一种基于经验的动态资源调度:StraightLine:An End-to-End Resource-Aware Scheduler for Machine Learning Application Requests
StraightLine: An End-to-End Resource-Aware Scheduler for Machine Learning Application Requests

摘要:
提出了一个端到端的资源感知调度器,用于在混合基础设施中调度机器学习应用请求的最优资源。
关键词:
机器学习部署、异构资源、资源放置、容器化、无服务器计算。
主要内容:
- ML应用的生命周期包括模型开发和模型部署两个阶段。
- 传统ML系统通常只关注生命周期中的一个特定阶段或阶段。
- StraightLine通过一个基于经验的动态放置算法,根据请求的独特特征(如请求频率、输入数据大小和数据分布)智能地放置请求。
- 包括三个层次:模型开发抽象、多种实现部署、实时资源调度。
模型容器化:
-
使用NVIDIA-Docker实现模型开发的容器化。
-
为模型训练构建了强大的NVIDIA-Docker,为模型验证构建了轻量级的NVIDIA-Docker。
容器定制:
- 根据不同的压缩ML模型,构建相应的RESTful API、无服务器应用程序和Docker容器。
- 使用Docker容器适应不同的计算环境。
实时资源感知调度:
- 设计了一个基于经验的动态放置算法,以在混合基础设施中智能地放置不同的ML应用请求。
评估:
- 在一个混合测试平台(RESTful API、无服务器进程、Docker容器和虚拟机)上进行了实验。
- 实验结果表明,StraightLine在适应异构资源方面有效。
具体的算法:
在论文 “StraightLine: An End-to-End Resource-Aware Scheduler for Machine Learning Application Requests” 中,提出了一个名为 Empirical Dynamic Placing Algorithm 的算法,用于智能地放置机器学习(ML)应用请求到最优资源上。这个算法是 StraightLine 调度器的关键创新之一。
Empirical Dynamic Placing Algorithm 的核心特点:
-
基于经验:算法依赖于对过往请求和资源使用情况的经验数据来做出决策。
-
动态放置:算法实时分析请求的特征,并动态地决定将请求分配到哪种资源(如容器、虚拟机或无服务器进程)。
-
考虑请求特征:算法考虑了请求的独特特征,例如请求频率、输入数据大小和数据分布。
算法的逻辑流程:
-
输入:算法接收一组请求 R,每个请求 r 包含请求 ID(rid)、在时间 t 的请求频率(ft)、请求数据大小(rd)。
-
初始化:定义请求频率阈值(F)和数据大小阈值(D),以及可用资源(Flask SF 和 Docker SD)。
-
请求分析:
- 如果请求频率 ft 大于阈值 F 且数据大小 rd 小于阈值 D,则将请求 r 部署到无服务器平台上。
- 如果数据大小 rd 大于阈值 D,则将请求 r 部署到 Docker 平台上。
- 如果 Flask SF 资源可用且请求频率 ft 适中,则将请求 r 部署到 Flask(本地 web 服务器)上。
-
资源分配:
- 如果 Flask SF 资源不可用,但 Docker SD 资源可用,则将请求分配到 Docker 平台。
- 如果 Flask SF 和 Docker SD 资源都不可用作进一步请求,则将请求分配到无服务器平台上。
-
输出:算法输出请求 R 的放置 K,即每个请求分配到的具体资源。
算法的目的:
- 最小化延迟:通过智能放置请求,减少 ML 应用部署的响应时间和失败率。
- 适应混合基础设施:算法能够适应包含云计算数据中心、本地服务器、容器和无服务器平台的混合基础设施。
算法的效果:
- 减少响应时间:通过将请求分配到最适合的资源,算法减少了处理请求所需的时间。
- 降低失败率:通过考虑请求的特征和资源的可用性,算法减少了请求处理失败的可能性。
Empirical Dynamic Placing Algorithm 是 StraightLine 调度器中用于优化 ML 应用请求处理的核心组件,它通过实时分析和智能决策来提高资源利用率和系统性能。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Roger-Lv's space!
