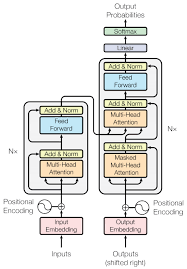
ResNet
ResNet
视频:ResNet论文逐段精读【论文精读】_哔哩哔哩_bilibili
为什么要使用3×3卷积?& 11卷积的作用是什么?& 对ResNet结构的一些理解_33卷积-CSDN博客
残差、方差、偏差、MSE均方误差、Bagging、Boosting、过拟合欠拟合和交叉验证-CSDN博客
深度学习——残差网络(ResNet)原理讲解+代码(pytroch)_残差神经网络-CSDN博客 :star:
快速理解卷积神经网络的输入输出尺寸问题_卷积神经网络输入和输出-CSDN博客
CNN基础知识——卷积(Convolution)、填充(Padding)、步长(Stride) - 知乎 (zhihu.com)
[ 图像分类 ] 经典网络模型4——ResNet 详解与复现-CSDN博客
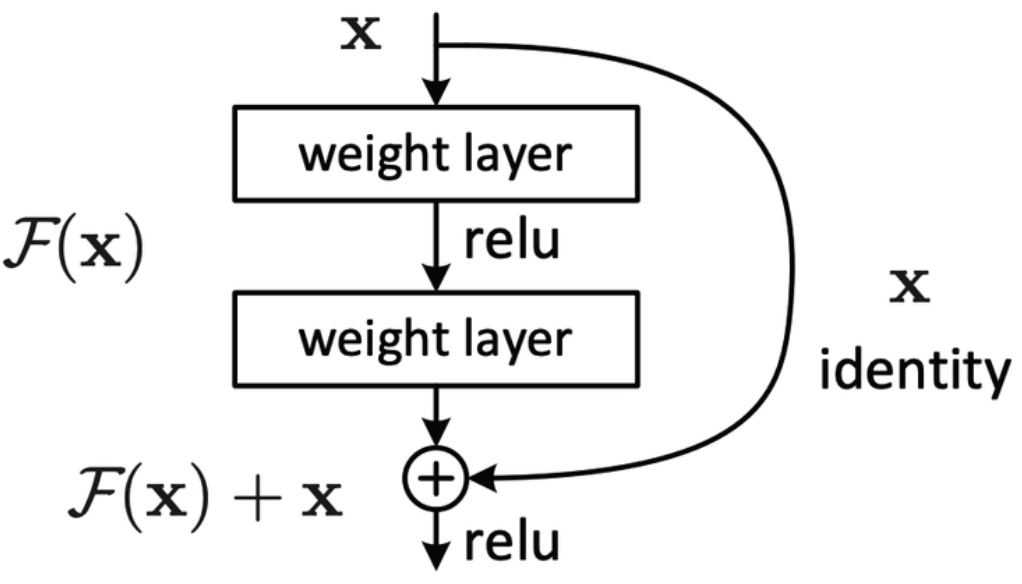
现象:更深的网络结构反而训练误差和测试误差都提升了!(梯度消失/梯度爆炸)
这里和overfiiting的区别是:过拟合是训练集上表现好,但测试集表现差,这里的现象是表现的都差,所以不是overfitting
加了ResNet之后,解决这个问题
Batch Normalizazion:具体的过程就是通过方法将该层的特征值分布重新拉回到标准正态分布(均值为0方差为1),特征值降落在激活函数对于输入较为敏感的区间,输入的小变化可导致损失函数较大的变化,使得梯度变大,避免梯度消失,同时也可加快收敛。
理解:
可以转换为学习一个残差函数:F(x) = H(x)- x,主要F(x)= 0 就构成了一个恒等变换,而且拟合残差肯定更容易。
F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是:
F(5)′=5.1
引入残差后是:H(5)=5.1,H(5.1)=F(5)+5,F(5)=0.1
这里的F′和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如S输出从5.1变到5.2,映射的输出F′增加了2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化。
至于为何shortcut(捷径)的输入是X,而不是X/2或是其他形式。作者的另一篇文章中探讨了这个问题,对以下6种结构(图2)的残差结构进行实验比较,shortcut是X/2的就是第二种,结果发现还是第一种效果好。(实验得出的结果)
输入输出:
-
填零(zero padding)
-
1*1卷积投影(在不增加感受野的情况下,让网络加深,进行数据的升维和降维)