AI资源调度
AI资源调度
100道k8s面试题:https://zhuanlan.zhihu.com/p/721588398
[云原生 AI 的资源调度和 AI 工作流引擎设计分享_paddleflow-CSDN博客](https://blog.csdn.net/lihui49/article/details/129260286?ops_request_misc={"request_id"%3A"81C8FAB8-41BA-4FDC-A5E5-B7EF5F69A9D0"%2C"scm"%3A"20140713.130102334.."}&request_id=81C8FAB8-41BA-4FDC-A5E5-B7EF5F69A9D0&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-3-129260286-null-null.142^v100^pc_search_result_base8&utm_term=AI 资源调度&spm=1018.2226.3001.4187)
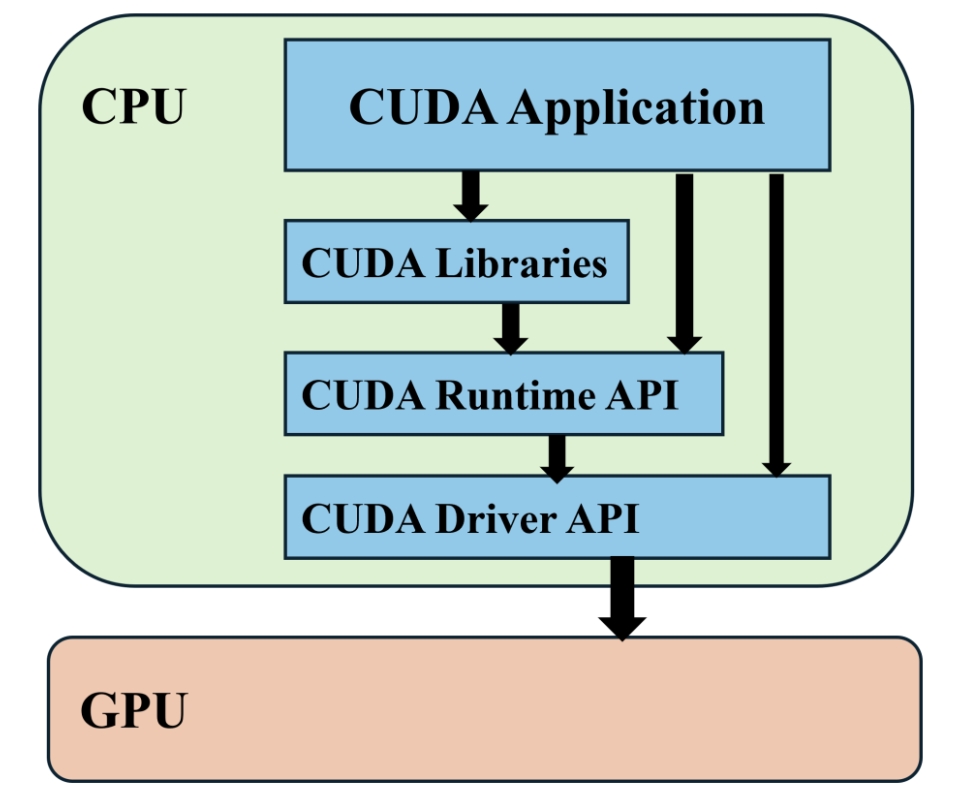
解密英伟达NVLink:解锁多GPU计算的无限潜力_nvidia nvlink-CSDN博客
https://arxiv.org/pdf/2402.15627.pdf
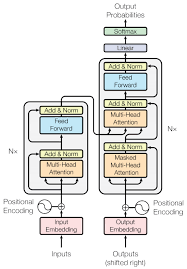
y = x+MLP(LN(x+Attention(LN(x))))
这个公式描述的是Transformer模型中的一个自注意力机制(Self-Attention)和前馈神经网络(Feed-Forward Neural Network, MLP)的组合。Transformer模型是自然语言处理领域中广泛使用的一种模型,它在处理序列数据时非常有效。这个公式可以分解为以下几个部分:
-
LN(x):这是Layer Normalization(层归一化)的缩写,它是一种归一化技术,用于稳定训练过程并提高模型性能。它对每个样本的特征进行归一化,而不是对整个批次进行归一化。
-
Attention(LN(x)):这是自注意力机制,它允许模型在序列的不同位置关注不同的信息。自注意力机制可以捕捉序列内部的长距离依赖关系,这对于理解文本的上下文非常重要。
-
MLP(LN(x+Attention(LN(x)))):这是一个前馈神经网络,它接收层归一化和自注意力机制的输出作为输入。MLP通常包含两个线性变换,中间可能有一个激活函数,如ReLU。这个MLP可以学习从自注意力机制中提取的复杂特征。
-
y = x + MLP(LN(x+Attention(LN(x)))):这是Transformer中的残差连接(Residual Connection)。在Transformer中,每个子层(如自注意力层和MLP层)的输出都会与子层的输入相加,然后进行层归一化。这种残差连接有助于避免在深层网络中出现的梯度消失问题,并且可以提高模型的性能。
总结来说,这个公式描述了Transformer模型中的一个关键操作,它结合了层归一化、自注意力机制和前馈神经网络,并通过残差连接来提高模型的稳定性和性能。
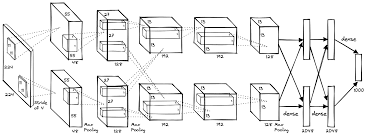
[一次讲清模型并行、数据并行、张量并行、流水线并行区别nn.DataParallel分布式]-CSDN博客