CoRE-learning:Learnability with Time-Sharing Computational Resource Concerns
CoRE-learning:Learnability with Time-Sharing Computational Resource Concerns
https://doi.org/10.1093/nsr/nwae204
一般认为,人工智能机器学习技术应用涉及算法、数据、算力“三要素”。经典机器学习理论关注算法与数据对学习性能的影响,推导出的机器学习泛化误差界所包含的重要项通常涉及假设类复杂度和样本复杂度,两者分别与算法和数据有关,而对“三要素”中的算力缺乏考虑,尽管现实场景中算力资源的供给分配直接影响到最终学习性能。
在近期发表于《国家科学评论》(National Science Review, NSR)的Perspective文章中,南京大学周志华教授提出了“计算资源高效学习(CoRE-learning)”理论框架,这是第一个考虑了算力资源供给调度对机器学习性能影响的学习理论框架。
CoRE理论框架:
作者定义了“机器学习吞吐率”并引入了对资源动态分配调度策略的考虑,使得算力资源的供给分配对机器学习泛化性能的影响可以被抽象地在学习理论中进行研究,不仅有助于指导设计出高效使用算力资源的算法,还可望引导“智算中心”在为机器学习模型训练提供资源服务时从“独占式”转变为“分时式”,为能源的高效利用提供一个机器学习理论视角。
动机(Motivation):
- 传统机器学习理论通常假设有足够的甚至无限供应的计算资源来处理所有接收到的数据。然而,在实际应用中,如流学习,数据流可能是无限的,且数据量巨大,不可能及时处理所有数据。(这个问题通常不是机器学习领域考虑的问题)
- 现代“智能超级计算”设施通常以独占方式运行,用户被分配固定数量的资源来运行机器学习任务。这种方式可能过于乐观或悲观,导致资源分配不合理。这就有点像早期的计算机系统了。
- 机器学习理论应该考虑时间共享计算资源的问题,以提高用户效率和硬件效率,这一关键技术就是分时(time-sharing)。
- 目标:
- 用户效率角度:在一定时间预算内得到理想的模型结果。
- 硬件效率角度:计算资源被合理地利用。
工作内容(Work):
基于motivation,提出了“计算资源高效学习”(CoRE learning)的概念,并建立了一个理论框架。
定义
-
吞吐量:每秒可以传输的数据量/数据库中平均事务处理数量。
-
引入了机器学习吞吐量的概念,用于在抽象层面上理论化计算资源和调度的影响。:
-
数据吞吐量:表示每个时间单位内可以学习的数据百分比。
-
线程吞吐量:线程吞吐量表示在一段时间内可以很好地学习的线程的百分比。

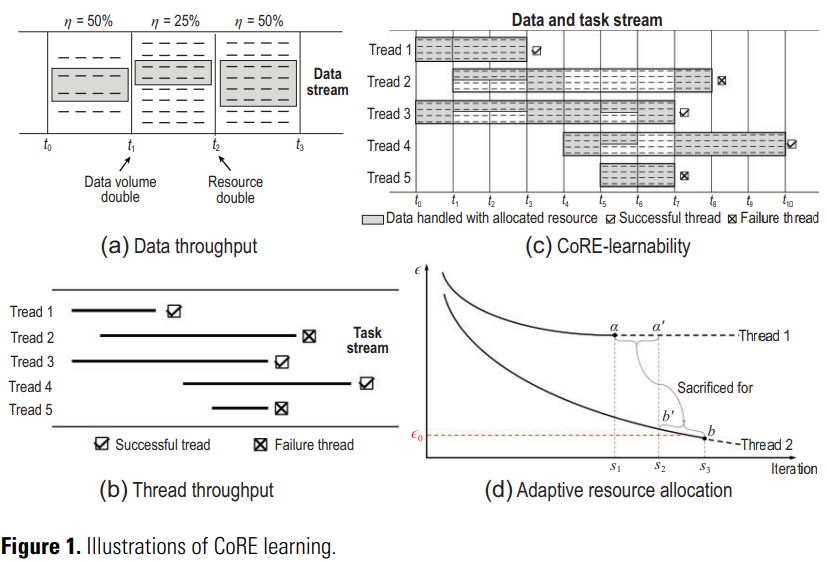
图1(a)为数据吞吐量,将这个概念引入机器学习研究:
- 数据量和计算资源预算的影响可以被涉及。
- 但并未考虑到从数据中学习的难度可能会发生变化的事实。
线程:计算设备接收到的机器学习任务。
- 生命周期:开始时间和截止/死亡时间(这里的截止时间是人为设置的)。
- 成功线程:时间跨度内能很好地学习,达到用户的要求。
- 失败线程:时间跨度内不能很好地学习,不能达到用户的要求。
线程吞吐量:由该时间段内所有线程中的成功线程百分比计算,如图1(b)线程吞吐量即为3/5=60%。
任务束(task bundle):相关时间段内的一组任务线程。
- 其中,Dk表示具有数据分布的线程,bk表示起始时间,dk是截止时间,Nt是在给定计算资源前提下在时间t时可以处理的数据量,K是任务束中的总线程数(总的任务数),T是总的时隙(time slots)数量。如果bi=bj (所有i≠j),则所有任务线程同时到达。
-
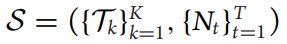
