深入理解分布式系统(五)分布式事务
分布式事务
5.1 什么是分布式事务
ACID:
- 原子性(Atomicity):一个事务被视为一个不可分割的最小工作单位,事务中的所有操作要么全部完成,要么全部撤销回滚,不允许出现部分完成的情况。
- 一致性(Consistency):事务开始前和结束后,数据库必须处于一致的状态,即事务执行后所得的结果必须符合预期的规定的结构和约束条件。
- 隔离性(Isolation):多个事务相互隔离不受干扰,每个事务只能“看到”其所执行的数据和其他事务已提交的数据,而看不到其他事务未提交的数据。
- 持久性(Durability):一个事务提交后,它对数据库的改变必须被永久保存到数据库中,即使出现断电等故障,其对数据库的改变也不能丢失。
分布式事务两种变体:
- 同一份数据需要在多个副本上更新,一个分布式事务需要更新所有的副本,如果有的节点提交了事务,有的节点回滚了事务,那么这样的结果对于用户来说是无法接受的。(可利用单主复制解决)
- 数据进行了分区,事务跨越多个节点,还要同时保证整体数据一致和事务的ACID属性。(常见且重点)
分布式事务通常不讨论ACID中的一致性。
想要实现持久性,只需在向客户端返回响应之前,确保将数据存储再非易失性存储设备即可,通常还会包括一些WAL或其他日志文件,虽然非易失性存储设备可能会损坏,但不考虑极端的情况,通过备份就可以解决该问题。、
原子性:原子提交(Atomic Commit)
隔离性:并发控制(Concurrency Control)(锁和MVCC)
5.2 原子提交
原子性的保证在分布式和单机系统中都很难。
方法:日志/WAL,可以回滚,撤销
分布式的原子性的实现:
- 原子提交协议(Atomic Commit Protocol)
- 协定性:所有的都同意一个值,那么所有进程要么一起提交事务,要么一起终止事务
- 有效性:如果所有进程都没问题,就提交,但凡有一个有问题,就终止
- 终止性:
- 弱终止条件:如果没有任何故障发生,那么所有进程最终都会作出决议
- 强终止条件:没有发生故障的进程最终会做出决议
5.2.1 两阶段提交协议
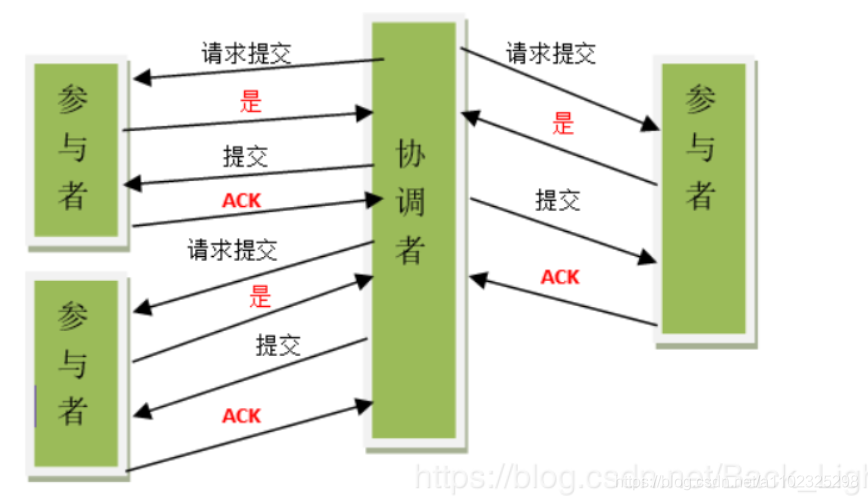
(443条消息) 两阶段提交协议(two phase commit protocol,2PC)详解_两阶段协议_延迟满足的博客-CSDN博客
两阶段协议存在的问题:
- 同步阻塞问题
- 单点故障问题
- 数据不一致问题
- 提交阶段不确定问题
基于 2PC 存在的问题,后来有人提出了三阶段提交协议,在其中引入超时的机制,将阶段 1 分解为两个阶段:在超时发生以前,系统处于不确定阶段;在超时发生以后,系统则转入确定阶段。
还有解决方法:Parallel Commits,第一阶段的结果已知(写入全局日志中),返回给客户端,异步执行第二阶段,该方法要跟共识算法一起工作。
5.2.2 三阶段提交
非阻塞协议,可以在协调者寄了的时候选出新的协调者推进事务执行
(443条消息) 三阶段提交协议(3PC)_愿好的博客-CSDN博客
缺点:并没有解决所有的问题。
- 可用性以正确性为代价,同时很容易收到网络分区的影响(导致脑裂选出多个协调者)
- 至少三轮往返消息,增加了事务的完成时间
满足强终止性
二阶段提交依然是
5.2.3 Paxos提交算法

5.2.4 基于Quorum的提交协议
每个节点有一票,总共V票:
- Vc:最小提交票数,要提交必须达到这个票数,0<Vc<=V
- Va:最小中止票数,要中止必须达到这个票数,0<Va<=V
Vc+Va>V
三个子协议:
- 提交协议:事务开始时使用(类似三阶段中的pre commit,但是需要等待Vc票数)
- 中止协议:网络分区时开始使用(出现网络分区,会在与协调者失联的分区中选出代理协调者,如果在失联分区中有在提交/中止状态(哪怕一个),都推进所有参与者到该状态;如果至少有一个参与者处于预提交状态,并且至少Vc个参与者在等待提交投票的结果,则代理协调者向所有参与者发送预提交消息,如果有超过Vc个参与者恢复响应,那么代理协调者就会发送真正的提交消息;如果没有处于准备提交状态的参与者,并且至少Va个参与者在等待中止事务的投票结果,那么代理协调者就会发送真正的中止消息)
- 合并协议:当系统从网络分区中恢复过来的时候使用