相关推荐
2024-09-20
AI资源调度
AI资源调度 100道k8s面试题:https://zhuanlan.zhihu.com/p/721588398 [云原生 AI 的资源调度和 AI 工作流引擎设计分享_paddleflow-CSDN博客](https://blog.csdn.net/lihui49/article/details/129260286?ops_request_misc={"request_id"%3A"81C8FAB8-41BA-4FDC-A5E5-B7EF5F69A9D0"%2C"scm"%3A"20140713.130102334.."}&request_id=81C8FAB8-41BA-4FDC-A5E5-B7EF5F69A9D0&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-3-129260286-null-null.142^v100^pc_search_re...
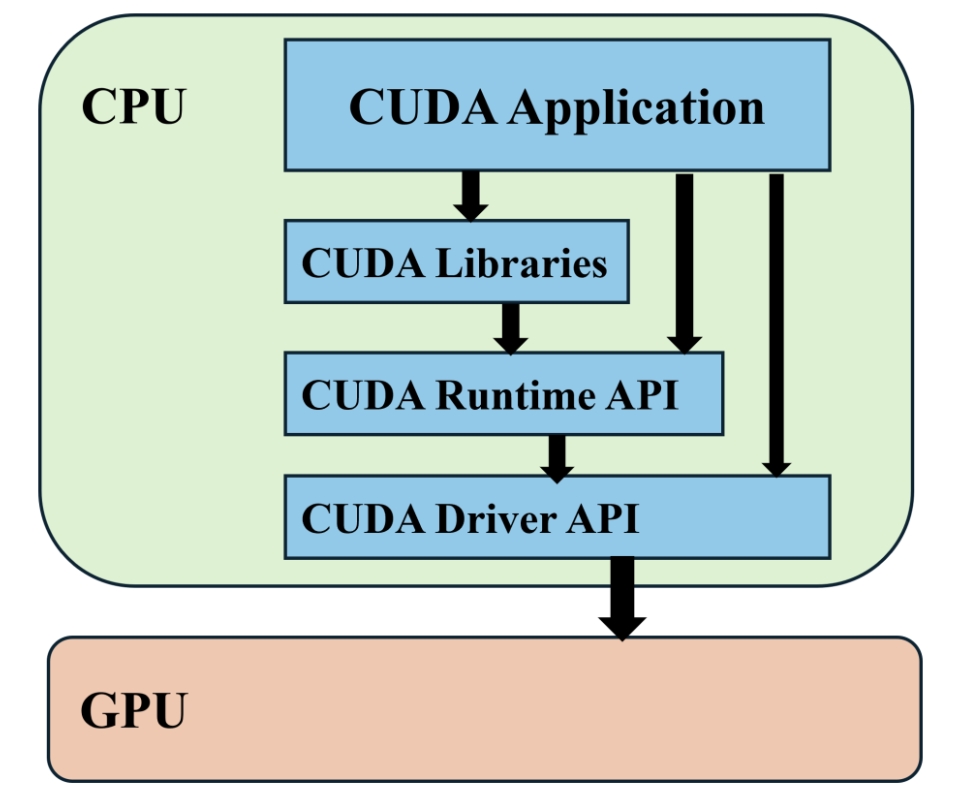
2024-10-01
CUDA容器化&Container runtime相关技术梳理
CUDA容器化&Container runtime相关技术梳理 整体结构 CUDA API体系 CUDA Driver API:GPU 设备的抽象层,通过一系列 API 直接操作 GPU 设备,性能好,但编程难度高(需要显式进行device初始化以及context管理等); CUDA Runtime API: 对 CUDA Driver API 进行一定封装,简化编程过程,降低开发难度; CUDA Libraries: 更高层的封装,包含一些成熟的高效函数库。 因此要实现 NVIDIA 容器化,也就是要让应用程序可以在容器内调用 CUDA API 来操作 GPU,一般来讲,就要使容器内应用程序内可调用 CUDA Runtime API 和 CUDA Libraries,容器内可使用 CUDA Driver 相关库。 NVIDIA CONTAINER TOOLKIT 具体结构 GPU 容器底层实现 GPU 容器相关概念 一些背景知识 什么是运行时?什么是高级运行时(high-level runtime)和低级运行时(low-level runtime): 参考:ht...