 ,Dk表示具有数据分布的线程,bk表示起始时间,dk是截止时间,Nt是在给定计算资源前提下在时间t时可以处理的数据量,K是任务束中的总线程数(总的任务数),T是总的时隙(time slots)数量。如果bi=bj (所有i≠j),则所有任务线程同时到达。
,Dk表示具有数据分布的线程,bk表示起始时间,dk是截止时间,Nt是在给定计算资源前提下在时间t时可以处理的数据量,K是任务束中的总线程数(总的任务数),T是总的时隙(time slots)数量。如果bi=bj (所有i≠j),则所有任务线程同时到达。Learning algorithm
学习算法:
输入:
输出: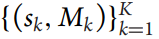
- sk为算法确定的切换时间。
- Mk为第k个线程的learned model。
用At表示在时间t时存活线程的集合:
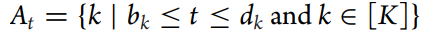
学习过程如下:
-
for循环:时间t=1,…,T,the learner
do:
- 最多收集 k,t,Nt 在 k ∈ At条件下的样本 , 其中 ηk,t为线程k在时间t的数据吞吐量。
- 为线程k更新模型Mk。
- 如果线程k完成,将sk设为t。
-
终止循环。
Definition 1 ((η, κ,L)-CoRE learnability):
现在引入CoRE learnability,其中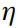 为数据吞吐量,
为数据吞吐量, 为线程吞吐量。
为线程吞吐量。

条件(1)涉及整个数据吞吐量,约束所有在当前时刻的alive set中的线程的总体资源配额永远不会超过最大资源预算。
条件(2)涉及线程吞吐量,要求调度策略ψ使L能够尽可能多地学习:
- 线程的学习应在截止时间前完成,如条件(2a)所示;
- 并且线程的学习性能应当在如条件(2b)所指示的小误差水平内。学习性能由来衡量,当算法利用时隙(bk,sk)中接收到的数据并在时间点sk之前完成学习时,根据预定的来评估学习性能是否可接受。
 来衡量,当算法利用时隙(bk,sk)中接收到的数据并在时间点sk之前完成学习时,
来衡量,当算法利用时隙(bk,sk)中接收到的数据并在时间点sk之前完成学习时, 根据预定的
根据预定的 来评估学习性能是否可接受。
来评估学习性能是否可接受。注意,条件(1)与用户效率有关,而条件(2)与硬件效率有关;调度策略应该谨慎地平衡这两个方面。
CoRE learnability定义使用了一种 类似可能近似正确的PAC学习理论。与PAC不同的是,CoRE learnability考虑了资源调度策略ψ的影响,并且对于具有(η,κ)吞吐量问题的学习算法L,仅要求可接受的。
类似可能近似正确的PAC学习理论。与PAC不同的是,CoRE learnability考虑了资源调度策略ψ的影响,并且对于具有(η,κ)吞吐量问题的学习算法L,仅要求可接受的。

算法流程举例说明:
图1©给出了一个图示,其中任务包由K=5个线程组成。为简单起见,假设在每个时间单位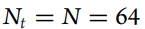 个数据单位可以处理。请注意,CoRE学习允许任务线程
个数据单位可以处理。请注意,CoRE学习允许任务线程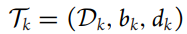 的开始时间sk和截止时间dk,为任何实际值,而在此图中,我们假设它们是四舍五入的,以便更好地说明。对于给定的算法L,任务束是**(0.5,0.6,L)-CoRE learnable的,因为存在一种调度策略ψ,使得在给定数据吞吐量η=50%**的情况下,工能够成功地学习5个线程中的3个。
的开始时间sk和截止时间dk,为任何实际值,而在此图中,我们假设它们是四舍五入的,以便更好地说明。对于给定的算法L,任务束是**(0.5,0.6,L)-CoRE learnable的,因为存在一种调度策略ψ,使得在给定数据吞吐量η=50%**的情况下,工能够成功地学习5个线程中的3个。