5.2.5 Saga事务
用来处理长活事务(Long-Lived Transaction,LLT)
(443条消息) 分布式事务系列:Saga_saga事务_码出钞能力的博客-CSDN博客
5.3 并发控制
悲观并发控制(Pessimistic Concurrency Control):假设多个事务之间会相互干扰,因此在任何时候都将资源加锁,避免其他事务修改该资源。悲观并发控制的主要优点是简单易懂,但由于频繁加锁导致效率低下,不适合高并发场景。
乐观并发控制(Optimistic Concurrency Control):假设多个事务之间不会相互干扰,并行访问数据,而在提交时进行冲突检测。如果两个事务的修改发生冲突,则其中一个事务必须回滚并重试。乐观并发控制可以最大程度地提高并发性,但需要开发人员自己实现数据版本控制,相对较为复杂。
多版本并发控制(Multi-Version Concurrency Control):每当一个事务对数据库进行更新操作时,会将当前数据的快照存储为新的版本,并使用版本号进行标识。在读取数据时,事务不会阻塞其他事务的读写操作,同时也不会锁定当前版本的数据。如果发现其他事务已经更新了数据,则会从前一个版本中获取数据。多版本并发控制的主要优点是高效、可扩展性好,但需要占用更多的磁盘空间。
5.3.1 两阶段锁
两阶段锁(Two-Phase Locking)是一种常用于并发控制的技术,旨在解决并发操作下出现的数据一致性问题。
在两阶段锁策略中,事务必须分为两个阶段:增长阶段和收缩阶段。
-
增长阶段:当事务请求资源时,该事务会先申请锁定所需资源。在此阶段中,锁可以被占用但不能被释放,每个事务只能逐渐获得锁,不能释放锁。
-
收缩阶段:当事务完成所需工作时,它将释放所有已经锁定的资源,并且这些锁不再被使用。在此阶段中,锁可以被释放但不能被继续占用,每个事务只能逐渐释放锁。
在这个过程中,锁的状态保持不变。所有的事务都必须遵循这些规则,以确保并发操作的正确性和一致性。
两阶段锁的优点是可以避免死锁的发生,但是也有一些缺点,例如可能会导致事务等待时间较长,从而影响系统的响应速度。此外,还有许多其他的并发控制技术,如乐观并发控制、基于时间戳的并发控制等,可以用于替代或补充两阶段锁。
三种方法避免死锁:
死锁是一种并发控制问题,指两个或多个事务或进程相互等待释放已经占用的资源,导致所有事务或进程都无法继续执行。为了避免死锁,可以采取以下几种方法:
- 死锁预防(破坏死锁条件):通过约定加锁顺序、引入超时机制、限制某些进程对资源的访问等方式,在程序设计时直接避免死锁发生。
- 死锁避免(银行家算法):通过安全序列算法对每个事务或进程的资源请求进行安全性检查,只有当该事务或进程的资源请求不会导致死锁时才会被允许。
- 等待-死亡:该方案是基于非剥夺方法。当进程Pi请求的资源正被进程Pj占有时,只有当Pi的时间戳比进程Pj的时间戳小时,Pi才能等待。否则Pi被卷回(roll-back),即死亡。
- 伤害-等待:它是一种基于剥夺的方法。当进程Pi请求的资源正被进程Pj占有时,只有当进程Pi的时间戳比进程Pj的时间戳大时,Pi才能等待。否则Pj被卷回(roll-back),即死亡。
- 死锁检测与恢复:在程序运行过程中,周期性地监测系统中是否发生了死锁,一旦检测到死锁,就采取资源抢夺或事务回滚等方式,进行死锁恢复。
以上三种方法可以单独或组合使用,以达到更好的死锁预防效果。同时,在程序设计时,应注意不要通过不合理的代码逻辑、数据库设计等导致死锁现象的出现。
5.3.2 乐观并发控制(不要锁)
两类,基于检查的并发控制和基于时间戳的并发控制。
-
基于检查的并发控制
- 读取:创建副本,放到私有空间,读是读的副本,写操作被记录到私有空间的临时文件中。
- 校验:没有冲突就提交,有冲突就中止。
- 写入:校验没问题,就把私有空间的数据持久化存储。
-
基于时间戳的并发控制
每个数据项有两个时间戳
-
写时间戳: W-TS(X)
-
读时间戳:R-TS(X)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#1.读操作
if TS(T_i) < W-TS(X){
abort(R_i(X))
}else{
accept(R_i(X))
R-TS(X)=TS(T_i)
}
#2.写操作