2024-09-05
两万字讲清楚:现在的AI产品有多难做?
两万字讲清楚:现在的AI产品有多难做? https://mp.weixin.qq.com/s/pMt_VMs6uq5wsPPscOyefA 这篇文章深入探讨了AI产品经理在处理大型AI模型时应该考虑的关键问题和机遇。 1. 关注API而非仅仅是产品 核心观点:产品经理应该深入理解大模型的API,因为这是模型能力的直接体现。产品的最终形态往往是API能力的延伸,但可能会因为各种工程限制而与API的能力有所差异。 实际意义:了解API的能力和限制可以帮助产品经理更准确地设计产品功能,避免过度依赖模型无法实现的功能。 2. AI与移动互联网的类比不恰当 核心观点:简单地将AI技术应用到所有应用中并不是一个有效策略。只有那些真正能够从AI中获得显著优势的应用才应该进行AI重构。 实际意义:这要求产品经理进行深入的需求分析和成本效益分析,以确定AI的投入是否真正值得。 3. 产品经理需要学会调用API 核心观点:产品经理应该具备直接与AI模型交互的能力,这有助于更好地理解模型的能力和局限。 实际意义:这种能力可以帮助产品经理在产品开发过程中做出更准确的决策,并能够快速迭代产品以适...
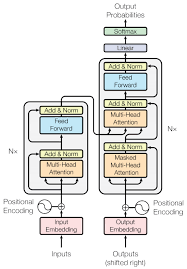
2024-09-05
Transformer解析
Transformer解析(Attention Is All You Need) 【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客 Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili 【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客 大模型面试准备(十二):深入剖析Transformer - 残差连接和层归一化_残差层和归一化层-CSDN博客 Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT-CSDN博客 “Attention Is All You Need” 是一篇由 Ashish Vaswani 等人撰写的论文,发表于 2017 年的 NeurIPS 会议上。这篇论文提出了 Transformer 模型,Transformer是一种用于自然语言处理(NLP)和其他序列到序列(sequence-to-sequence)任务的深度学习模型架构。Transformer架构引入了自注意力机制(self-attention mechanism),这是一个...
2024-09-05
大模型学习路线
大模型学习路线 现在门槛降低了,成本也降低了。大模型技术爆发,抓住机会。 开源大模型(离线,更安全)/在线大模型 微调:Lora->垂类 适用于用户意图识别 RAG:检索增强生成(一系列专家,提升表现幅度,降低幻觉) 只要提供了正确答案,大概率就不会答错 适合私有数据库 所以依赖于提供的数据库的信息,对数据质量要求比较高 推理更加缓慢(低于微调) 对知识库构建/信息压缩排名等(并非深度学习方面,需要深度学习算法工程师进行辅助) 提示词工程 【AI大模型】Prompt 提示词工程使用详解_大模型prompt的用法详解-CSDN博客 预训练:创造出属于自己的全新大模型 需要算力最多(微调其次,RAG和提示词工程对于算力的要求就没那么高) agent->担任80%脑力工作 一些课程 NLP FudanNLP/nlp-beginner: NLP上手教程 (github.com) 自然语言处理的入门练习 深度学习 跟李沐学AI的个人空间-跟李沐学AI个人主页-哔哩哔哩视频 (bilibili.com) 动手学深度学习 论文精读 https://...
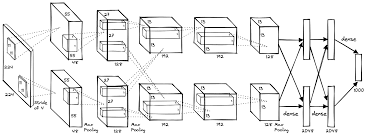
2024-09-10
AlexNet解析
AlexNet解析 卷积神经网络经典回顾之AlexNet - 知乎 (zhihu.com) AlexNet论文逐段精读【论文精读】_哔哩哔哩_bilibili 饱和:saturating 非饱和:non-saturating
评论




