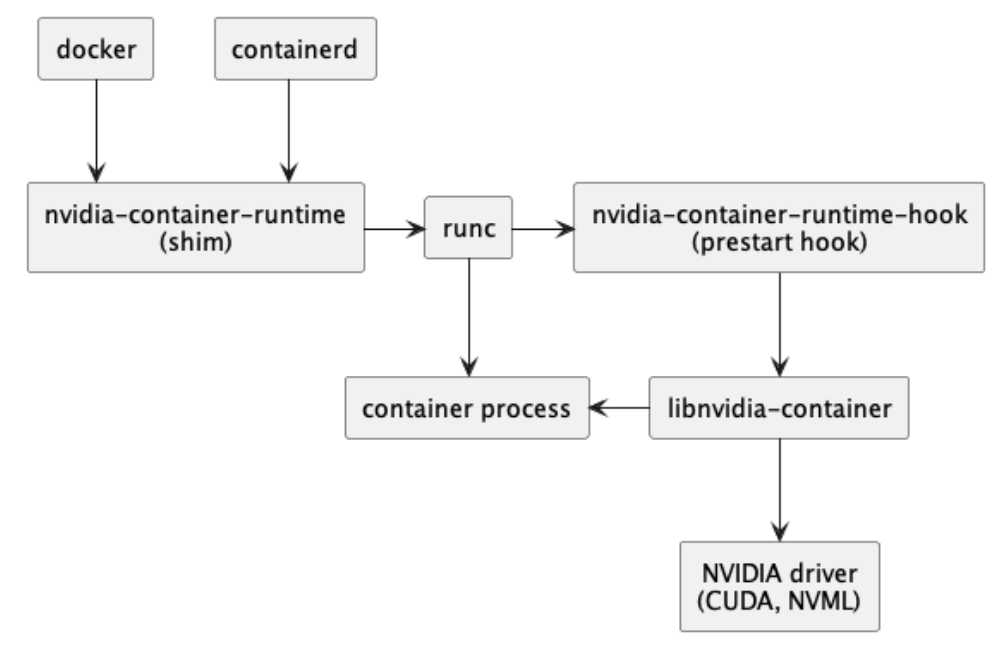
⽽到了 NVIDIA Docker2.0,默认 的 Runtime 被修改为了 nvidia-container-runtime,nvidia-container-runtime 会向传⼊的 OCI 规范,添加⼀个 prestart hook,该挂钩为容器调⽤ NVIDIA 容器运⾏时挂钩,从⽽配置 GPU 访问。 NVIDIA 将所有的这些组件打包成了 nvidia container toolkit,其内部组织结构如下:
简单来说,NVIDIA Container Toolkit 是⼀系列软件包的集合,这些软件包将容器运⾏时(如 Docker)与主机上的英伟达驱动程序接⼝相连。
libnvidia-container 库负责提供 API 和 CLI, 通过运⾏时包装器⾃动向容器提供系统的 GPU,其内部结构如下:
nvidia-container-toolkit 组件实现了⼀个容器运⾏ hook。这意味着当⼀个新容器即将启动时,它会收到通知。它会查看要附加的 GPU,并调⽤ libnvidia-container 来处理容器创建。 该 hook 由 nvidia-container-runtime 启⽤。它封装了 "真正的 "容器运⾏时,如 containerd 或 runc,以确保运⾏ prestart hook 。hook 执⾏后,现有运⾏时将继续执⾏容器启动过程。容器⼯具包安装完成后,会看到 Docker 守护进程配置⽂件中选择了 nvidia-container-runtime 。
补充:[docker基础知识_–runtime=runc-CSDN博客](https://blog.csdn.net/o0xgw0o/article/details/124498742?ops_request_misc={"request_id"%3A"43690CB2-A222-4FE8-8DAE-E2A586C5B244"%2C"scm"%3A"20140713.130102334.."}&request_id=43690CB2-A222-4FE8-8DAE-E2A586C5B244&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-124498742-null-null.142^v100^pc_search_result_base8&utm_term=low-level runtime&spm=1018.2226.3001.4187)
挂载流程具体细节
NVIDIA Container Runtime
nvidia-container-runtime 是⼀个对low-level runtime (底层运⾏时,如 runc)的 shim,其传统模式就是修改 OCI specification 。注意:这⾥它与 docker 中的 --gpus ⼲了同样的事情(所以如果是其他模式,就会报错,此时加 --runtime=nvidia 即可)。
nvidia-container-runtime 其实就是在 runc 基础上多实现了对 nvidia-container-runime-hook 的调⽤。当检测到包含有 create 命令和 NVIDIA_VISIBLE_DEVICES 环境变 量时,就会执⾏默认的 runc 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 func newNVIDIAContainerRuntime (logger logger.Interface, cfg *config.Config, argv []string , driver *root.Driver) error ) { lowLevelRuntime, err := oci.NewLowLevelRuntime(logger, cfg.NVIDIAContainerRuntimeConfig.Runtimes) if err != nil { return nil , fmt.Errorf("error constructing low-level runtime: %v" , err) } if !oci.HasCreateSubcommand(argv) { logger.Debugf("Skipping modifier for non-create subcommand" ) return lowLevelRuntime, nil } ociSpec, err := oci.NewSpec(logger, argv) if err != nil { return nil , fmt.Errorf("error constructing OCI specification: %v" , err) } specModifier, err := newSpecModifier(logger, cfg, ociSpec, driver) if err != nil { return nil , fmt.Errorf("failed to construct OCI spec modifier: %v" , err) } r := oci.NewModifyingRuntimeWrapper( logger, lowLevelRuntime, ociSpec, specModifier, ) return r, nil }
其中需要注意的是,如果命令中不包含 create,也就是说不创建新的 container 时,会直接返回low-level runtime。
其中 modify 部分就是将输入的 OCI spec 进行修改,添加上 Hook,不同 modify 的功能主要功能如下:
ModeModifier: 添加 Hook
GraphicsModifier: 负责修改 NVIDIA_DRIVER_CAPABILITIES 相关指标
FeatureModifier: 包括一些可选功能(如 NVSWITCH 等)的修改