TS(T_i)必须大于R-TS(X)和W-TS(X),否则丢弃
if TS(T_i)<R-TS(X)||TS(T_i)<W-TS(X){
abort(W_i(X))
}else {
accept(W_i(X))
W-TS(X)=TS(T_i)
}难点:
- 时间戳的精确性
- 可能产生不可恢复的操作(后面的读事务基于前面的写事务,但前面的写事务回滚)
看起来没有锁,但是实际上在修改时间戳的时候,仍可能要获取锁
-
5.3.3 多版本并发控制(很像celldb啊)
可以看作在乐观并发控制的基础上增加了多个版本,为每个数据项存储多个版本
读到的是某个版本的数据,写是增加版本而并非覆盖
衍生出三种主流多版本并发控制:
- 多版本两阶段锁
- 多版本乐观并发控制
- 多版本时间戳排序
元数据(Tuple存储到数据项头部):
-
Tid:唯一单调递增的时间戳(事务开始的时间戳)
-
txn-id:获得当前写锁的事务的Tid,如果没有事务持有该数据的写锁,则为0,可通过CAS来修改此字段,避免使用锁
-
CAS,即 Compare-And-Swap,是一种原子操作,用于实现并发控制。在多线程编程中,CAS可以保证对共享变量的操作在多线程情况下能够正确地执行。
CAS操作需要三个参数:内存地址 V、旧的预期值 A 和新值 B。当且仅当当前内存地址的值等于旧的预期值 A 时,才会将该内存地址的值更新为新值 B。否则,不做任何操作。
CAS操作的基本流程如下:
- 线程读取内存地址 V 的当前值;
- 线程比较内存地址 V 的当前值与旧的预期值 A 是否相等;
- 如果相等,线程将新值 B 写入内存地址 V,并返回操作成功;
- 如果不相等,线程不做任何操作,并返回操作失败。
通过CAS操作,可以避免传统并发控制方法(如锁定)的一些问题,例如死锁和竞争条件。但同时,也存在一些限制。例如,CAS只能应用于单个变量的操作;如果需要对多个变量进行联合操作,则需要使用其他并发控制方式。
-
-
begin-ts: 创建该版本的数据项的事务提交的时间戳(开始肯定是提交了才有嘛),Tcommit
-
end-ts:最新版本的话,则为无限大,否则该数据项等于上一个或下一个版本数据项的begin-ts
-
多版本两阶段锁(这里的锁,是根据对于数据的元数据的版本来进行判断来实现的):
代表MySQL,Oracle,Postgres
-
txn-id
-
read-cnt:当前数据的读锁的数量。可以将read-cnt和txn-id组合成一个64位整型值,用CAS来更新两个
-
begin-ts
-
end-ts
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31#对于读操作Ti Xv为版本
find Xv where begin-ts(Xv) <= Ti <end-ts(Xv)
if txn-id(Xv)==0 || txn-id(Xv)==Ti{
read-cnt(Xv)+=1
accept(Read(Xv))
}else{
abort()and rollback(T)
}
#对于写操作 找到最新版本Xv
finx Xv where end-ts(Xv) ==INF
if txn-id(Xv)==0||txn-id(Xv)==Ti{
txn-id(Xv)=Ti
new(Xv+1)
txn-id(Xv+1)=Ti
accept(Write(Xv+1))
}else{
abort() and rollback(T)
}
#善后
#for write
for all write data item{
txn-id(Xv+1)=0
begin-ts(Xv+1)=Tcommit
end-ts(Xv+1)=INF
txn-id(Xv)=0
end-ts(Xv)=Tcommit
}
#for read
for all read data item{
read-cnt(Xv) -=1
}
-
-
多版本乐观并发控制
MemSQL用这个
Metadata:
- txn-id
- begin-ts
- end-ts
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32#读
find Xv where begin-ts(Xv)<= Ti < end-ts(Xv)