如图1c所示:
- ψ将能够处型ηN=32个数据单元的资源平等地在time slot处于t0-t1时分配给线程1和线程3,线程1继续接收可以处理16个数据单元的资源,直到在t3完成;剩余可以处理16个数据单元的资源在t1-t3中平均分配给线程2和线程3。
- 在t3-t4时,因为线程1不再需要任何资源,线程2和3每个都将分配到可以处理8个以上数据单元的资源。
- 线程4在t4到来,ψ对线程2感到悲观,所以把所有资源分配给线程3和线程4。
- 线程5在t5到来,由于线程5寿命很短,所以ψ给它分配了尽可能多的资源,直到在t7学习失败。
- 在t6,ψ对线程3非常乐观,因此决定暂时牺牲线程4将所有剩余的资源给线程3。
- 在t7,只有线程2和线程4还活着。
- 线程2和线程5失败的原因:线程2因为学习表现不理想,违反了条件2(b),而线程5没有在截止时间前完成,违反了条件2(a)。
关于调度策略ψ:
资源调度策略ψ能够根据对学习状态的感知和对线程学习进度的预测,自适应地分配资源。
直观地说,如果L是基于梯度计算的,那么为一个任务分配更多的计算资源意味着可以为该任务执行更多的梯度计算
-
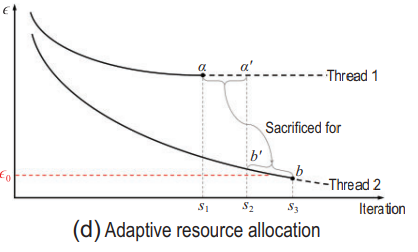
资源分配的动态性:在梯度下降算法中,如果一个任务线程(thread)进入了平坦的收敛区域,即错误率在过去几轮梯度计算中没有显著下降,而另一个线程进入了斜率区域,错误率下降更快,资源调度策略ψ会根据这些信息来调整资源分配。例如,在迭代τ1时,如果线程1进入了一个平坦的收敛区域,而线程2进入了斜率区域,ψ就会减少线程1的资源并重新分配给线程2。
-
资源调度的优化:资源调度策略ψ的目标是提高整体的吞吐量(throughput)。在图1(d)的示例中,假设两个任务线程最初被分配了相同数量的资源。通过动态调整资源分配,线程2可以在最终迭代τ3达到更好的状态b,而不是b’,而线程1则牺牲了达到a’的机会,达到了a。这导致整体吞吐量从0.0提高到0.5,即线程2根据阈值ϵ0被判定为成功。
-
资源调度的平衡:资源调度策略需要在探索和利用之间找到平衡。在机器学习过程中,可能需要在继续分配资源给当前表现不佳的任务线程(探索)和将资源重新分配给表现更好的任务线程(利用)之间做出选择。
-
资源调度的复杂性:机器学习中的资源调度与计算机系统和数据库中的资源调度不同。在计算机系统和数据库中,一旦任务接收到,完成该任务所需的资源量通常是已知的,而在机器学习中,这个信息是未知的,只能通过在线监视学习过程来估计。
-
在线治理和状态估计:在线治理和状态估计需要通信和计算资源,这增加了资源调度的复杂性。CoRE学习理论自然涉及到资源调度的探索-利用平衡。
-
CoRE学习理论的目标:CoRE学习理论的一个基本目标是通过引入调度,使机器学习的计算资源能够以时间共享的方式使用,而不是当前的难以捉摸的方式。这有助于减少资源浪费,并提高资源利用效率。
-
CoRE学习算法的证明:一旦开发出具体的CoRE学习算法,就可以证明其CoRE可学习性。
成果(Results):
- 论文提出了CoRE学习理论,该理论考虑了计算资源的调度策略,允许机器学习任务像计算机系统和数据库的时间共享技术一样运行。
- 通过定义CoRE可学习性,作者提供了一种评估学习算法在有限资源下性能的方法,包括数据吞吐量和线程吞吐量的限制条件。
结论(Conclusion):
- CoRE学习理论强调了在机器学习中考虑时间共享计算资源的重要性,目标是实现计算资源的高效利用,类似于计算机系统的时间共享技术。
- 通过引入调度策略,CoRE学习可以更好地平衡用户效率和硬件效率,提高机器学习任务的整体吞吐量。
- 论文指出,CoRE学习理论为机器学习中的资源调度提供了新的研究方向,包括如何在线有效地管理和估计机器学习过程的状态和进度。