Modify 的关键代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func (m stableRuntimeModifier) error { if spec.Hooks != nil { for _, hook := range spec.Hooks.Prestart { hook := hook if isNVIDIAContainerRuntimeHook(&hook) { m.logger.Infof("Existing nvidia prestart hook (%v) found in OCI spec" , hook.Path) return nil } } } path := m.nvidiaContainerRuntimeHookPath m.logger.Infof("Using prestart hook path: %v" , path) args := []string {filepath.Base(path)} if spec.Hooks == nil { spec.Hooks = &specs.Hooks{} } spec.Hooks.Prestart = append (spec.Hooks.Prestart, specs.Hook{ Path: path, Args: append (args, "prestart" ), }) return nil }
其在最后向 spec 中写入了一个 prestart,从而启动 nvidia-container-runtime-hook组件进行对 prestart 的具体修改。
Docker GPU
在 Docker 中,也可以通过指定 --gpus 的方式有和 NVIDIA Container Runtime 类似的效果,相关代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 const nvidiaHook = "nvidia-container-runtime-hook" func setNvidiaGPUs (s *specs.Spec, dev *deviceInstance) error { req := dev.req if req.Count != 0 && len (req.DeviceIDs) > 0 { return errConflictCountDeviceIDs } if len (req.DeviceIDs) > 0 { s.Process.Env = append (s.Process.Env, "NVIDIA_VISIBLE_DEVICES=" +strings.Join(req.DeviceIDs, "," )) } else if req.Count > 0 { s.Process.Env = append (s.Process.Env, "NVIDIA_VISIBLE_DEVICES=" +countToDevices(req.Count)) } else if req.Count < 0 { s.Process.Env = append (s.Process.Env, "NVIDIA_VISIBLE_DEVICES=all" ) } var nvidiaCaps []string for _, c := range dev.selectedCaps { nvcap := nvidia.Capability(c) if _, isNvidiaCap := allNvidiaCaps[nvcap]; isNvidiaCap { nvidiaCaps = append (nvidiaCaps, c) continue } } if nvidiaCaps != nil { s.Process.Env = append (s.Process.Env, "NVIDIA_DRIVER_CAPABILITIES=" +strings.Join(nvidiaCaps, "," )) } path, err := exec.LookPath(nvidiaHook) if err != nil { return err } if s.Hooks == nil { s.Hooks = &specs.Hooks{} } s.Hooks.Prestart = append (s.Hooks.Prestart, specs.Hook{ Path: path, Args: []string { nvidiaHook, "prestart" , }, Env: os.Environ(), }) return nil }
这也就印证了之前所说的非传统模式的 nvidia-container-runtime 会和 Docker 产生的冲突
NVIDIA Container Runtime Hook
Nvidia-container-runtime-hook的作用为根据 config 设置 nvidia-container-cli 的参数,并调用 nvidia-container-cli
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 rootfs := getRootfsPath(container) args := []string {getCLIPath(cli)} if cli.Root != "" { args = append (args, fmt.Sprintf("--root=%s" , cli.Root)) } if cli.LoadKmods { args = append (args, "--load-kmods" ) } if cli.NoPivot { args = append (args, "--no-pivot" ) } if *debugflag { args = append (args, "--debug=/dev/stderr" ) } else if cli.Debug != "" { args = append (args, fmt.Sprintf("--debug=%s" , cli.Debug)) } if cli.Ldcache != "" { args = append (args, fmt.Sprintf("--ldcache=%s" , cli.Ldcache)) } if cli.User != "" { args = append (args, fmt.Sprintf("--user=%s" , cli.User)) } args = append (args, "configure" ) if ldconfigPath := cli.NormalizeLDConfigPath(); ldconfigPath != "" { args = append (args, fmt.Sprintf("--ldconfig=%s" , ldconfigPath)) } if cli.NoCgroups { args = append (args, "--no-cgroups" ) } if len (nvidia.Devices) > 0 { args = append (args, fmt.Sprintf("--device=%s" , nvidia.Devices)) } if len (nvidia.MigConfigDevices) > 0 { args = append (args, fmt.Sprintf("--mig-config=%s" , nvidia.MigConfigDevices)) } if len (nvidia.MigMonitorDevices) > 0 { args = append (args, fmt.Sprintf("--mig-monitor=%s" , nvidia.MigMonitorDevices)) } if len (nvidia.ImexChannels) > 0 { args = append (args, fmt.Sprintf("--imex-channel=%s" , nvidia.ImexChannels)) } for _, cap := range strings.Split(nvidia.DriverCapabilities, "," ) { if len (cap ) == 0 { break } args = append (args, capabilityToCLI(cap )) } for _, req := range nvidia.Requirements { args = append (args, fmt.Sprintf("--require=%s" , req)) } args = append (args, fmt.Sprintf("--pid=%s" , strconv.FormatUint(uint64 (container.Pid), 10 ))) args = append (args, rootfs) env := append (os.Environ(), cli.Environment...) err = syscall.Exec(args[0 ], args, env)
代码中与 GPU 有关的部分已经加粗标出,其中全部信息都来自由如下代码生成的 image.CUDA(WithDisableRequire 主要用于忽略 startup 时的 CUDA 类型检查,暂时可不用管)
1 2 3 4 5 6 s := loadSpec(path.Join(b, "config.json" )) image, err := image.New( image.WithEnv(s.Process.Env), image.WithDisableRequire(hook.DisableRequire), )
上面提到的各种参数(device、mig-config等)均来自 image 中最终所获得的环境变量,直接查询即可获得,image.CUDA 的数据结构如下:
1 2 3 4 type CUDA struct { env map [string ]string mounts []specs.Mount }
至此,可以调用 nvidia-container-cli 进行后续操作了
NVIDIA Container CLI
nvidia-container-cli 工具包含于 libnvidia-container 中,用于自动配置利用NVIDIA硬件的相关容器。
该实现依赖于内核原语,其设计与容器运行时无关。
nvidia-container-cli 通过向容器暴露设备驱动程序,从而配置容器的 GPU 支持,其将进入指定容器的 namespace 中执行部分操作以确保驱动程序的相关功能在容器里可用,注意,此时假定容器已创建但尚未启动,并且主机文件系统是可访问的(即尚未调用 chroot/pivot_root)。
分别支持 configure、info、list 三个功能,在此只分析 configure 功能,也就是让容器能够获取到 GPU Driver 和 Device 信息,从而能够使用 GPU。
在 configure 功能中,会分别获取 Driver 和 Device 的相关信息并筛选出合适的 GPU 设备,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 if ((drv = libnvc.driver_info_new(nvc, NULL )) == NULL || (dev = libnvc.device_info_new(nvc, NULL )) == NULL ) { warnx("detection error: %s" , libnvc.error(nvc)); goto fail; } if (dev->ngpus > 0 ) { if (select_devices(&err, ctx->devices, dev, &devices) < 0 ) { warnx("device error: %s" , err.msg); goto fail; } }
之后就可以将其 mount 到容器中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if (perm_set_capabilities(&err, CAP_EFFECTIVE, ecaps[NVC_MOUNT], ecaps_size(NVC_MOUNT)) < 0 ) { warnx("permission error: %s" , err.msg); goto fail; } if (libnvc.driver_mount(nvc, cnt, drv) < 0 ) { warnx("mount error: %s" , libnvc.error(nvc)); goto fail; } for (size_t i = 0 ; i < devices.ngpus; ++i) { if (libnvc.device_mount(nvc, cnt, devices.gpus[i]) < 0 ) { warnx("mount error: %s" , libnvc.error(nvc)); goto fail; } }
其中 driver 的 mount 会根据需要选择宿主机上相关的 binary 和 library,可用 nvidia-container-cli list 查看。
至此就完成了 GPU 在容器中的使用,可以发现一般情况下,CUDA Libraries 和 CUDA Runtime API 是和应用程序一起打包到镜像中的,而 CUDA Driver 库是在创建容器时从宿主机挂载到容器中的,因此存在版本风险,所以需要保证 CUDA Driver 的版本不低于 CUDA Runtime 版本。