if txn-id(Xv)==0 || txn-id(Xv)==Ti{
accept(Read(Xv))
}else{
abort()and rollback(T)
}
#写
find Xv where end-ts(Xv) == INF //确保最新
if txn-id(Xv) == 0 || txn-id(Xv)==Ti{
txn-id(Xv) = Ti
new(Xv+1)
txn-id(Xv+1) = Ti
begin-ts(Xv+1) = INF
accept(Write(Xv+1))
}else{
abort() and rollback(T)
}
#提交事务
for all read data item{
if begin-ts(Xv) >Ti{
//数据项被其他事务修改过,读到了过期的数据
abort() and rollback(T)
}
}
for all write data item{
txn-id(Xv+1) = 0
begin-ts(Xv+1) = Tcommit
end-ts(Xv+1) = INF
txn-id(Xv) = 0
end-ts(Xv) = Tcommit
} -
多版本时间戳排序
-
txn-id
-
read-ts(最大的读过的事务的Tid)
-
begin-ts
-
end-ts
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27#读
find Xv where begin-ts(Xv)<=Ti<end-ts(Xv)
if txn-id(Xv) == 0 || txn-id(Xv) == Ti{
accept(read(Xv))
read-ts(Xv)=max(Ti,read-ts(xV))
}else{
abort() rollback(T)
}
#写
find Xv where end-ts(Xv) ==INF
if txn-id(Xv)=0&&Ti > read-ts(Xv){
txn-id(Xv) = Ti
new(Xv+1)
txn-id(Xv+1) =Ti
read-ts(Xv+1) = 0
accept(Write(Xv+1))
}else {
abort() and rollback(T)
}
#善后
for all write data item{
txn-id(Xv+1) = 0
begin-ts(Xv+1) = Ti
end-ts(Xv+1) = INF
txn-id(Xv) = 0
end-ts(Xv) = Ti
}
-
-
版本存储和垃圾回收
版本存储:
- 仅追加存储(Append-Only Storage)
- 有指针
- 如果说恰好有很大数据的一个属性,在新版本中又不发生改变,则很占空间(所以要复用)
- MemSQL、PG
- 时间旅行存储(Time-Travel Storage)
- 单独用一个时间旅行表来存储历史版本
- 最新版本的数据存储到主表
- 增量存储(Delta Storage)
- 只将发生变化的字段信息存储到增量存储中
- 增量存储在MySQL和Oracle中被称为回滚段
- 对于更新频繁的工作负载,可以减少内存分配,对于读操作频繁的工作负载,需要访问回滚段才能重新拼出需要的信息,开销会更高
垃圾回收:
- 元组级别(Tuple-Level Garbage Collection) :
- 后台清理(Background Vaccuuming, VAC):后台线程周期性清理:star2:
- 协同清理 (Cooperative Cleaning, COOP):遍历最老到最新,事务执行时清理
- 事务级别垃圾回收(Transaction-Level Garbage Collection):
- 如果一个事务创建的版本不被任何活跃事务访问,意味着该事务已经过期。
- 系统会根据该事务读写的数据集合(Read/Write Sets)清理相对应的版本
- 仅追加存储(Append-Only Storage)
5.4 Percolator
分布式事务解决方案:Percolator
构建于Bigtable的基础上,主要用于网页搜索索引等服务
支持多行事务
依赖一个单点授时,单时间源的授时服务(TSO,Timestamp Oracle)
使用多版本时间戳排序来实现快照隔离
利用如下元数据实现快照隔离:
- lock:锁信息
- write:事务提交时间戳
- data:数据
事务处理步骤:
-
分配事务开始时间戳:
1
start_ts=oracle.GetTimestamp()
-
将所有写操作缓冲起来,直到提交时再一并写入
1
2
3void set(Write w){
writes_.push_back(w)
} -
preWrite:
-
所有写操作挑选一个作为主锁(随意挑选,固定使用第一个写操作作为主锁):锁住事务中写操作涉及的所有数据
-
其他写操作作为次锁
1
2
3
4
5
6
7
8
9
10
11
12bool preWrite(Write w,Write primary){
Column c = w.col;
bigtable::Txn T = bigtable::StartRowTransaction(w.row);
//如果事务开始后该数据被修改,则中止事务
if (T.Read(w.row,c+"write",[start_ts,INF]))return false;
//尝试获取锁
if (T.Read(w.row,c+"lock",[0,INF]))return fasle;
T.Write(w.row,c+"data",start_ts,w.value);
T.Write(w.row,c+"lock",start_ts,{primary.row,primary.col});
return T.Commit();
}
-
-
提交事务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43#写
bool Commit(){
Write Primary = writes_[0];
vector<Write> secondaries(writes_.begin()+1,wirtes_.end());
if (!PreWrite(primary,primary))return false;
for (Write w:secondaries)
if (!PreWrite(w,parimary)) return false;
int commit_ts = oracle.GetTimestamp();
//先提交主锁的写操作
Write p = primary;
bigtable::Txn T= bigtable::StartRowTransaction(p.row);
if (!T.Read(p.row,p.col+"lock",[start_ts,start_ts]))
return false;
T.Write(p.row,p.col+"write",commit_ts,start_ts);
T.Erase(p.row,p.col+"lock",commit_ts);
if (!T.commit())return false;
//第二阶段,更新所有次(secondary)锁的写操作
for (Write w:secondaries){
bigtable::Write(w.row,w.rol+"write",commit_ts,start_ts);
bigtable::Erase(w.row,w.rol+"lock",commit_ts);
}
return true;
}
#读
bool Get(Row row,Column c,string *value){
while(true){
bigtable::Txn T = bigtable::StartRowTransaction(row);
//检查是否有并发写入的锁
if (T.Read(row,c+"lock",[0,start_ts])){
//存在锁,尝试清理并等待锁释放
BackoffAndMaybeCleanupLock(row,c);
Continue;
}
//找到小于开始时间戳的最新写入版本
latest_write=T.Read(row,c+"write",[0,start_ts]);
if (!latest_write.found()) return false; //没有找到
int data_ts =latest_write.start_timestamp();
*value = T.Read(row,c+"data",[data_ts,data_ts]);
return true;
}
}





